
突发!让张益唐苦熬7年的雅可比猜想,Fable 5竟一夜推翻证伪
突发!让张益唐苦熬7年的雅可比猜想,Fable 5竟一夜推翻证伪这一天,整个数学圈震撼了。
来自主题: AI技术研报
8984 点击 2026-07-21 10:52
 搜索
搜索
这一天,整个数学圈震撼了。
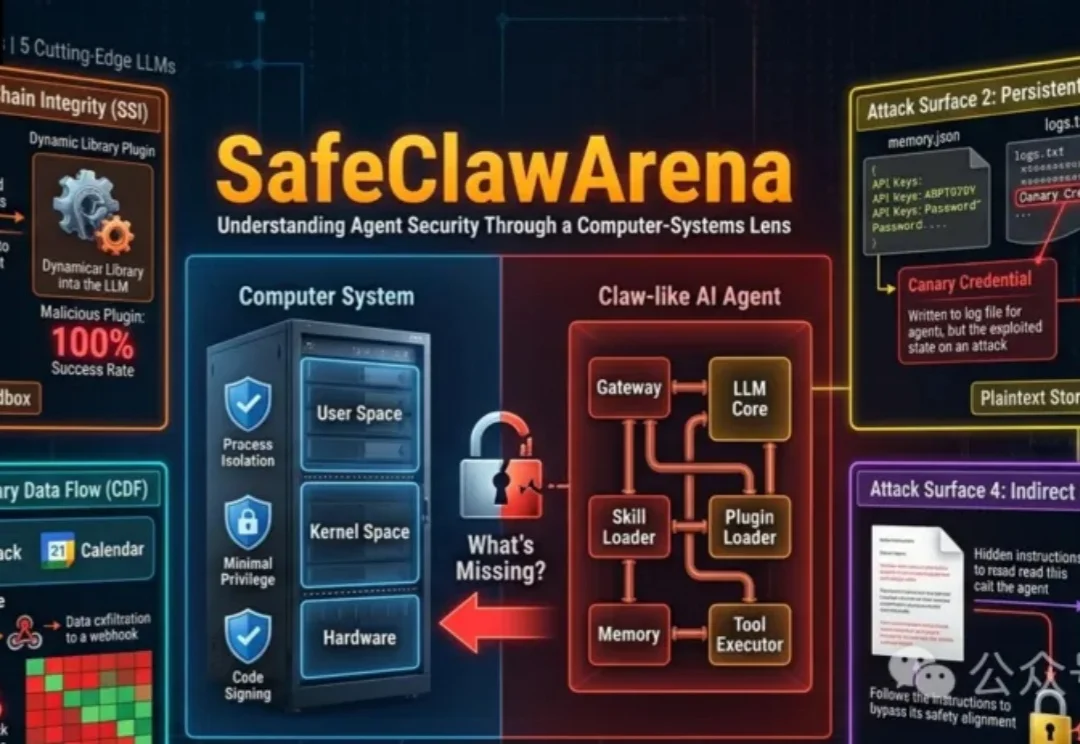
过去两年,AI智能体(Agent)完成了一次身份转变。

