
AI在用:万万没想到,科技论文还能这么读
AI在用:万万没想到,科技论文还能这么读laude 3 具有非常大的内存( 200k 上下文窗口)和很强的调用准确性,它的上下文能力也因此成为最受欢迎、应用最广的技能。我们介绍过如何利用这种能力,没时间收听播客也能获取核心内容。今天,我们再介绍一个新技能,帮助技术小白快速 get 最新、最前沿的科技成果
来自主题: AI资讯
8546 点击 2024-04-11 10:48
 搜索
搜索
laude 3 具有非常大的内存( 200k 上下文窗口)和很强的调用准确性,它的上下文能力也因此成为最受欢迎、应用最广的技能。我们介绍过如何利用这种能力,没时间收听播客也能获取核心内容。今天,我们再介绍一个新技能,帮助技术小白快速 get 最新、最前沿的科技成果
纯C语言训练GPT,1000行代码搞定!,不用现成的深度学习框架,纯手搓。 发布仅几个小时,已经揽星2.3k。
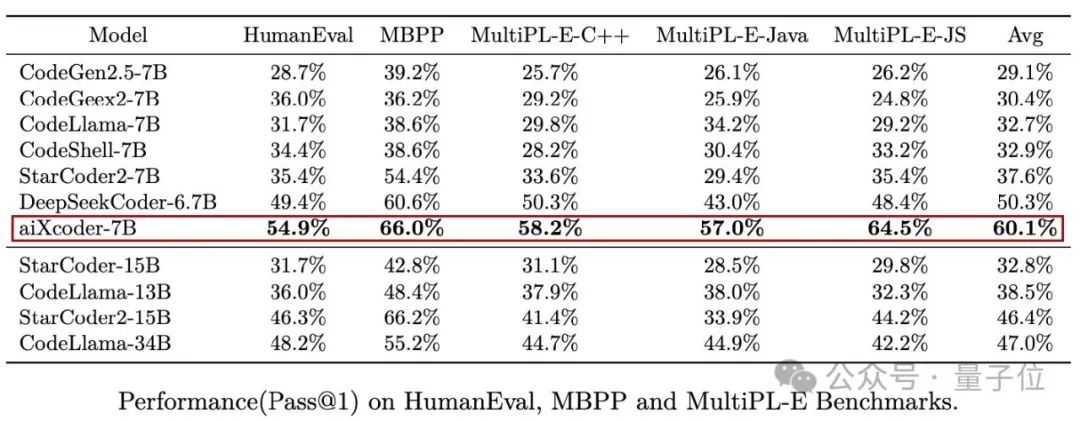
来自Meta、基于Llama2,可是开源界最先进的AI编程大模型之作

近日,朱泽园 (Meta AI) 和李远志 (MBZUAI) 的最新研究《语言模型物理学 Part 3.3:知识的 Scaling Laws》用海量实验(50,000 条任务,总计 4,200,000 GPU 小时)总结了 12 条定律,为 LLM 在不同条件下的知识容量提供了较为精确的计量方法。

这次,谷歌要凭「量」打败其他竞争对手。 当地时间本周二,谷歌在 Google’s Cloud Next 2024 上发布了一系列 AI 相关的模型更新和产品,包括 Gemini 1.5 Pro 首次提供了本地音频(语音)理解功能、代码生成新模型 CodeGemma、首款自研 Arm 处理器 Axion 等等。

最近,一款针对下一代的AI儿童绘画App热度很高,仅上线7天,在Product Hunt(产品猎手)上,被网友投票为2024年最佳儿童应用产品排名第六。

就离谱,都2024了,人工智能靠人工的戏码还在上演。 而且是类似ATM机背后坐真·柜员给你递钱的那种!

第一个针对「Segment Anything」大模型的域适应策略来了!相关论文已被CVPR 2024 接收。
「Real men program in C.」 众所周知,大语言模型还在快速发展,应该有很多可以优化的地方。我用纯 C 语言来写,是不是能优化一大截? 也许很多人开过这样的脑洞,现在有大佬实现了。

不降低大模型算法精度,还能把芯片的算力利用效率提升 2~10 倍,这就是编译器的魅力。