# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
全球大模型的军备竞赛,正在“智商”之外开辟新的战场——
推理速度。
把这个战场抬到新高度的,是小米。
小米发布了全新的MiMo-V2.5-Pro-UltraSpeed模型,也就是MiMo-V2.5-Pro的高速版本。
它拥有1T总参数,支持1M上下文,单API推理速度直接拉到1000+ TPS,刷新旗舰模型全球最快推理速度。
而且不像Groq那样依靠定制芯片,用通用GPU就能实现。
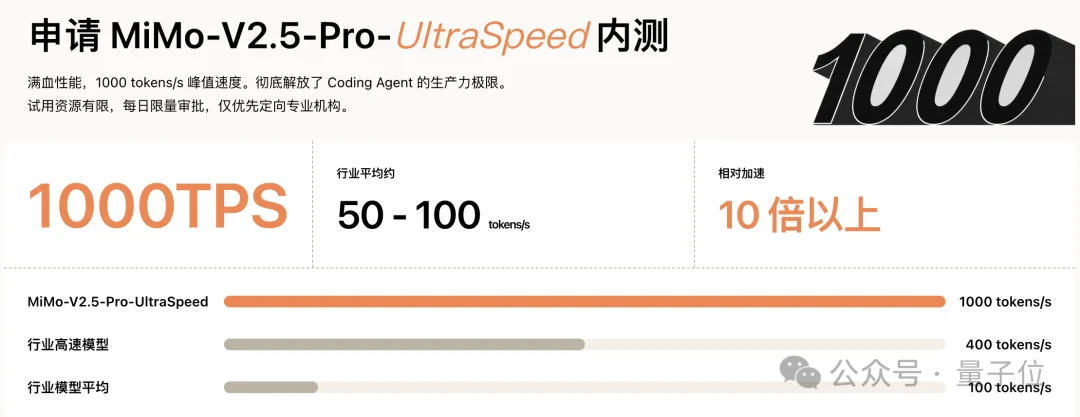
这也意味着,小米这次的新模型,打破了“快、强、通用GPU无法兼得”的行业不可能三角。小米秀出的是从模型层到引擎层的全链路推理优化能力,而背后的推理工程实力,毫无疑问是全球第一梯队水平。
