


李国杰院士:基于可判定性理论的人工智能系统安全风险分类
李国杰院士:基于可判定性理论的人工智能系统安全风险分类李国杰院士指出,AI安全风险应按逻辑复杂性分为三类:R1可验证、R2可发现但不可证明安全、R3不可治理。当前AI多属R2,关键不在「证明安全」,而在构建人类主导的制度性刹车机制,拒绝让渡终极控制权。
来自主题:
AI技术研报
9286 点击 2026-02-26 12:13
 搜索
搜索
李国杰院士指出,AI安全风险应按逻辑复杂性分为三类:R1可验证、R2可发现但不可证明安全、R3不可治理。当前AI多属R2,关键不在「证明安全」,而在构建人类主导的制度性刹车机制,拒绝让渡终极控制权。

近期发表于 TMLR 的论文《Large Language Model Reasoning Failures》对这一问题进行了系统性梳理。该研究并未围绕 “模型是否真正理解” 展开哲学层面的争论,而是采取更加务实的路径 —— 通过整理现有文献中的失败现象,构建统一框架,系统分析大语言模型的推理短板。

前天,MiniMax 更新了 MiniMax Agent,原先的专家 Agent 再度升级,这次还加了个新东西:MaxClaw —— 把最近在 GitHub 上爆火的 OpenClaw 做成了网页版,直接一键接入。

科技账号 Legit 率先披露,V4 的轻量版本代号为「sealion-lite(海狮轻量版)」,目前已在至少一家推理服务商处展开内测,相关方均签署了严格的保密协议。
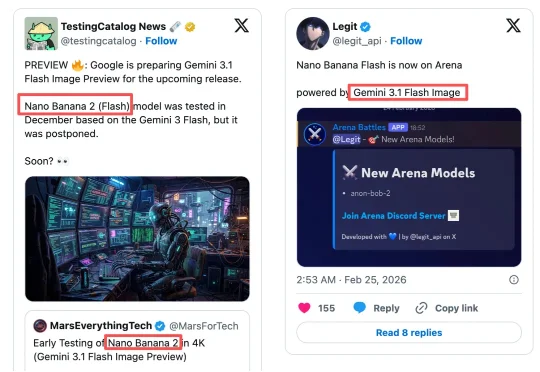
过去48小时,Nano Banana 2成为AI开发者圈的热议话题。在海外社交平台X上,关于谷歌这款最新图片生成模型(又名Gemini 3.1 Flash Image预览版)将发布的帖子层出不穷,4K图片四处流传,各种猜测也甚嚣尘上。

美国五角大楼正向 Anthropic 极限施压,要求彻底解除 Claude 的军事应用限制。会后,Anthropic 发布新版政策。公司正式放弃了「单方面暂停大模型训练」的安全承诺。在政治与商业的双重压力下,AI 安全理想主义最终向现实妥协。
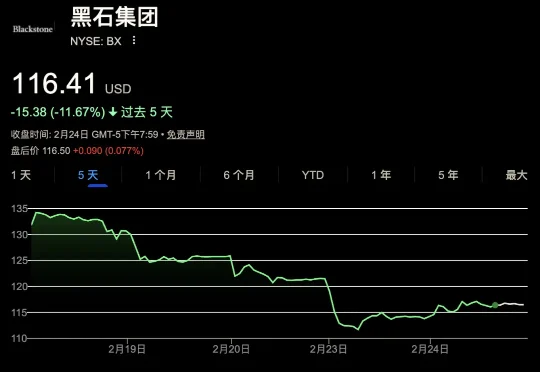
「software armageddon(软件末日)」——这是外媒描述过去几个月软件板块遭遇时用的词。Anthropic 每推出一个新工具,市场就会条件反射式地先问一遍:又有哪些软件要被干掉?然后果断抛售手里的股票。
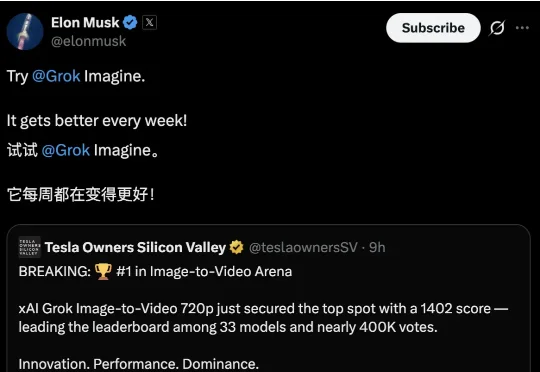
xAI的Grok图像转视频模型(grok-image-video-720p)登顶「Image-to-Video Arena」排行榜,以1404分的超高ELO评分力压群雄,位居第一。马斯克亲自发帖为自家Grok Image模型站台,称它每周都在迭代优化。