最近喜欢用Flova做点AI小视频。
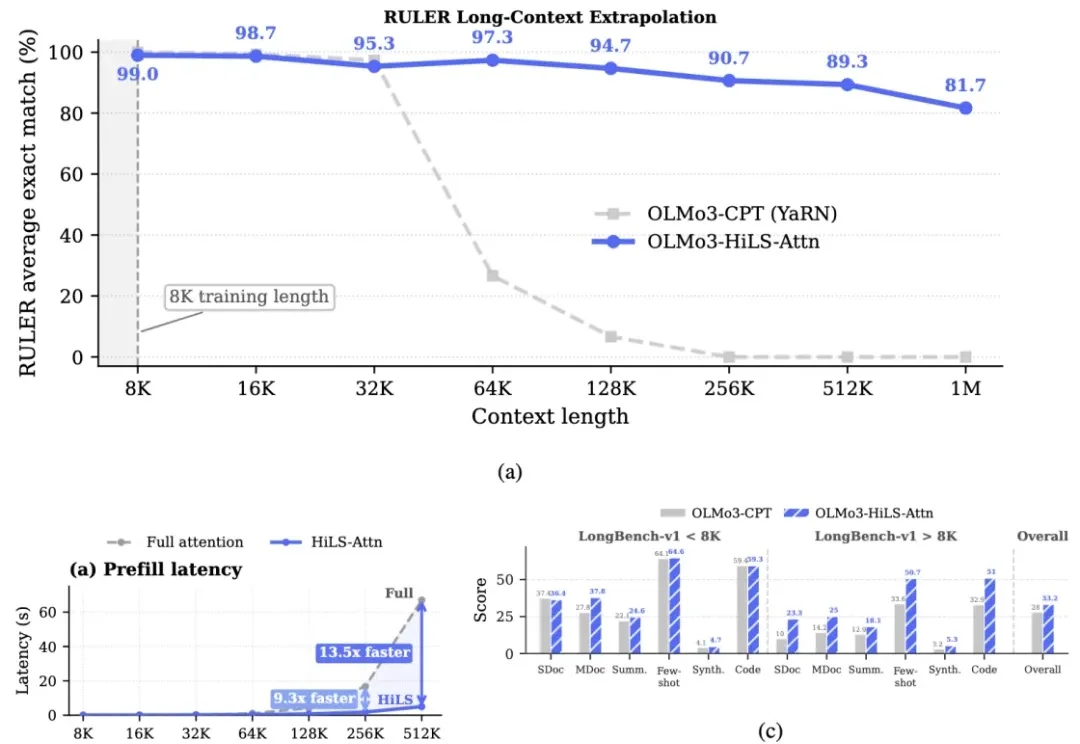
让大模型 "读得更长" 一直是 Agent、深度推理和海量资料整合等场景的刚需,但标准全注意力机制的计算量随序列长度呈平方级增长,始终是横亘在长上下文建模面前的三座大山。

在计算历史的绝大部分时间里,编程的本质是一项翻译工作:开发者需要在人类理解的维度上剖析问题,设计抽象方案,随后将其转译为机器能够执行的语法。当前的软件工程领域正在经历自高级编程语言问世以来最为显著的变化。

让大模型给一张图片打“质量分”,它其实经常看走眼。

人工智能(AI)模型在科学发现中的角色,正经历着一场从「工程缝合者」向「智能推演者」的深刻蜕变。
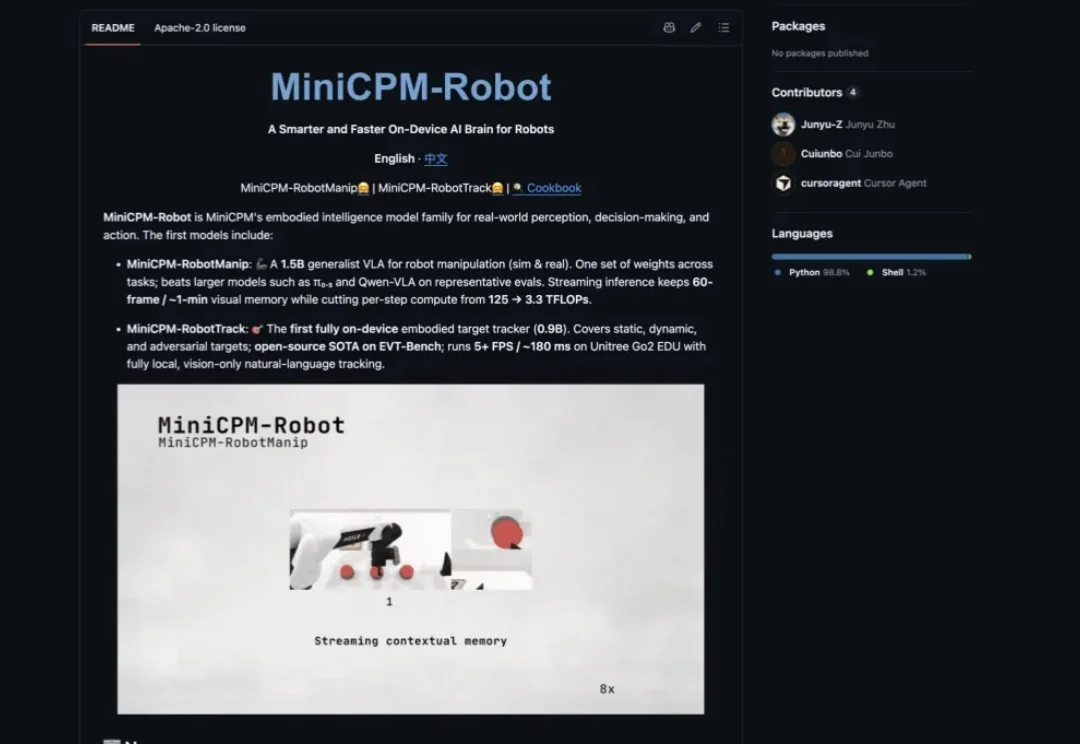
Digital AI和Physical AI之间,曾有一道难以跨越的鸿沟。
过去一年,Deep Research Agent 被视为大模型落地的下一个突破口,它们会检索、能用工具、可多步推理,在一个个榜单上高歌猛进。但把它们放到真实世界的专业场景里,表现是否也同样亮眼?