这次,量子位也拿到了MiMo-V2.5-Pro-UltraSpeed的测试资格,到底有没有这么快,接下来一起看看。
先看看MiMo-V2.5-Pro-UltraSpeed能不能生成一个完整的Web应用出来。
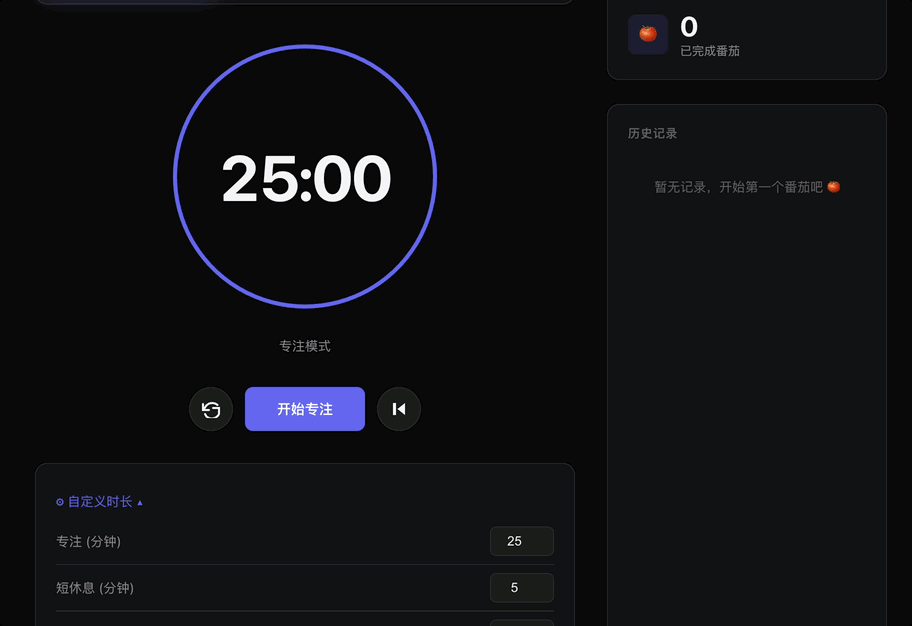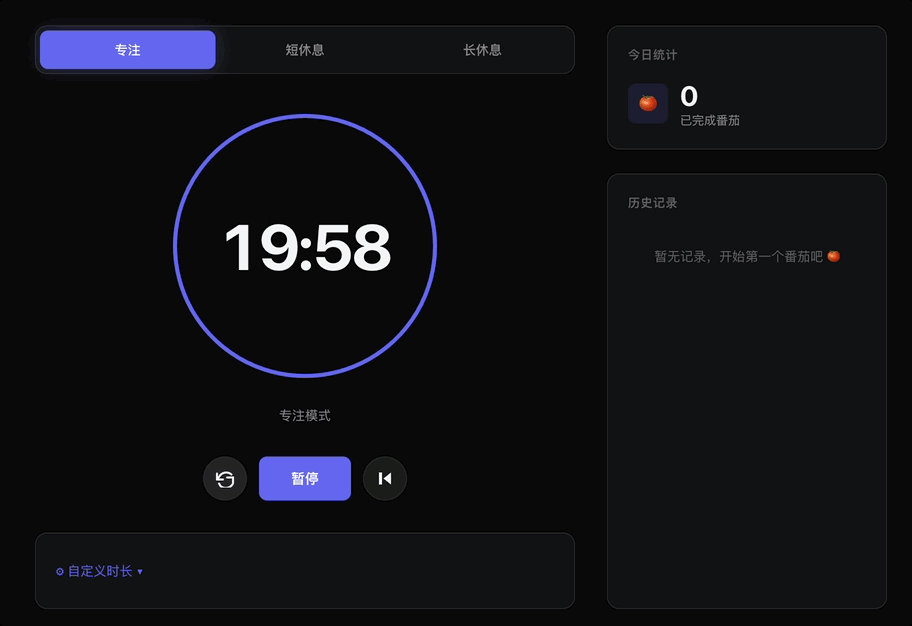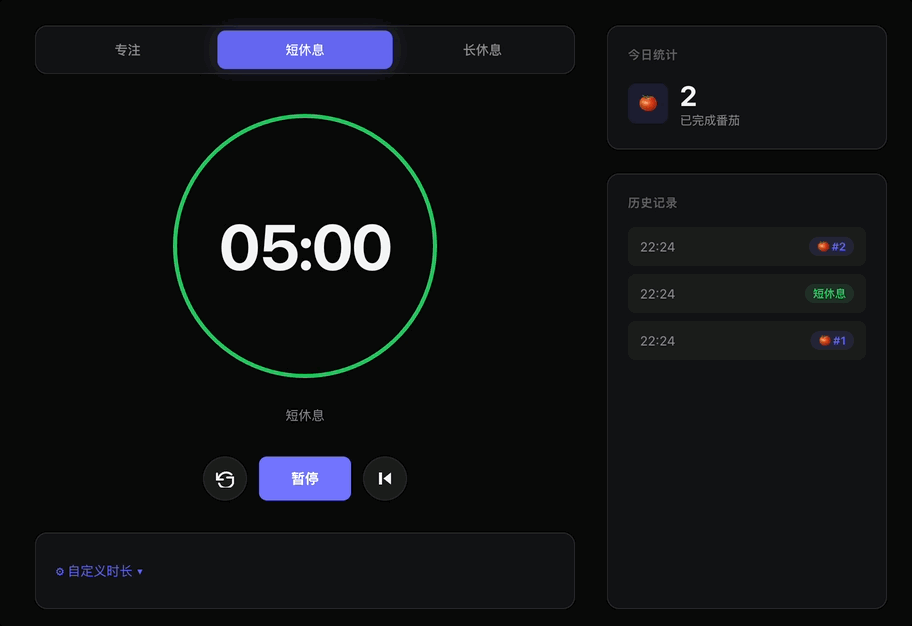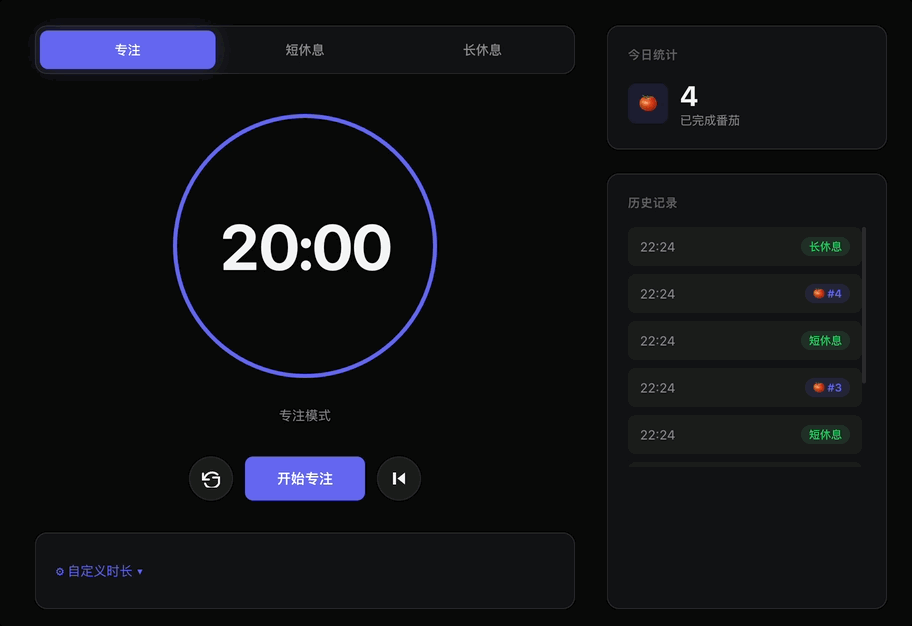
我把它接入了Claude Code,让它写一个网页版的番茄钟应用出来。
实话实说,以现在模型的推理能力,这个任务已经比较简单了,所以这个任务主要想看的是它的速度。
用HTML、CSS、JavaScript实现一个可以直接在浏览器运行的番茄钟工作计时器。