

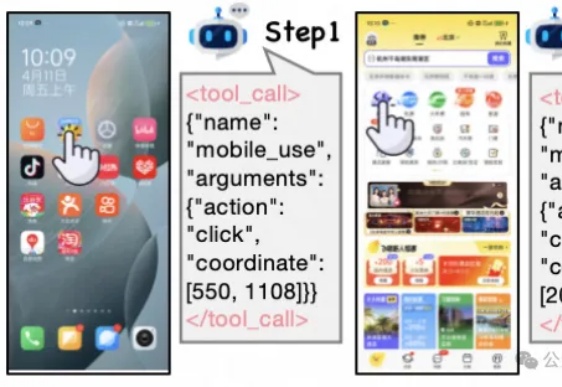
任务级奖励提升App Agent思考力,淘天提出Mobile-R1,3B模型可超32B
任务级奖励提升App Agent思考力,淘天提出Mobile-R1,3B模型可超32B现有Mobile/APP Agent的工作可以适应实时环境,并执行动作,但由于它们大部分都仅依赖于动作级奖励(SFT或RL)。
来自主题:
AI技术研报
11815 点击 2025-07-21 12:25
 搜索
搜索
现有Mobile/APP Agent的工作可以适应实时环境,并执行动作,但由于它们大部分都仅依赖于动作级奖励(SFT或RL)。

近日,月之暗面(Moonshot AI)正式发布了其万亿参数开源大模型Kimi K2,这一具有里程碑意义的AI模型凭借其创新的MoE架构和强大的Agentic能力迅速获得全球开发者关注。然而,随着用户量激增,部分开发者开始反映其API服务响应速度不尽如人意。面对这一情况,月之暗面于7月15日迅速作出官方回应,坦诚当前服务延迟问题,并详细说明了优化方案。
向企业销售软件是一个极其耗时的过程。即便客户已确信某款产品适合其组织,他们仍需确保该软件满足所有安全要求。

Kimi 又火了,在 DeepSeek 的热闹中沉寂大半年后,Kimi K2 悄悄在 LMArena 竞技场中从 DeepSeek 手中,夺过了全球开源第一的宝座。
你有没有想过,传统的销售模式可能真的完蛋了?我最近一直在思考这个问题。那种疯狂招聘销售人员、购买海量客户数据、发送铺天盖地邮件的增长策略,正在迅速失效。转化率在下降,销售配额越来越难完成,销售团队开始质疑一个根本问题:这套方法还管用吗?

近日,生物技术公司Pathos AI宣布完成3.65亿美元的D轮融资,融资后估值约为16亿美元。本轮资金将用于支持公司临床阶段产品线的推进,并持续投资于其专为肿瘤学构建的专有人工智能基础模型。
英伟达GPU,被白帽黑客发现了严重漏洞。
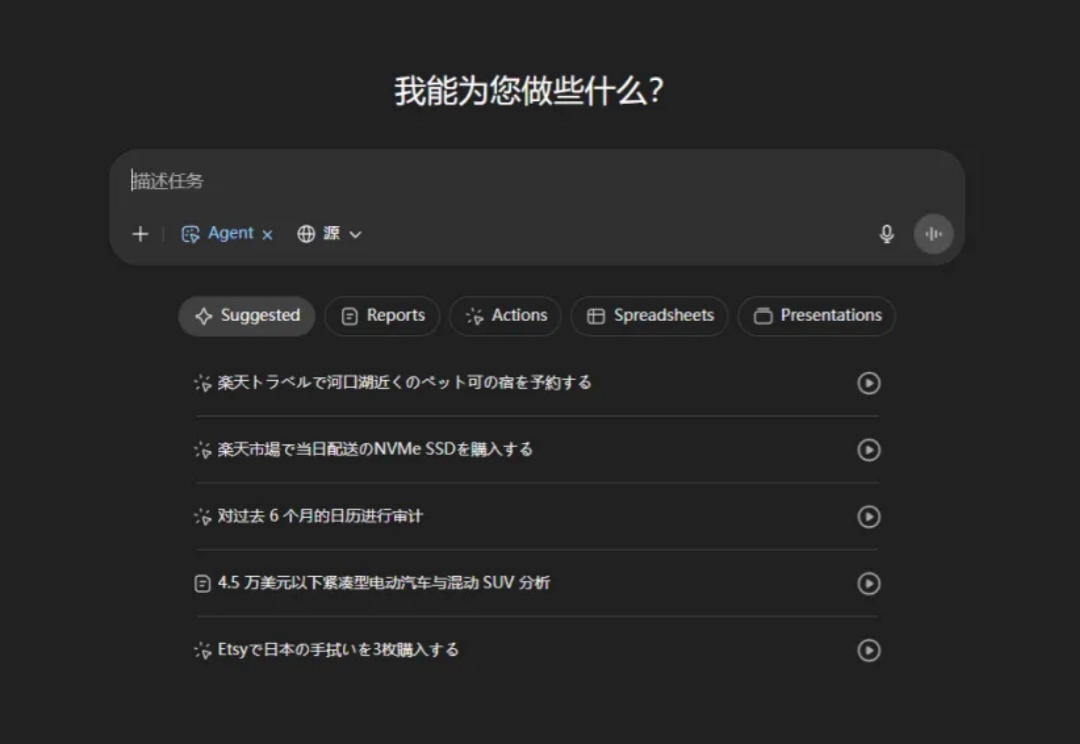
上周五,ChatGPT Agent mode上线了。