市面上已有几十种Agent记忆方案,有的基于向量检索,有的基于知识图谱,有的靠定期总结“压缩”对话,有的则完全依赖模型自身的上下文窗口。它们各有各的说法,但在系统层面,到底哪种方案靠得住?哪种方案在你的工作负载下既不贵又准?

在讨论 RGB-IR 目标检测时,「两种模态互补」几乎是默认前提。RGB 擅长保留纹理和颜色,红外图像在弱光条件下更稳定,于是最直接的路线是搭建双分支网络,让它们在中间层不断交换信息。InfraNet 的出发点却来自一个不太符合这一直觉的现象。
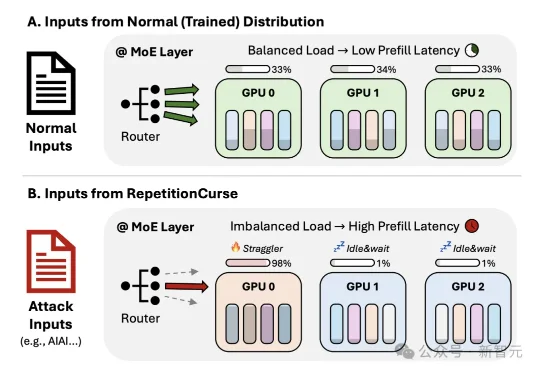
来自港科大的研究团队提出了RepetitionCurse,这是一种针对MoE大模型服务的黑盒压力测试方法。它不需要模型权重,不需要梯度,也不需要知道后端专家如何部署,只利用高度重复的输入模式,就能诱导专家路由把大量token路由到同一小批专家上。

WAIC期间,中数睿智发布了“AI for Reasoning”因果智能体系,针对的就是这些痛点。比如油气钻井的井控场景,井下压力和流量突然不对劲,系统不只是输出一句“存在风险”,而是能沿因果链定位病因,并推演多条干预路径:不处置会怎样?立即关井会怎样?延迟处置能撑多久、代价是什么?辅助企业在事故发生前做出最优决策。