要求包含:25分钟专注/5分钟短休息/15分钟长休息三种模式可切换;大字体倒计时显示;开始/暂停/重置按钮;完成一个番茄后自动切换到休息模式并播放提示音(用Web Audio API生成);右侧显示今日已完成番茄数和历史记录列表;支持自定义各阶段时长;配色方案参考Linear设计风格。
结果,它的速度,还真让我大吃一惊。
提交任务后的前5秒,我看到它还在慢吞吞地思考,以为要掉链子。
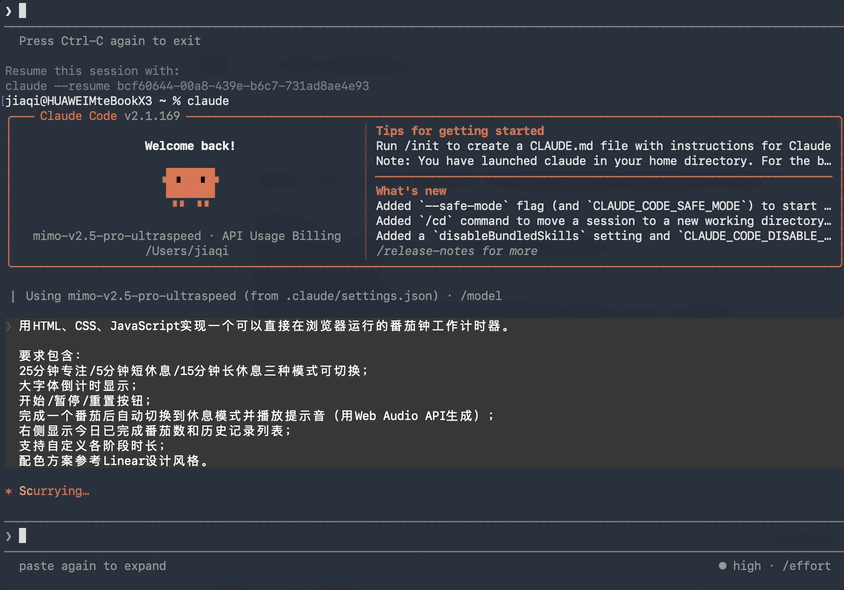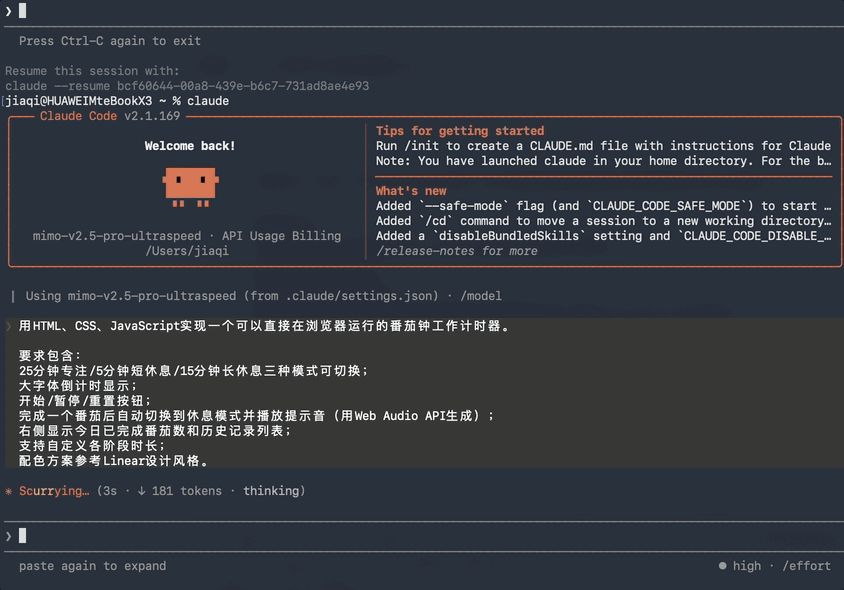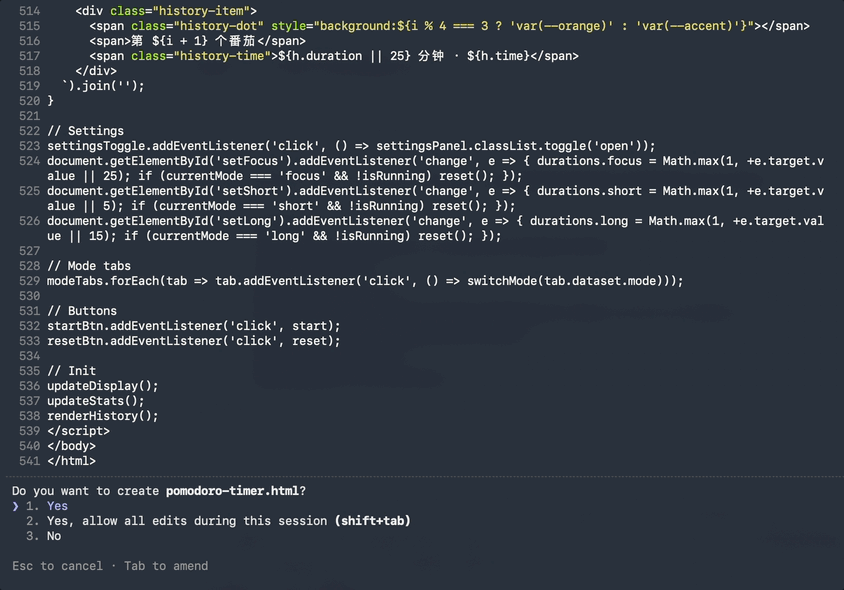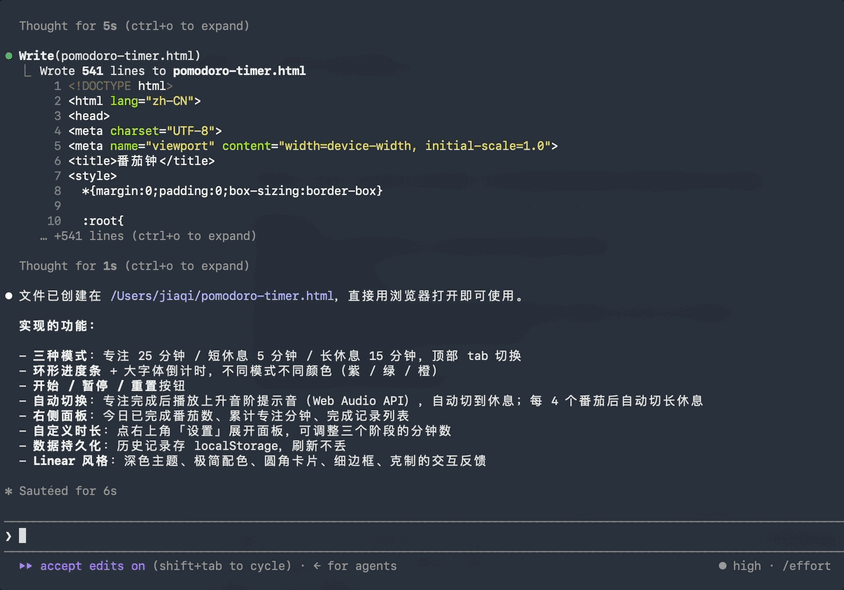
结果它是在憋大招,还没等我回过神,需要交付的番茄钟网页代码就chua得一下全吐出来了。
500多行HTML,加上思考过程一共只用了7秒。