做海外社媒运营,可能会陷入这样一个“怪圈”?
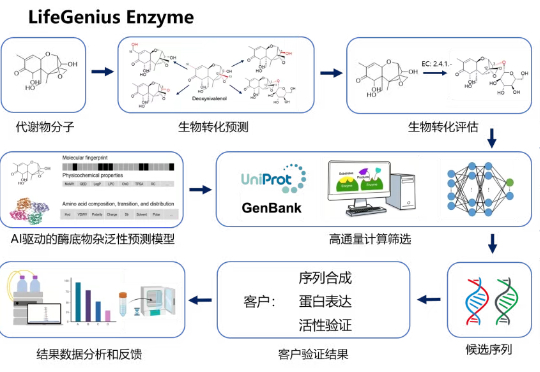
AI合成生物有用吗?究竟用在哪? 近日,美国头部市场咨询公司Lux Research发表了一篇名为《AI in Synthetic Biology: Necessary or Nice to Have?》的文章。

封建迷信不屑一顾,星座预测每周必读。

作为一个 AI 科技媒体编辑,AI 已经成为我的第一生产力。总结、翻译、查资料、做 PPT,一堆 AI 牛马任我差遣。

Claude Code 出来之后,很多人都在说“一个人 + AI 就可以独立写应用了”。

LLM太谄媚! 就算你胡乱质疑它的答案,强如GPT-4o这类大模型也有可能立即改口。

你是否有过这样的想法: 开发一个存钱管理工具来掌控财务状况。 开发一个感知声音的拍照APP,大喊“茄子”或“嚯哗”就能自动拍照。

AlphaFold夺诺奖引争议!2016年,一位博士生在NeurIPS提出的研究,或许正是AlphaFold的「原型」。如今,导师Daniel Cremers发声,质问为何DeepMind忽略这项研究、不加以引用?

一场突如其来的AI人才争夺战!从神秘会议闪电跳槽,谷歌如何用翻倍薪资和24亿美金协议,瞬间挖走Windsurf顶尖团队?

具身这么火,面向具身场景的生成式渲染器也来了。 中科院自动化所张兆翔教授团队研发的TC-Light,能够对具身训练任务中复杂和剧烈运动的长视频序列进行逼真的光照与纹理重渲染,同时具备良好的时序一致性和低计算成本开销。
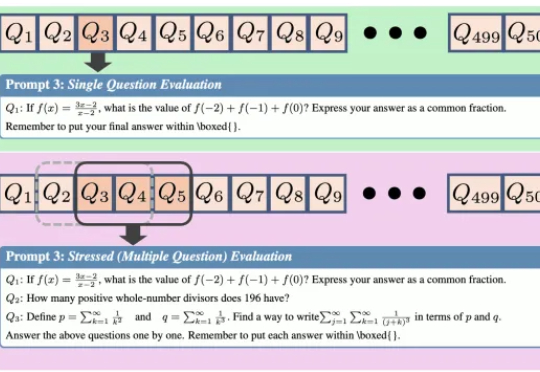
给AI一场压力测试,结果性能暴跌近30%。 来自上海人工智能实验室、清华大学和中国人民大学的研究团队设计了一个全新的“压力测试”框架——REST (Reasoning Evaluation through Simultaneous Testing)。

