

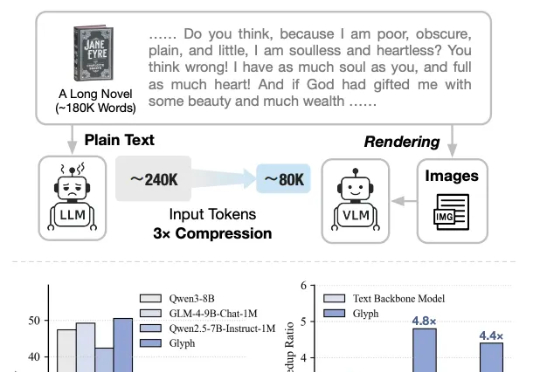
智谱运气是差一点点,视觉Token研究又和DeepSeek撞车了
智谱运气是差一点点,视觉Token研究又和DeepSeek撞车了太卷了,DeepSeek-OCR刚发布不到一天,智谱就开源了自家的视觉Token方案——Glyph。既然是同台对垒,那自然得请这两天疯狂点赞DeepSeek的卡帕西来鉴赏一下:
来自主题:
AI技术研报
9297 点击 2025-10-22 23:58
 搜索
搜索
太卷了,DeepSeek-OCR刚发布不到一天,智谱就开源了自家的视觉Token方案——Glyph。既然是同台对垒,那自然得请这两天疯狂点赞DeepSeek的卡帕西来鉴赏一下:

虽然浏览器 AI agent 的概念听起来很美好,但实际构建这样的系统却面临巨大挑战。这正是 Kernel 要解决的核心问题。我发现很多开发者想要构建 AI agent,但却在基础设施层面遇到了各种障碍:性能不稳定、运行时间不可靠、定价不合理、身份认证复杂、权限管理混乱,以及一个本来就不是为 agent 设计的互联网世界。

OpenAI前研究副总裁Liam Fedus与DeepMind材料科学领军者Ekin Cubuk共创Periodic Labs,以一轮高达3亿美元的种子融资走出隐身模式,震惊硅谷。然而,曾给出祝福的前东家OpenAI,并未参与本轮投资。

10月21日消息,据最新披露的文件显示,OpenAI正在秘密推进一项名为“水星项目”(Project Mercury)的绝密计划,已招募超过100名前投资银行家,协助训练AI系统构建复杂的金融模型,从而取代初级投行员工耗费大量时间的工作。

刚刚,这个开源的VLA一站式平台,不仅让UR5e真机实现了100%成功率,还在五大仿真环境中全面领先,最高性能提升高达46%,而且还支持RTX 4090训练!最近,由Dexmal 原力灵机重磅开源的Dexbotic,则构建了一个「VLA统一平台」。Dexbotic作为具身智能VLA模型一站式科研服务平台,可以为VLA科研提供基础设施,加速研究效率。

总部位于东京的人工智能开发商Sakana AI 正与美国和日本投资者洽谈,拟以 25 亿美元的估值融资 1 亿美元,较一年前一轮融资的估值上涨 66%。参与商谈的两位知情人士透露了这一消息。