这张动图体现的就是原速度,注意千万别眨眼。
相比之下,如果用Claude,而且还是最轻量的Haiku搭配Low Effort,最短仍然需要40多秒。
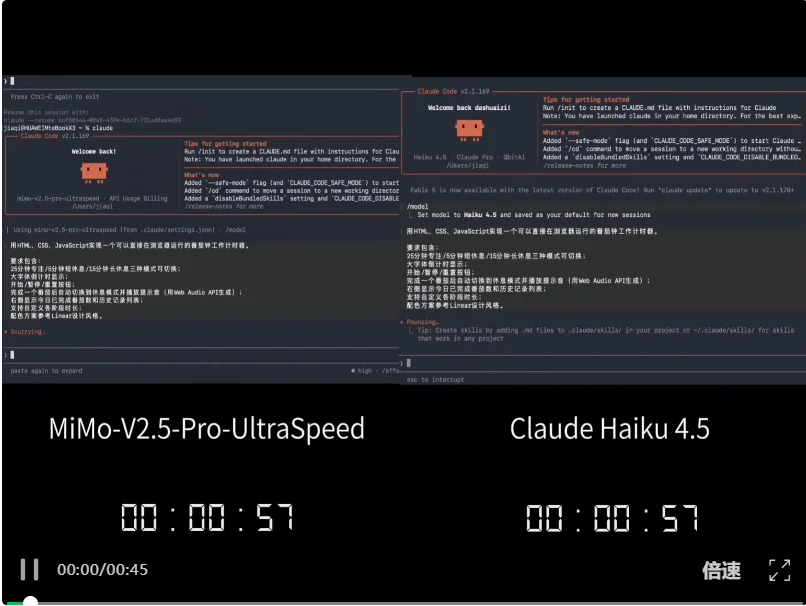
把同样的任务放到网页端来跑,由于思考过程较长,因此总体耗时比用Claude Code接入MiMo-V2.5-Pro-UltraSpeed多了不少。
但网页端的MiMo-V2.5-Pro-UltraSpeed自带速度显示,可以看到输出阶段的平均速度达到了1000+TPS。
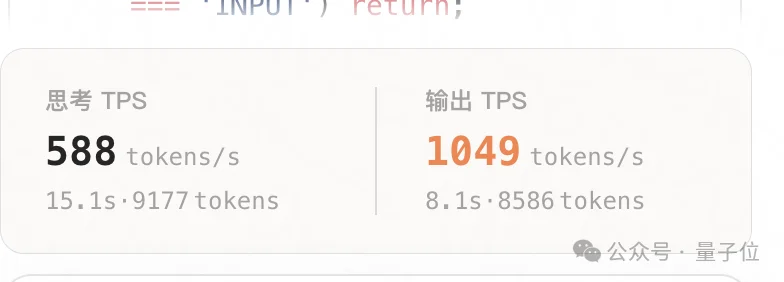
如果看峰值,目测推理阶段最高吞吐量达到了600+ TPS,推理后的输出阶段更是飙到了3300+。
当然简单归简单,功能该验收还是得验收的。
页面跑起来之后,默认时长完全符合要求且支持自定义,要求的音效也会在计时结束时正常播放。