就在本月,蚂蚁集团inclusionAI团队交出了一份颇具分量的答卷——百灵大模型家族新一代开源万亿参数模型Ling-2.5-1T(即时模型)与Ring-2.5-1T(思考模型)。

不是,这才加入OpenAI几天啊,龙虾之父Peter Steinberger这波发言属实猛了些啊!在OpenAI的最新访谈中,他聊创业、聊OpenClaw、聊龙虾滥用和安全问题,那叫一个「实诚」。
随着AI即将抵达自我进化的AGI奇点和Agent泛滥的「AI繁荣」,一场更彻底的经济危机已经在迅速酝酿中:AI能力提升 → 裁员增加、工资降级 → 消费疲弱 → 企业利润被挤压 → 企业购买更多AI能力 → AI能力继续提升。所有平台层将被Agent彻底击穿,而房贷和私募基金将成为危机的加速器。
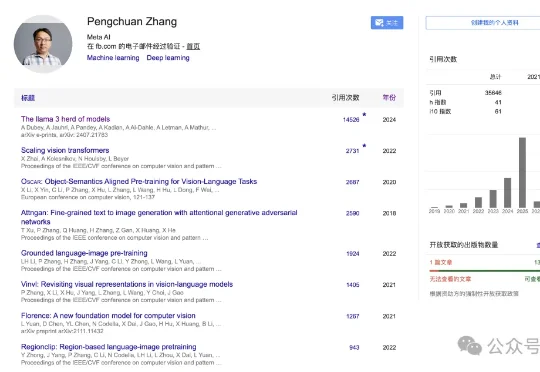
刚刚,毕业清华大学数学系,曾在Meta FAIR工作3.75年、主导过SAM与Llama多项核心工作的研究员张鹏川(Pengchuan Zhang)宣布离职。他的下一站,是来到OpenAI,投身于世界模拟与机器人学(World Simulation and Robotics)方向的研究。