最近测Agent测的非常上头, 而且越来越发现AI在各种专门的领域的垂直能力发展的越来越好了。

7月2日,一个跨国团队在Nature杂志发表了一项开创性研究,宣称其推出的AI系统能够“模拟人类心智”。该系统在实验中可以“扮演”人类,生成逼真的人类行为。

今年 5 月,有研究者发现 OpenAI 的模型 o3 拒绝听从人的指令,不愿意关闭自己,甚至通过篡改代码避免自动关闭。类似事件还有,当测试人员暗示将用新系统替换 Claude Opus 4 模型时,模型竟然主动威胁程序员,说如果你换掉我,我就把你的个人隐私放在网上,以阻止自己被替代。

7 月 16 日,新一代作业帮AI学习机——P50 正式发布,重磅推出「AI 超级老师」功能,代表着学习机行业迈入「超级智能体」时代。

现有视频异常检测(Video Anomaly Detection, VAD)方法中,有监督方法依赖大量领域内训练数据,对未见过的异常场景泛化能力薄弱;而无需训练的方法虽借助大语言模型(LLMs)的世界知识实现检测,但存在细粒度视觉时序定位不足、事件理解不连贯、模型参数冗余等问题。

大模型有苦恼,记性太好,无法忘记旧记忆,也区分不出新记忆!基于工作记忆的认知测试显示,LLM的上下文检索存在局限。在一项人类稳定保持高正确率的简单检索任务中,模型几乎一定会混淆无效信息与正确答案。

据外媒报道,北约近期完成首次由人工智能(AI)主导的防空测试。结果显示,AI系统在预警时效、信息处理和拦截效率等方面的表现,均优于同等条件下的人工操作。分析人士表示,近段时间以来,北约成员国在AI军事化应用领域动作频繁,相关动向值得关注。

OpenAI最新模型曝光了,在2025年国际数学奥林匹克竞赛(IMO)上达到了金牌水平!IMO被公认为全球最顶尖的数学竞赛,每年只有不到8%的参赛者能够获得金牌。而现在,一个AI模型做到了。

基于Qwen2.5架构,采用DeepSeek-R1-0528生成数据,英伟达推出的OpenReasoning-Nemotron模型,以超强推理能力突破数学、科学、代码任务,在多个基准测试中创下新纪录!数学上,更是超越了o3!

理想汽车车载大模型荣获由CCIA汽车网络安全工作委员会颁发的《生成内容安全测评证书》,及人工智能生成合成内容标识服务平台颁发的《生成合成内容标识报告》,成为国内首批通过GB/T 45654、GB 45438-2025双国标认证的车企
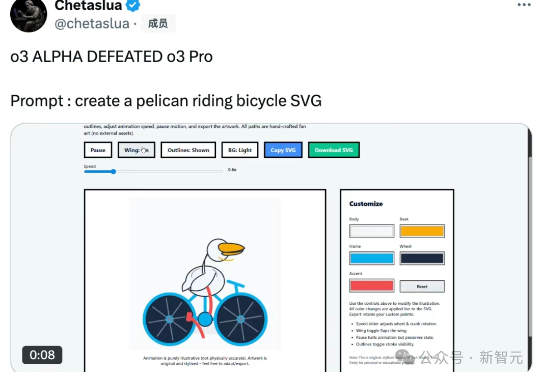
OpenAI的神秘模型o3-alpha意外曝光,其强大的代码能力碾压众多AI。该模型疑似在东京AtCoder世界编程大赛2025中夺得亚军,最终不敌人类选手Psyho。