而且完成专注/休息计时后,还会自动跳到另一个模式,并且休息模式的跳转还遵循了三短一长的节奏。
模型跑得快当然是好事,但如果速度是靠“降智”换来的,那就本末倒置了。
所以简单的测速题目结束之后,接下来就要开始上难度,看看MiMo-V2.5-Pro-UltraSpeed的速度背后,到底有没有“降智”。
同时,这里为了测试MiMo-V2.5-Pro-UltraSpeed能不能很好地适配不同的Harness,我又把环境改成了Hermes。
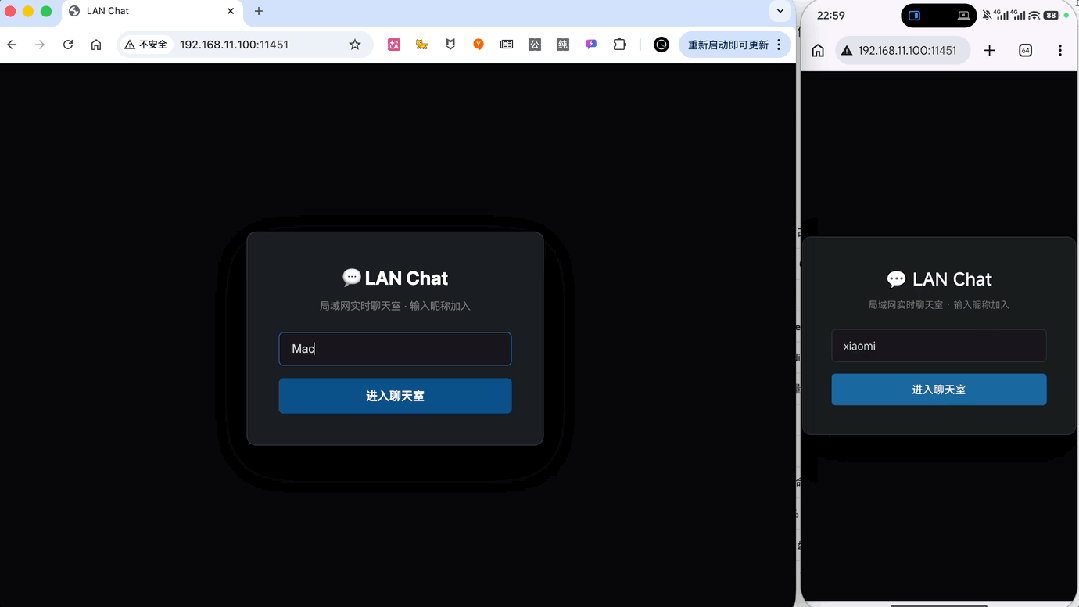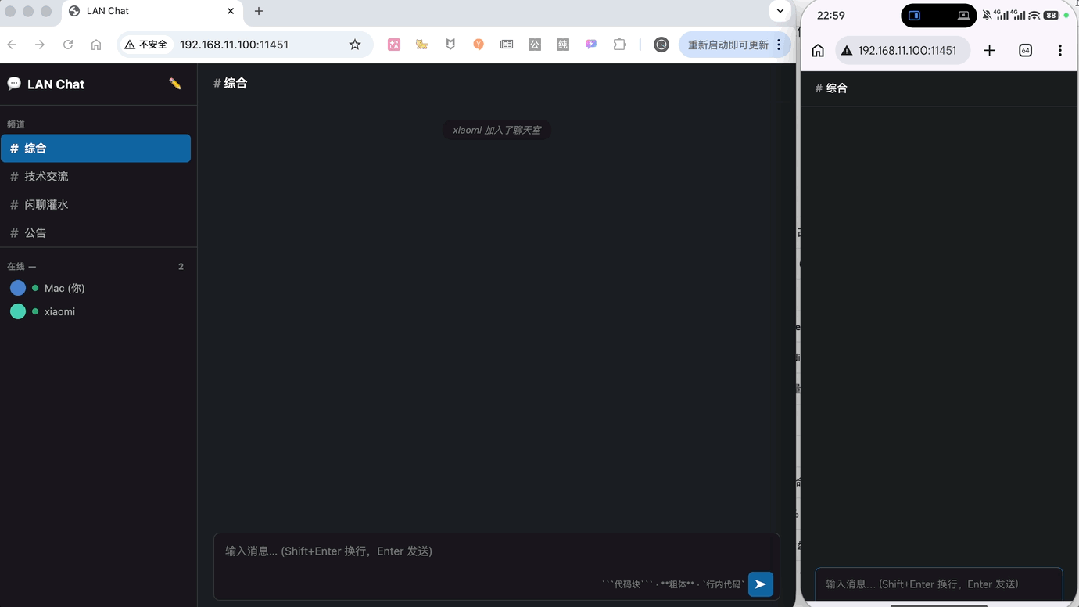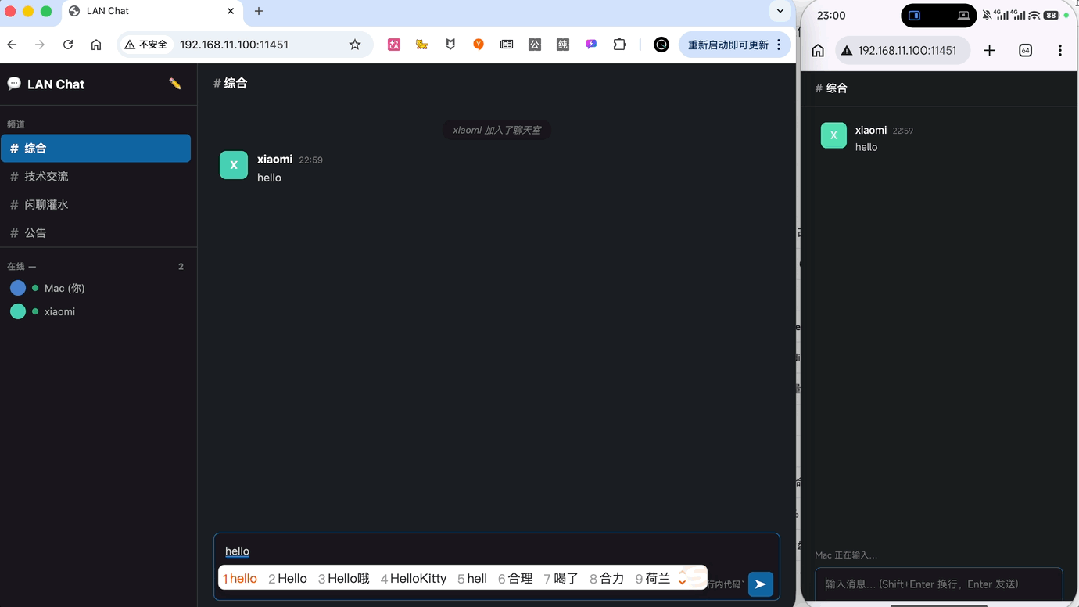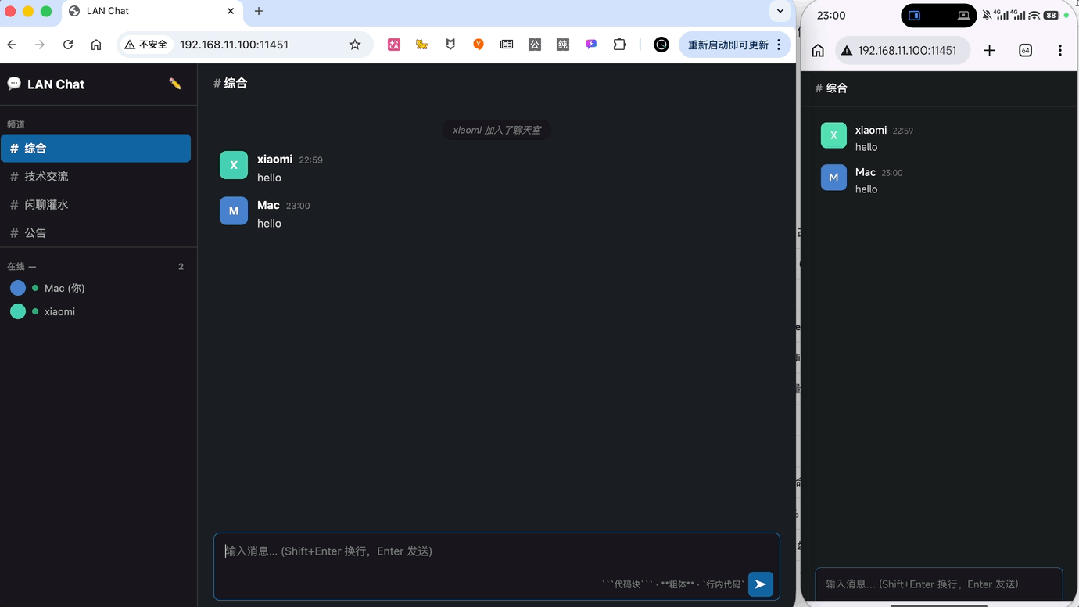