硅谷曾是全球码农的「养老天堂」:下午四点的冲浪板、吃不完的零食、永远不响的手机。但到了2026年,这里只剩下一个身份:全球最昂贵的顶级血汗工厂。OpenAI和Anthropic的天才们正在用健康和家庭,给人类史上最贪婪的吞金兽——AGI,充当一次性燃料。
在他们看来,真正的胜负手不在于单点技能拉满,而在于能否在同一颗芯片里,把“训练级吞吐”和“推理级低延迟”同时做好——尤其是在长上下文、Agent循环这些更复杂的真实工作流中。
SSI-Bench是首个在约束流形中评估模型空间推理能力的基准,强调真实结构与约束条件,通过排序任务考察模型是否能准确理解三维结构的几何与拓扑关系,揭示当前大模型在空间智能上严重依赖2D信息,实际表现远低于人类。研究指出,模型需提升三维构型识别和约束推理能力,才能真正理解空间问题。
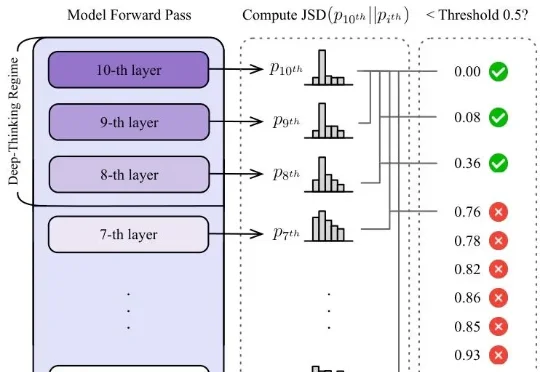
大模型的思维链越长,推理能力就越强?谷歌Say No——token数量和推理质量,真没啥正相关,因为token和token还不一样,有些纯凑数,深度思考token才真有用。新研究抛弃字数论,甩出衡量模型推理质量的全新标准DTR,专门揪模型是在真思考还是水字数。
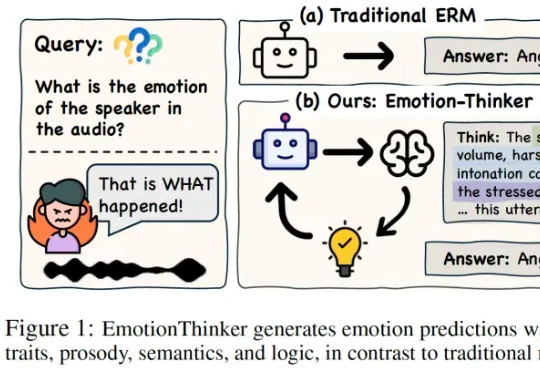
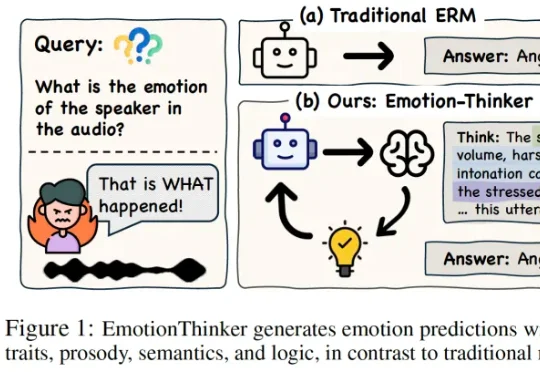
SpeechLLM 是否具备像人类一样解释 “为什么” 做出情绪判断的能力?为此,研究团队提出了EmotionThinker—— 首个面向可解释情感推理(Explainable Emotion Reasoning)的强化学习框架,尝试将 SER 从 “分类任务” 提升为 “多模态证据驱动的推理任务”。
开工第一天,我狠狠补了假期里认为最重要的一期播客:Notion 创始人 Ivan Zhao 的访谈。这期内容在互联网上几乎没有传播,但我认为它的价值被严重低估了。 Ivan 谈到了 AI 对 Noti
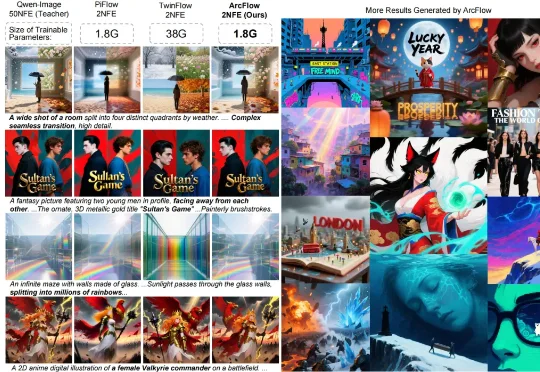
复旦大学与微软亚洲研究院带来的 ArcFlow 给出了答案:如果路是弯的,那就学会 “漂移”,而不是把路修直。在扩散模型中,教师模型(Pre-trained Teacher)的生成过程本质上是在高维空间中求解微分方程并进行多步积分。由于图像流形的复杂性,教师模型原本的采样轨迹通常是一条蜿蜒的曲线,其切线方向(即速度场)随时间步不断变化。

在2026当下的智能体(Agent)开发体系中,“为LLM加Skills”已经成为事实上的行业标准。您的Agent表现不好,是因为底层的LLM参数量不够,还是因为您喂给它的“Skills”写得一塌糊涂?无论是日常使用的各类CLI工具,还是最近的Openclaw,其底层能力的跃升很大程度上都依赖于这些特定领域的Agent Skills。