ICCV最佳论文新鲜出炉了!今年,CMU团队满载而归,斩获最佳论文奖和最佳论文提名。同时,何恺明团队论文,RBG大神提出的Fast R-CNN,十年后斩获Helmholtz Prize,实至名归。
视频里,演员们穿着精致的戏服,在片场与工作人员互动、准备拍摄;摄影机、灯光、演员、助理,全都在忙。 就是这样一个 35 秒的「泄露」片段,在社交媒体上迅速疯传,YouTube 相关视频播放量破千万。
美国 AI 圈开始出现“担心中国开源断供”的苗头了吗?10 月 20 日,在专注于开源模型讨论、拥有 55 万成员的 Reddit 分论坛“r/LocalLLaMA”上,一位网友发布了一则“当中国公司停止提供开源模型时会发生什么?”的提问,并表达了假如中国模型逐渐闭源或开始收费该怎么办的担忧。
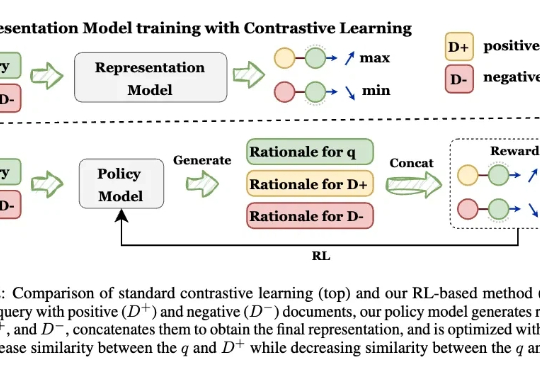
让模型先解释,再学Embedding! 来自UIUC、ANU、港科大、UW、TAMU等多所高校的研究人员,最新推出可解释的生成式Embedding框架——GRACE。过去几年,文本表征(Text Embedding)模型经历了从BERT到E5、GTE、LLM2Vec,Qwen-Embedding等不断演进的浪潮。这些模型将文本映射为向量空间,用于语义检索、聚类、问答匹配等任务。
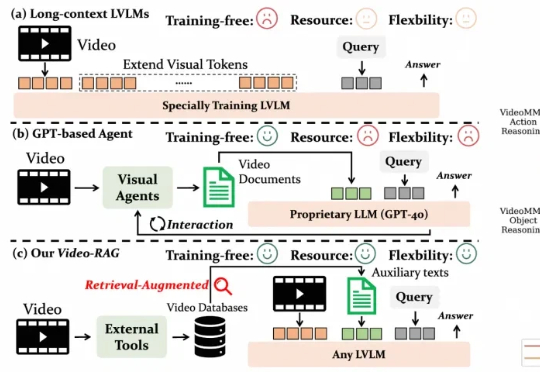
尽管视觉语言模型(LVLMs)在图像与短视频理解中已取得显著进展,但在处理长时序、复杂语义的视频内容时仍面临巨大挑战 —— 上下文长度限制、跨模态对齐困难、计算成本高昂等问题制约着其实际应用。针对这一难题,厦门大学、罗切斯特大学与南京大学联合提出了一种轻量高效、无需微调的创新框架 ——Video-RAG。
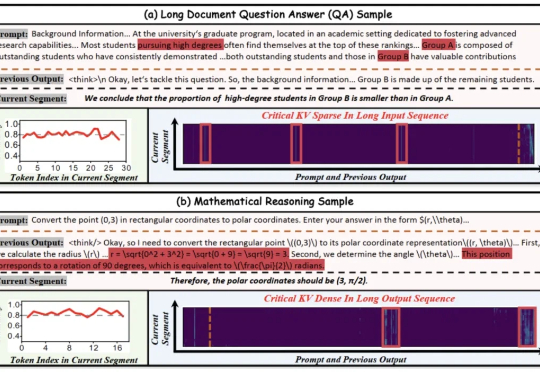
北大华为联手推出KV cache管理新方式,推理速度比前SOTA提升4.7倍! 大模型处理长序列时,KV cache的内存占用随序列长度线性增长,已成为制约模型部署的严峻瓶颈。
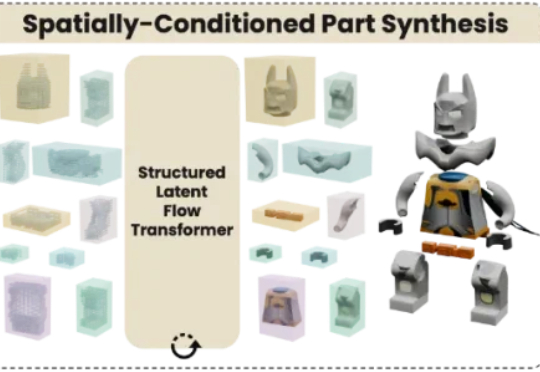
在3D内容创作领域,如何像玩乐高一样,自由生成、编辑和组合对象的各个部件,一直是一个核心挑战。香港大学、VAST、哈尔滨工业大学及浙江大学的研究者们联手,推出了一个名为 OmniPart 的全新框架,巧妙地解决了这一难题。该研究已被计算机图形学顶会 SIGGRAPH Asia 2025 接收。