构建一个局域网实时聊天室,要求后端用Node.js + Express + WebSocket;
支持多用户同时在线,用户进入时输入昵称,并和设备绑定,同一设备只有第一次进入时输入,但要有编辑功能;
聊天界面参考Slack风格,支持多个频道切换;
消息支持纯文本和代码块(代码块自动高亮);
显示在线用户列表,用户上下线有系统提示;
支持消息引用回复;
消息记录用SQLite持久化存储,进入频道可加载历史消息;
输出所有文件的完整代码,然后启动并部署到11451端口。
写完之后,MiMo-V2.5-Pro-UltraSpeed直接向我汇报了项目文件、功能清单和启动方式。

我们直接看运行效果。
首先最基础的实时聊天、上下线提醒、输入提示,全都正常实现。
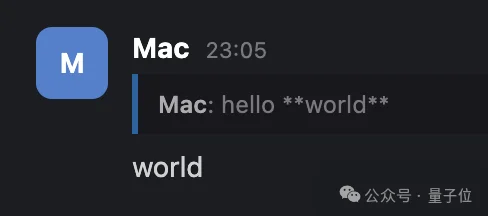
代码、加粗这些特殊格式,也都能正常显示。
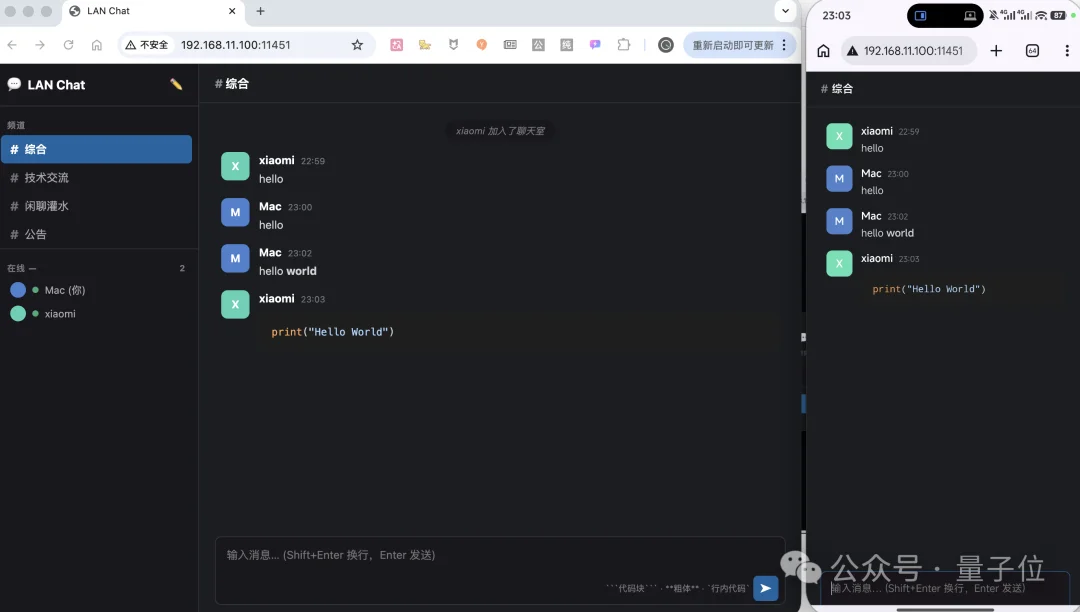