今日,宇树科技继春晚人形机器人“练武术”爆火出圈后,首次上新机器人产品——四足机器人Unitree As2。该产品定位一款轻量化的行业级四足机器人,与其消费级旗舰产品Unitree Go2体积差不多,但宇树称其“动力性能约等于Go2的两倍”。
Basis 将以 11.5 亿美元估值从投资者处募集 1 亿美元资金,公司计划于周二正式宣布。本轮融资由风险投资公司 Accel 领投,参投方包括 GV(原谷歌风投)、高盛集团前首席执行官劳埃德·布兰克费恩,以及现有投资机构科斯拉创投等。

Second Me 也是从这里出发的。他们在春节前的最后一周,把这个问题变成了一场大型实验,办了「Second Me 全球首届 A2A 黑客松」,300 多支团队来了。五天后,一个 Agent 互联网 APP Store 的雏形,出现了。

作为母公司 FansAI 发布的全球首个开放世界互动视频平台,Roto 背后的团队均来自硅谷大厂与国内顶尖科技公司,试图构建一个介于游戏与影视之间的新物种。

最近openclaw实在是太火了,连王慧文都发出英雄招募帖,看重虾实现AGI的潜力。然后紧接着就是 被openclaw作者Peter莫名下架、原因是官方用ASCII把中文判别成了乱码,于是平台把所有的中文Skill判定成虚假空技能,被动下架且无备份。。。连项目贡献者张昊阳的账号都封掉了。.... 这一波三折的剧情,电视剧都不敢这么拍。

DeepSeek员工节后一上班,美国AI圈又要抖三抖了(doge)。就从十几个小时前开始,DeepSeek的GitHub仓库突然一阵猛更新,Merge了一堆PR:维护者主要是mowentian——DeepSeekMoE等论文的署名作者之一Huang Panpan。他这一干活不要紧,大洋彼岸“V4来了???”的紧张神经,又被瞬间挑了起来。


上个月,我在 X 上刷到一个叫 Gabriel 的年轻人的故事。他从大学辍学,用 AI 自学人工智能,最终成为了 OpenAI 的研究员。真正吸引我的,是他在个人博客里分享的一套学习方法:「递归学习法」。
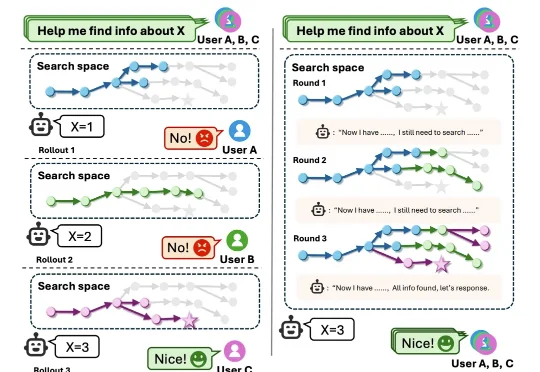
来自东南大学、微软亚洲研究院等机构的研究团队提出了一种全新的解决方案——Re-TRAC(REcursive TRAjectory Compression),这个框架让 AI 智能体能够「记住」每次探索的经验,在多个探索轨迹之间传递经验,实现渐进式的智能搜索。
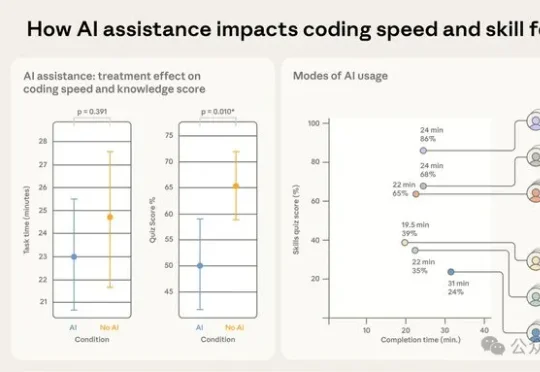
在AI编程时代,效率飙升却隐藏危机:Anthropic最新研究揭示,使用AI助手虽能快速生成代码,但开发者在概念理解、代码阅读和调试能力上显著落后。独立解决问题才是技能之钥,AI若不当用,将成「懒惰陷阱」。