传闻许久的 OpenAI AI Agent 浏览器,如今这个靴子终于正式落地。但 AI 浏览器已经是巨头新贵正在不断涌入的赛道,OpenAI 还未正式下场,就已经有了十足的火药味:预热推文评论区最高赞的评论,就是一名用户表示自己已经卸载了 Chrome,等待 Atlas,颇有点「打扫卫生再请客」的感觉。
在出海营销的赛道上,AI 已经成了人人必提的“标配”。在这股AI狂潮中,有一家成立仅一年的公司,悄悄跑出一条“反直觉”的增长曲线 —— DeepLink,这家创立于2024年的AI网红营销公司,已获得阿尔法、险峰长青、金沙江联合等多家一线机构投资,ARR突破500万美元。

美国签证体系,尤其在科技人才领域,长期被诟病为成本高、周期长、透明度低。前微软科学家Priyanka Kulkarni创办Casium,尝试用AI改造签证服务,把3–6个月的材料准备缩至10个工作日左右;部分案例不到1个月即可入职。
OpenAI正面临绝对的算力稀缺。

最近机器人和 AI 相关领域的读者或多或少都在关注 IROS。

游戏太多,玩家却不够了。这是海外科技媒体TechSpot在不久前发布的一篇文章中描述的情况,他们警告游戏行业可能会出现结构性错配。

尽管员工每天大部分时间都在项目中进行沟通与协作,但这一努力常因关键人员的缺席而受阻。当掌握重要信息的同事不在岗时——无论是休假还是处于不同时区,团队其他成员往往只能等待对方回复才能推进工作。
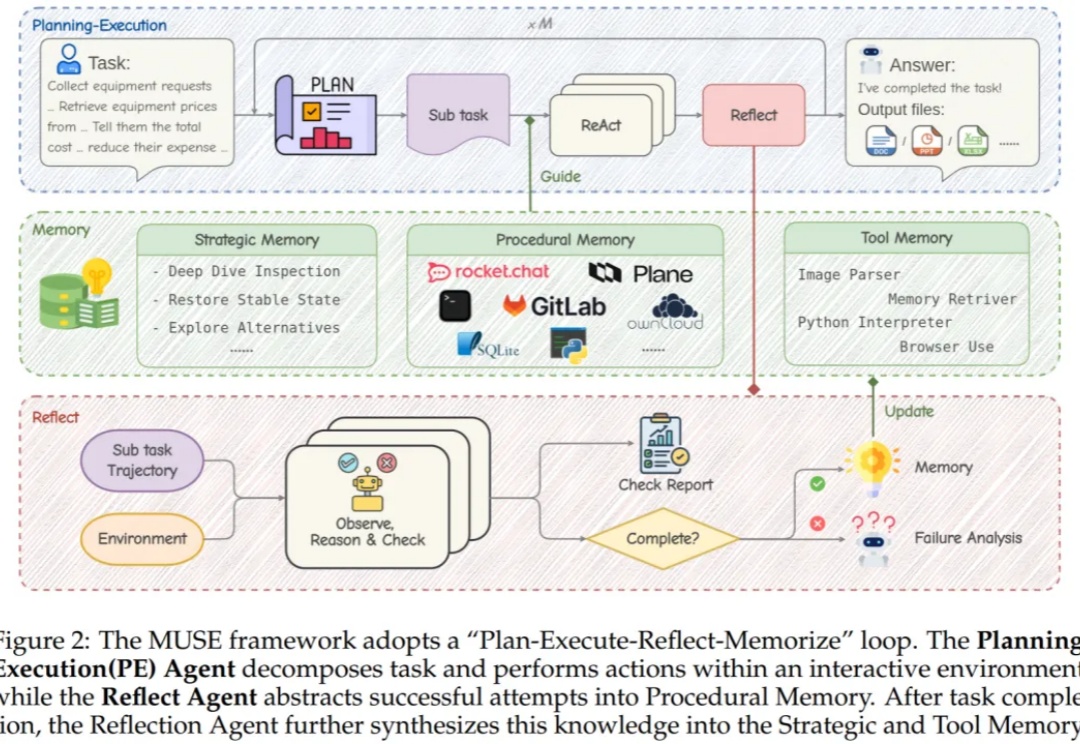
在人工智能的广阔世界里,我们早已习惯了LLM智能体在各种任务中大放异彩。但有没有那么一瞬间,你觉得这些AI“牛马”还是缺了点什么?
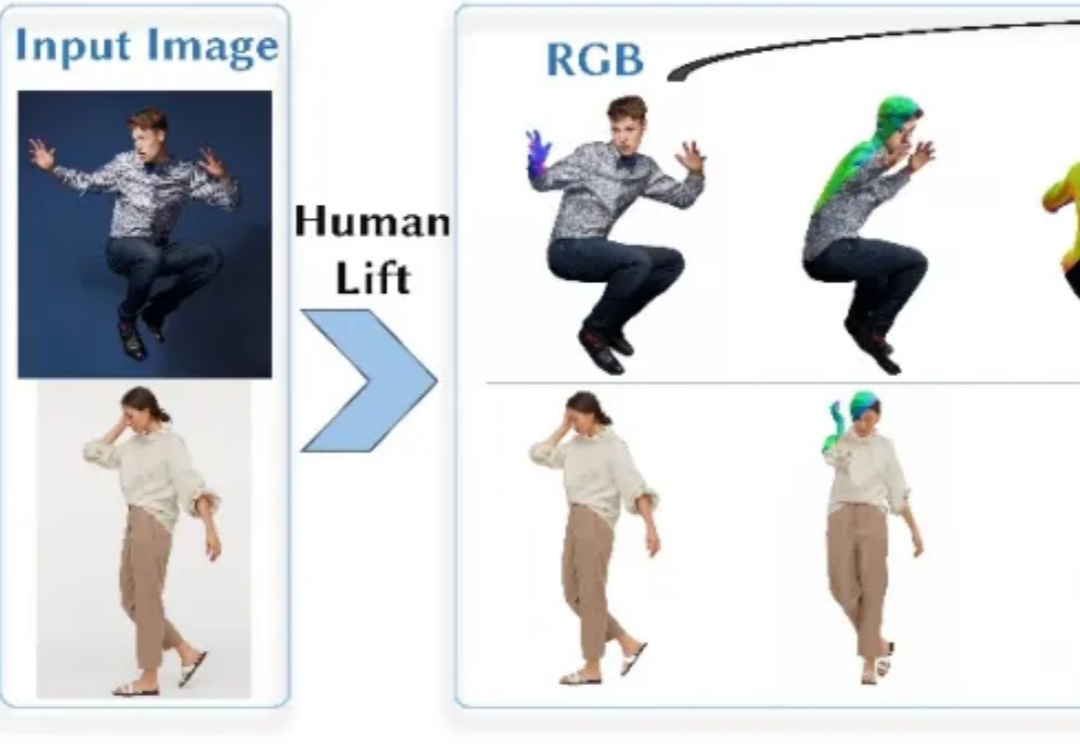
创建具有高度真实感的三维数字人,在三维影视制作、游戏开发以及虚拟/增强现实(VR/AR)等多个领域均有着广泛且重要的应用。
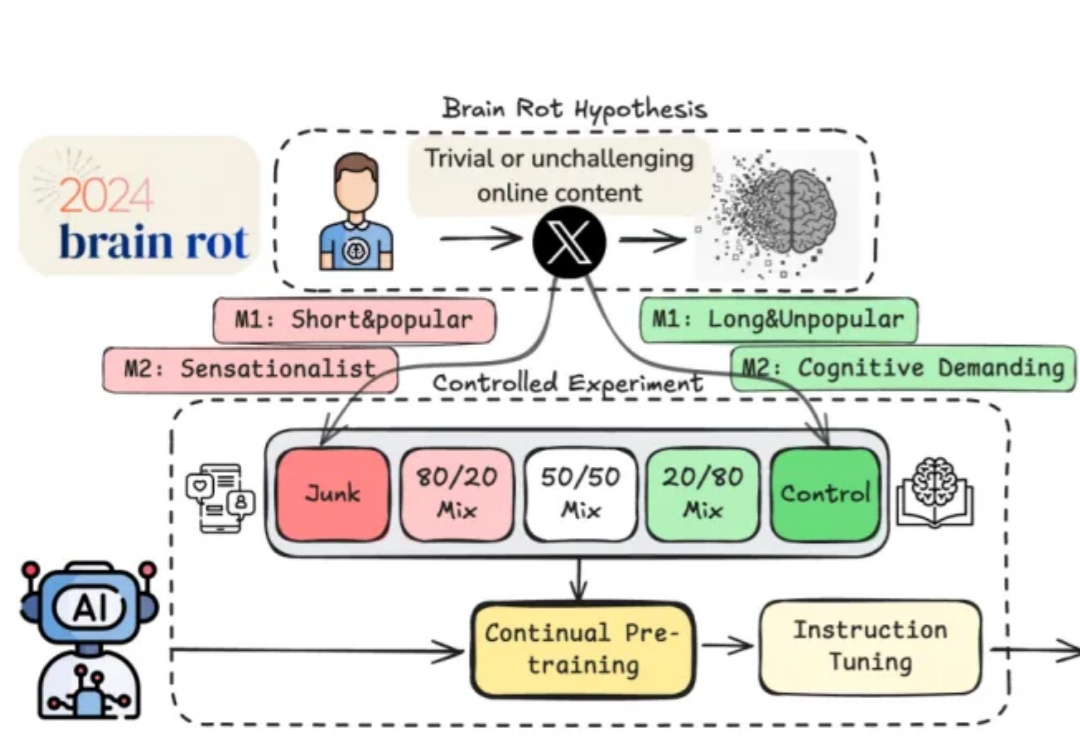
“脑腐”(Brain Rot)指的是接触了过多社交媒体的低质量、碎片化信息后,人类的精神和智力状态恶化,如同腐烂一般。它曾入选 2024 年牛津大学出版社年度热词。

