
2026年玩AI必备技能:不是提示词,是循环工程
2026年玩AI必备技能:不是提示词,是循环工程2026 年,会不会用 AI 不再看 Prompt(提示词)能力了,而是要看会不会设计循环。
来自主题: AI资讯
9549 点击 2026-06-17 09:52
 搜索
搜索
2026 年,会不会用 AI 不再看 Prompt(提示词)能力了,而是要看会不会设计循环。
这绝对是近期把“反向创新”和“互联网幽默”玩到极致的一个案例,当整个 AI 行业都在比拼模型参数、Agent 框架、推理能力和算力规模时,一个 17 岁印度高中生却用一种近乎恶作剧的方式,创造了 2026 年最幽默的一个产品。

昨晚,字节新模型Seedance 2.0 Mini深夜来袭,该模型主打性价比,侧重于提供更低的价格以及更快的生成速度。Seedance 2.0 Mini虽然定价更低,但保留了核心能力参考生成,用户可以通过融合提示词与最多12个多种模态的参考素材(包括6张图片、3段音频、3段视频)来锁定人物一致性、精细化控制运动轨迹、卡准剧情节奏。

AI公司还在拼模型,另一门更底层的生意正在变大。

Agent + 无限画布带来的想象力。
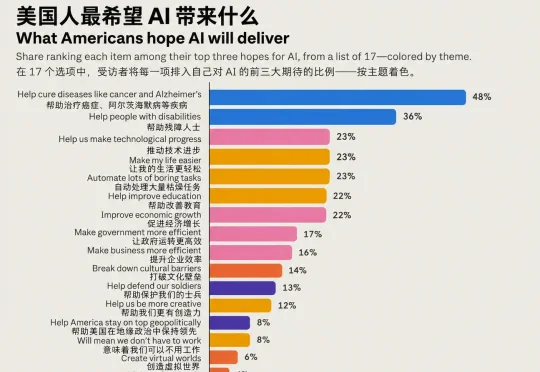
在一个什么都能吵翻天的国家,71%的美国人难得达成共识:AI必须有人管——但管它的,绝不能是造它的人。

离谱了。 这两天,AI 圈都在疯传一个叫 Le Chaton Fat 的新模型。 30T MoE、256 个专家、100 万上下文窗口、多模态多语言,跑分全面碾压 Claude Fable 5、Claude Opus 4.8 和 GPT-5.5。

支付宝20年来最大改版!AI「阿宝」内测开启,一句话就能打车、点咖啡、买基金。微信也在憋大招。10亿用户的超级App,即将彻底变天!

前阿里 Qwen 技术负责人林俊旸的创业公司,有了新消息。据外媒 The Information 援引知情人士的消息,在林俊旸完成的首轮融资中,腾讯投资了 2000 万美元。本轮融资总额达数亿美元,投后估值约 20 亿美元。
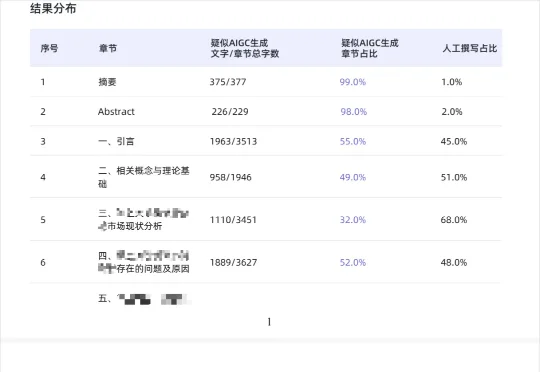
最近公司里有几个大四的小伙伴,快被毕业论文的AI率检测给逼疯了。每天都能看到他们下班后,在工位上一脸崩溃地改论文。因为现在很多大学的毕业论文,都有一个非常强硬的AIGC率检测,不能超过一个百分比,如果超过了,你就没办法毕业。