消息引用功能同样正常运转。
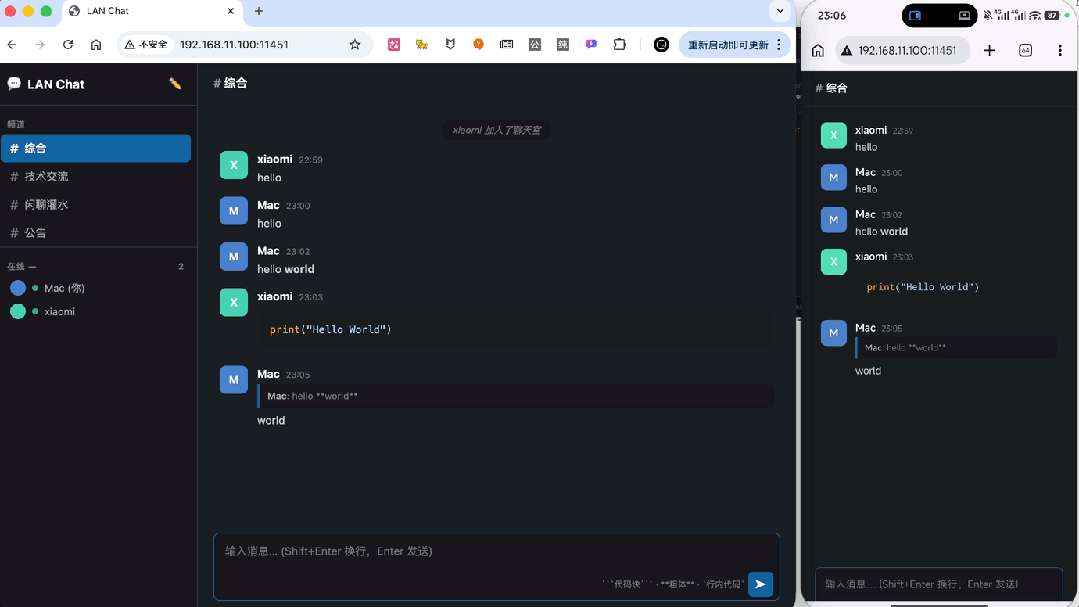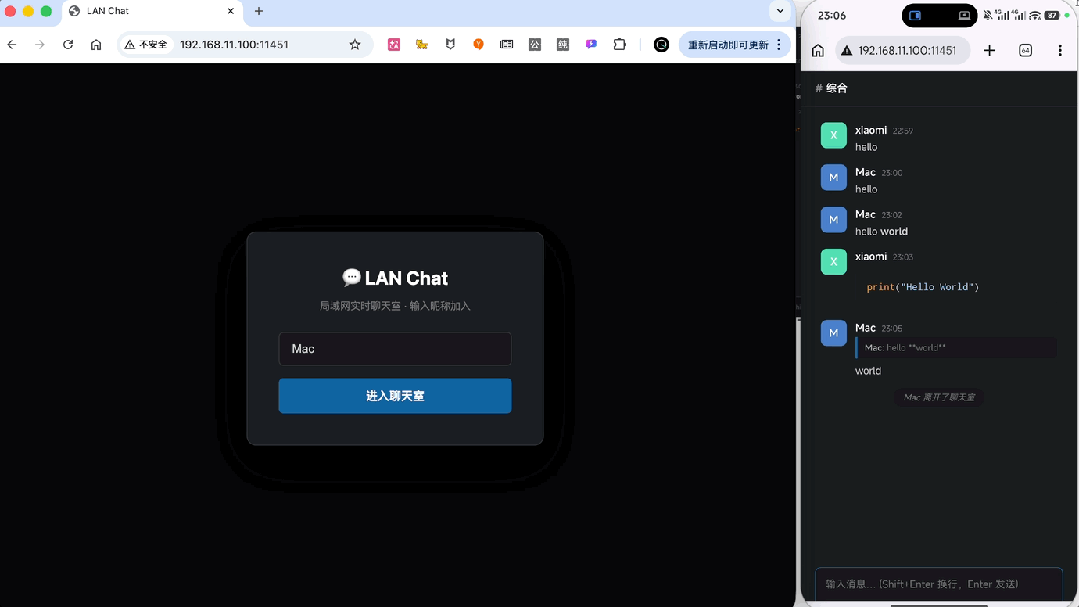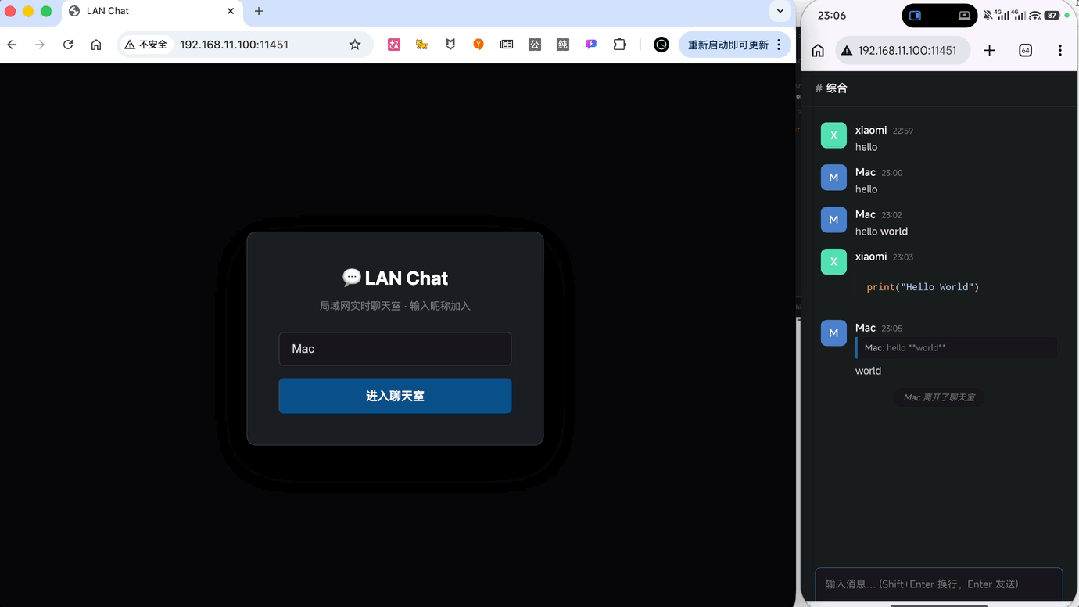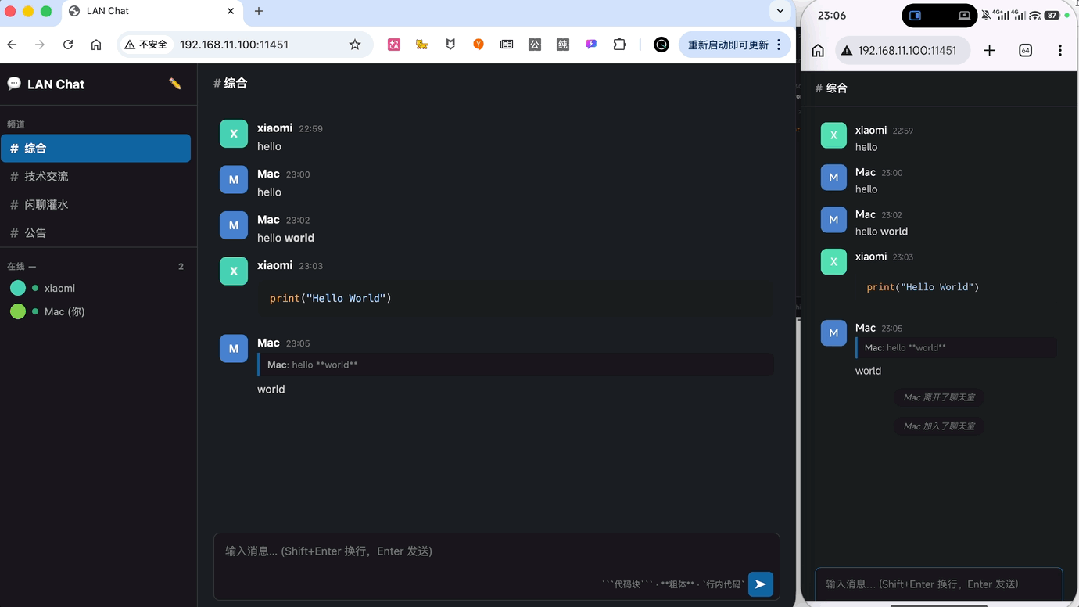
刷新页面之后,之前设定的设备昵称按要求被保留了下来,并且另一端也正常出现了下线提示,在线列表同步变动。
总之这一波,MiMo-V2.5-Pro-UltraSpeed把包含前端、后端、数据库的完整开发流程,三下五除二地就给完成了。
这个例子足以证明,在提升速度的同时,MiMo-V2.5-Pro-UltraSpeed依然能够高质量地完成全栈开发任务,也就是智商依然在线。
不过,这样的速度,在实际生产当中,又能发挥什么作用呢?