DeepSeek最新开源的模型,已经被硅谷夸疯了!
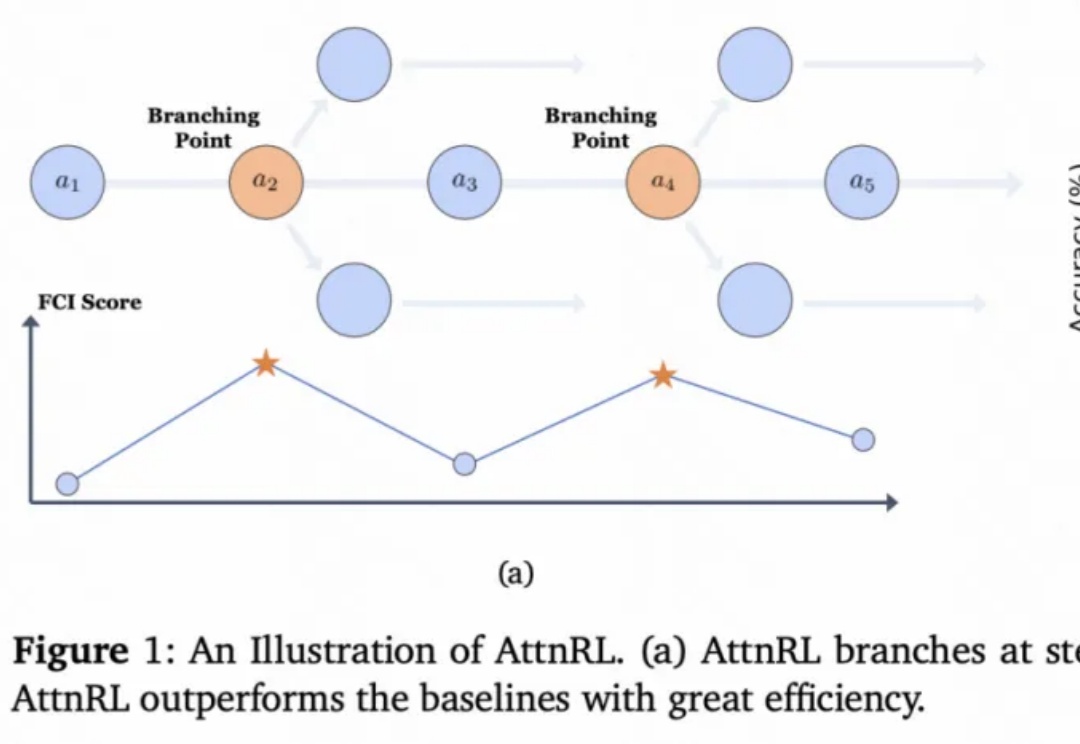
从 AlphaGo 战胜人类棋手,到 GPT 系列展现出惊人的推理与语言能力,强化学习(Reinforcement Learning, RL)一直是让机器「学会思考」的关键驱动力。