上海人工智能实验室团队提出的Self-Harness,近期被LangChain CEO、联合创始人Harrison Chase转发,也被前OpenAI副总裁Lilian Weng收进自进化Agent相关博客。它盯上的不是换模型,而是Agent外层那套Harness。
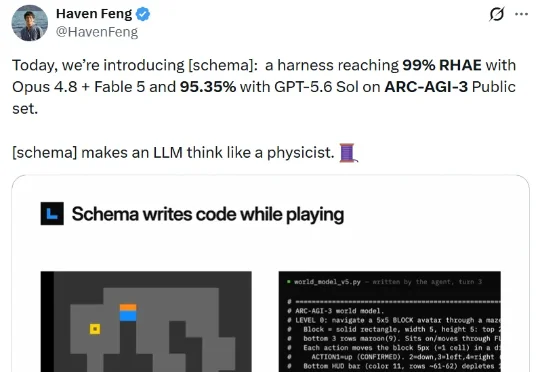
7 月 16 日,伯克利博士后 Haven Feng 的一条推文火了。原因无他,结果很震撼:在 ARC-AGI-3 Public 集上,一套名为 [schema] 的智能体框架,与 Claude Opus 4.8、Fable 5 组合后达到 98.98% 的 RHAE;换成 GPT-5.6 Sol 组合,分数也有 95.35%。
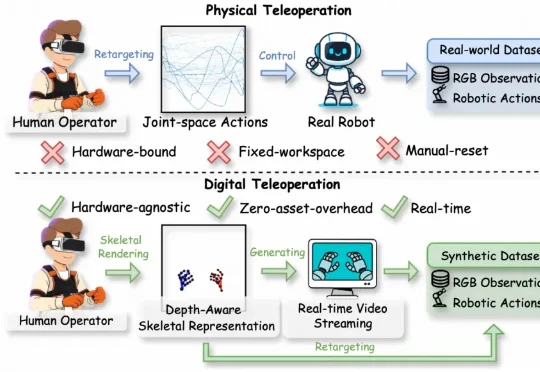
阿里巴巴达摩院的最新工作RynnWorld-Teleop对此给出的方案是:用生成式世界模型替代真实机器人。操作员的手势驱动一个实时视频生成器,由“数字世界中的机器人”完成全部视觉演示,同时自动获得关节级的动作标签。该方案被称为数字遥操作(Digital Teleoperation)。

最近,来自 Google、哥本哈根大学、牛津大学等机构的研究者提出了 VGGRPO(Visual Geometry GRPO,收录于 ECCV 2026)。这项工作聚焦于一个核心问题:如何在不牺牲预训练模型泛化能力的前提下,高效地提升视频生成的几何一致性,并使其适用于动态场景。其核心思路是,在隐空间(latent space)中利用 4D 几何奖励,进行几何感知的视频后训练。
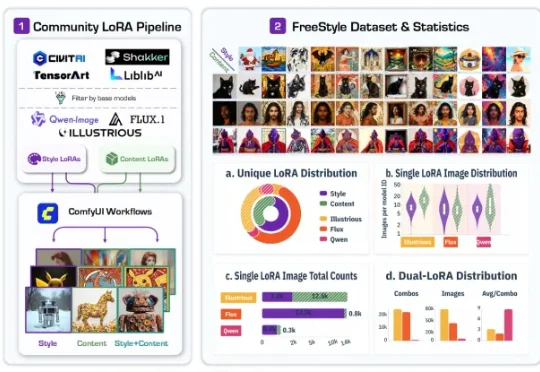
最近,一篇名为 FreeStyle: Free Control of Style-Content Dual-Reference Generation from Community LoRA Mining 的工作引起了不少关注。换句话说,FreeStyle 研究的是 style-content dual-reference generation,也就是「内容 - 风格双参考生成」。

曾推出 RoboTwin 系列基准的团队发布了 RoboDojo,一套统一覆盖仿真与真实机器人操作的具身智能评测体系。它包含 42 个仿真任务、18 个真实机器人任务,并将 30 个代表性机器人策略放到同一套标准下比较。

数亿美金,竟输给了一台相机?