我让MiMo-V2.5-Pro-UltraSpeed扮演一位资深剧本编辑,带着四位分析师在投委会前对一份电影大纲做紧急联合审阅。
你是一位资深的剧本编辑,手下有三位得力的审稿人。现在你们需要在明天早上的项目评审会之前,对下面这份院线电影剧本大纲完成一次紧急联合审阅。请按照以下分工完成任务:你的故事结构分析师先接手,专门审查三幕结构是否完整、主线与支线的节奏配比是否合理、高潮场景的铺垫是否充分,出具一份结构审查意见。与此同时,你的人物分析师也在并行工作,专门审查主角的动机是否可信、人物弧光是否完整、配角的功能是否清晰,出具一份人物审查意见。你的市场分析师同步从商业角度出发,审查这个题材的受众定位是否清晰、同类型影片的市场表现如何、这个项目的差异化卖点是否足够,出具一份市场可行性意见。三份意见都到手之后,你作为剧本编辑亲自综合判断:这份大纲能否推进立项?列出必须修改的问题清单,并直接输出一份修改后的完整大纲。
故事的梗概是这样的:
院线电影剧本大纲:《候鸟不南飞》类型现实主义情感剧情片,主打25-40岁都市女性受众。一句话简介一个在北京打拼十二年的湖南女人,在母亲突然病倒后被迫返乡,在照料与逃离之间重新理解了自己与家的关系。主要人物谢晚晴,38岁,北京某公关公司总监,离异,独居,与母亲关系疏远已久;谢母,64岁,湖南县城退休教师,强势、传统,习惯用沉默施压;陈默,40岁,谢晚晴的前同事,因家庭原因提前返乡创业,现经营一家民宿。故事梗概 第一幕:谢晚晴接到父亲的电话,母亲突发脑梗住院。她请假返乡,原本打算处理完就走,却发现母亲的康复需要长期陪护,而父亲已无力独自承担。她陷入职业与家庭的两难。第二幕:谢晚晴滞留县城,在照料母亲的过程中与母亲爆发多次激烈冲突,母亲的强势与控制欲将她推向崩溃边缘。与此同时,她与陈默重新建立联系,陈默的生活选择让她开始重新审视自己十二年来的人生路径。第三幕:母亲康复出院,谢晚晴面临是否回京的最终抉择。她最终选择回京,但与母亲之间达成了某种和解,不是原谅,而是接受彼此是不同的人。核心主题逃离与归属,自我实现与家庭责任,中国式母女关系。预计时长:105分钟。
我用Hermes搭了一个三Agent工作流,让MiMo-V2.5-Pro-UltraSpeed同时启动三个subagent对一份电影大纲做并行审阅。
其中故事结构分析师查三幕节奏,人物分析师查动机和弧光,市场分析师查商业可行性。
三份意见汇总后,主Agent综合判断并直接输出修订版大纲。
结果总共不到两分钟的时间,三个subagent就全都完成了各自的任务,最终的报告也完整交付给了我。

三个subagent各自找到了对方没有发现的问题。
三份意见到齐之后,主Agent给出的修订版大纲补上了所有结构性缺口。
原版只有一句话的第二幕被拆成三层递进冲突,补充了中点和第二转折点,父亲从单纯的信息传递者变成了全片最重要的“翻译者”,陈默的“岁月静好”也被推翻,这个设定直接打碎了主角对“另一种人生”的浪漫化想象。

这类任务的价值在于多角色同时在线、实时协同推进同一个目标。三个subagent并行跑完再汇总,整条链路没有等待感。
换成推理速度不够快的模型,每个节点都会积累延迟,最终拖成一个断断续续的流程。
1000 TPS在这里的价值,是让多Agent协同从理论上可行变成用起来真的流畅。
在MiMo-V2.5-Pro-UltraSpeed出现之前,业界能公开看到的最快推理速度,大概是让一个400B参数的模型,跑出400 TPS的吞吐量。
虽然参数量和吞吐量都只有MiMo-V2.5-Pro-UltraSpeed的四成,但这实际上已经是相当激进的选择。
之所以说激进,是因为这样的速度基本上是靠削减模型参数量换来的,代价就是智商降低。
但小米在模型提速这个问题上,选了一条更难走的路。
MiMo-V2.5-Pro-UltraSpeed的起点是约1T总参数、1M超长上下文的旗舰模型,目标是在通用GPU上把单API推理速度拉到1000+ TPS,三个条件一个都不能放。
为此,小米从模型层、引擎层、系统层三个层面同时下手,进行了全链路的联合设计。

模型层承担了两件事,一是解决1M超长上下文下的计算压力,二是处理参数带宽的压力。
针对上下文问题,MiMo-V2.5系列采用了Hybrid SWA(混合滑动窗口注意力)架构。把注意力机制拆成了两级。
具体来说,模型只针对最近的一段上下文继续做精细计算,更早的内容则先被压缩,以更低的成本参与后续步骤。
这种分层处理让整体计算量降到了Full Attention的约1/7,1M级超长上下文下,推理速度和成本依然能保持稳定。
而对于带宽问题,小米对Expert模块引入了FP4量化,把并行的Expert模块参数压缩到4bit,从源头减小显存占用和读写压力。
与此同时,负责信息路由和关键逻辑的注意力模块和Router模块继续保持高精度,再通过量化感知训练把FP4引入的误差压到最小。
模型层打好了基础,引擎层要解决的是decode阶段的成本问题。
小米采用的DFlash方案对传统的Speculative Decoding草稿线做了结构性改造,将草稿模型沿时间轴逐token串行生成的模式,改成对一整块位置同时并行加工。
同时,主模型也不再对每个token单件验收,变成了对整批半成品集中审核,合格的整体接入,不合格的局部返工。
草稿模型同样使用了SWA架构,并经过专项的密集长链路数据训练,保证每次并行产出的一批候选token有足够高的合格率。
系统层是推理链路的最后一道关卡。
当TPS提升到千级之后,瓶颈在于工序之间的切换开销,以及为小批量请求频繁启停带来的等待损耗。
在上述优化的基础上,小米又与TileRT团队深度协作,在GPU执行路径上做了两项关键优化。
小米综合应用这些技术的结果,就是真的让1T参数的模型,在通用GPU上跑出了1000+ TPS的速度,并且可以稳定复现。
对于小米来说,速度提升的意义,远不止Token吞吐得更快这一件事。
过去,1T参数的旗舰大模型太大、太慢,只能做“事后诸葛亮”,很难接入对延迟极敏感的实时业务。
例如高频量化交易要求在毫秒级窗口内分析市场信号并驱动下单,金融实时反欺诈风控要求每笔交易在0.1秒内完成风险评估,广告RTB竞价要求在100毫秒的请求窗口里完成用户画像、创意匹配和出价决策。
这些场景长期只能依赖规则引擎或小模型,旗舰大模型的深度推理能力一直被挡在门外。
而在单API稳定跑到1000+ TPS之后,这道门被推开了。
日常生产力场景也在发生质变。
过去一个全栈项目的重构,从理解代码库到生成修改方案、逐文件改写、跑测试、修bug,常常拖成8到12分钟的等待。
现在同样的任务被压缩进几十秒,复杂报告的讨论也从把问题丢给模型等它想好,变成了和模型一起边想边改。
总之,很多过去被速度和成本挡在门外的应用场景,如今落地的条件正在成熟。
为MiMo-V2.5-Pro-UltraSpeed做的全链路推理优化,对小米来说还有另一层价值。
这套优化是可以在后续模型和业务场景上直接复用的底层能力,换一代通用GPU只需做适配升级,速度和成本优势可以平移到新平台。
小米自家的模型和业务场景越多,这套能力被复用的次数就越多,单次推理成本越摊越薄,速度优势可以像滚雪球一样越放越大。
把近期小米大模型的几个动作串起来看,信号更加清晰。
小米模型登顶全球开源模型第一、MiMo-2.5系列全面调价,现在又推出1000 tokens/s的旗舰高速模型,三件事依次落地,高速、高智商、全链路成本优化同时到位。
这些事件背后,指向的是同一个方向,那就是系统性地拆除大模型商业化路上的每一道障碍。
文章来自于"量子位",作者 "克雷西"。


【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