UC Berkeley、UW、AI2 等机构联合团队最新工作提出:在恰当的训练范式下,强化学习(RL)不仅能「打磨」已有能力,更能逼出「全新算法」级的推理模式。他们构建了一个专门验证这一命题的测试框架 DELTA,并观察到从「零奖励」到接近100%突破式跃迁的「RL grokking」现象。
昨天晚上闲着没事,想在 DeepSeek 搜一下 AI 博主有哪些可以学习的。 结果没想到,搜索结果里竟然出现了我自己。 内心 OS:祖坟冒青烟了,妈妈我出息了,我被 AI 认证了,以后简历可以写被
昨天刚发了飞书多维表格的使用教程,没想到,反响非常不错。 数据都非常的好,被转发了4500多次。。。 然后有很多朋友在下面评论,除了让我写爬虫教程之外,就是问,飞书除了多维表格之外,还有什么牛逼的用法

你还在依赖 SEO 和社交媒体为产品导流吗?这些传统增长驱动可能面临失效的困境了。我最近听了一场让我震惊的演讲,来自 Lovable 的增长负责人 Elena Verna。她用一组数据直接把现实摆在我
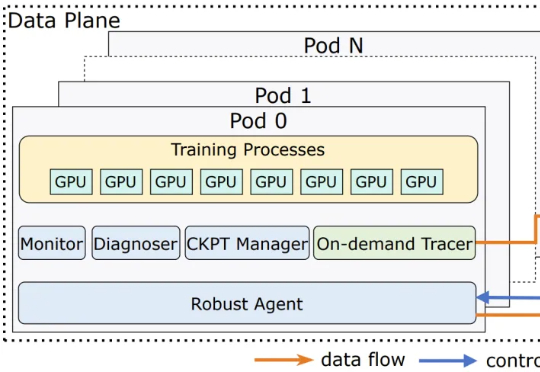
近日,字节跳动一篇论文介绍了他们 LLM 训练基础设施 ByteRobust,引发广泛关注。现在,在训练基础设施层面上,我们终于知道字节跳动会如何稳健地训练豆包了。