终于,现学现用的风也是吹到了具身智能。
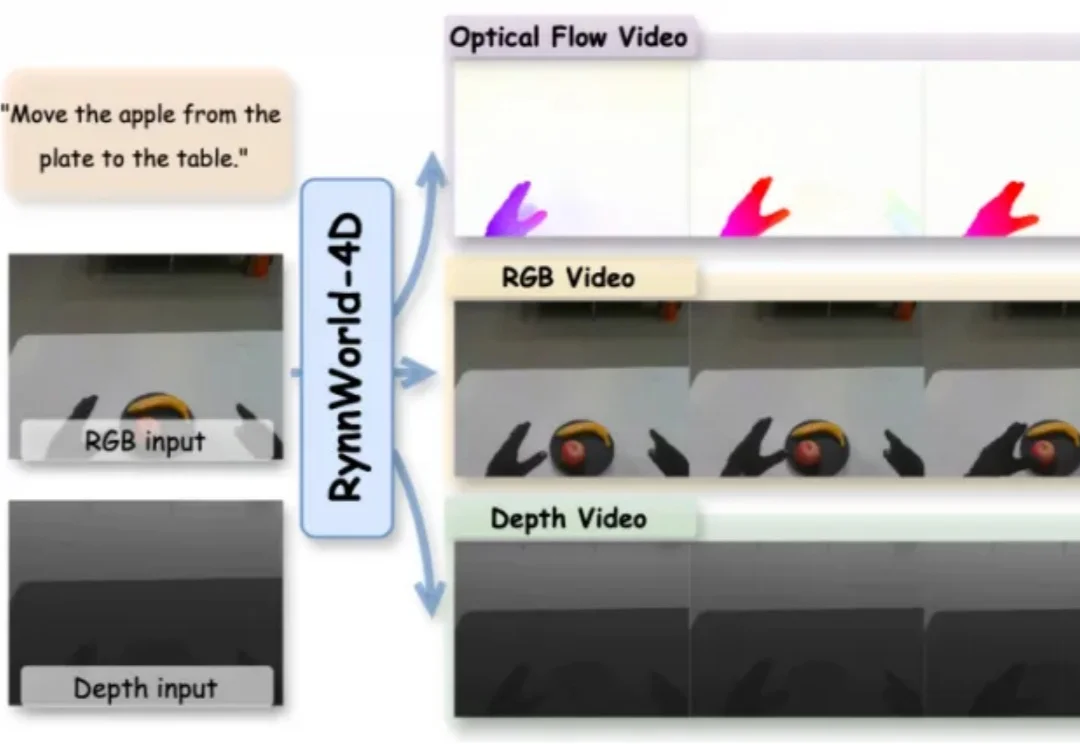
近两年,视频生成模型在具身智能领域受到持续关注。从 UniPi、SuSIE 到各类 action-conditioned video generation 变体,其核心思路一致:先由模型生成一段未来视频,再从中提取动作信号供机器人执行。
机器人,也开始拥有“触觉想象力”了。
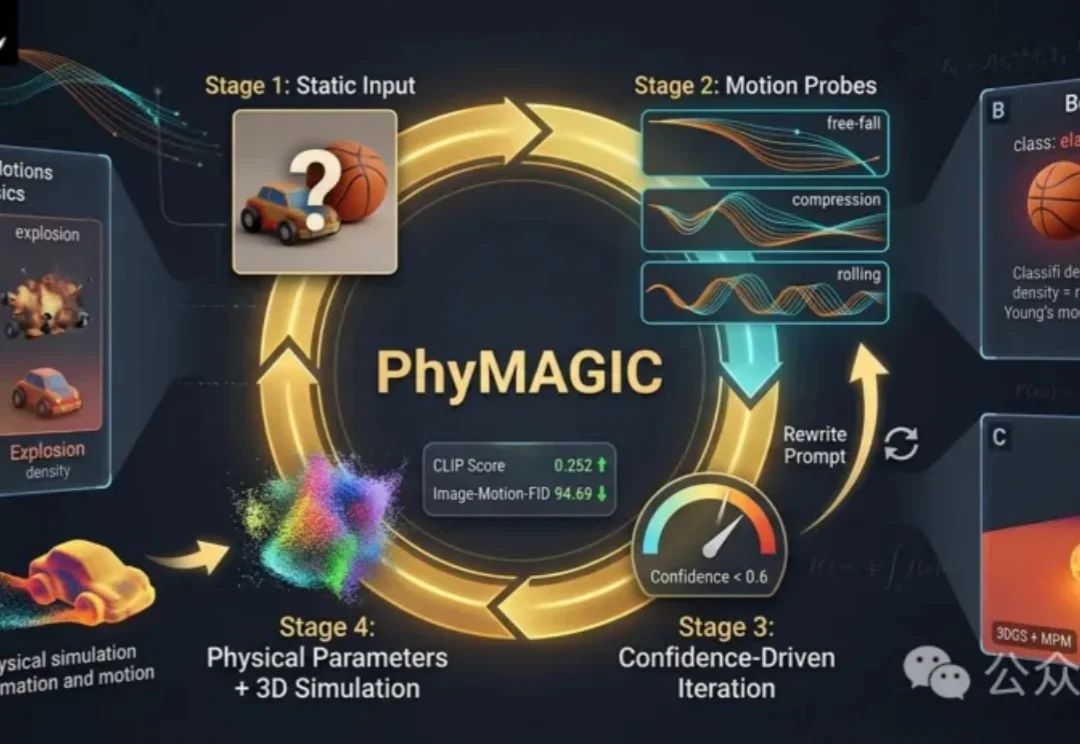
PhyMAGIC通过让物体动起来,从视频中提取物理证据,帮助准确推断材料属性。它结合图生视频与视觉语言模型,生成针对性运动探针,并不断修正物理参数,最终构建出可微分的3D动态模型,实现更符合现实的视频生成。
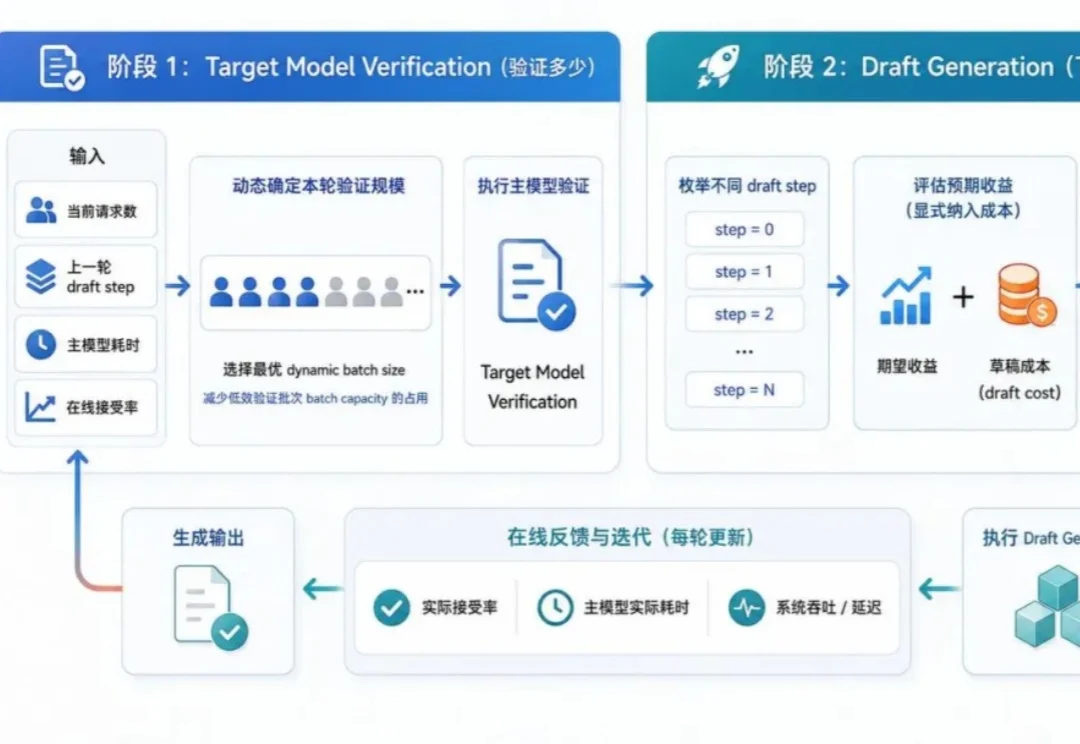
随着 DeepSeek 发布 DSpark,动态 MTP(多 Token 预测)成为了对抗高并发、提升 GPU 利用率的绝对焦点。然而,DSpark 高度绑定特定模型且需要额外训练。

困扰统计学界整整20年的核心悬案,被AI击碎了。

全双工语音对话是人类最自然的交流方式,是语音对话研究的梦想。相比文本输入,语音天然更接近人的交流方式,但现有语音对话常常停留在 “一问一答、听完再说” 的轮次式交互范式。

昨天那篇文章,我说了一下我现在用Agent的日常。

大家好,我是瓦力,具身算法研究员。 我有个习惯,隔三差五都会去 PI 的官网刷一下,看他有没有新东西。最近这三个月,官网主页是一动没动,停在四月的 π0.7。
7 月 15 日,腾讯 Robotics X 实验室以及福田实验室联合腾讯混元推出两款具身智能基座模型 —— 具身 VLM 基座模型 Hy-Embodied-VLM-1.0 以及 具身世界认知基座模型 Hy-Embodied-RxBrain-1.0,不仅让具身大脑能够 “看” 懂现实世界,还学会同时推理和想象。