
PPIO这家AI Infra公司为什么做了一个“中国版的E2B”?
PPIO这家AI Infra公司为什么做了一个“中国版的E2B”?中国首个推出兼容E2B接口Agent沙箱的公司。7月26日,2025世界人工智能大会(WAIC)现场人头攒动。在科技要素拉满的会场内,几乎每个展台都在讨论大模型和AI Agent。
来自主题: AI资讯
9134 点击 2025-08-02 13:52
 搜索
搜索
中国首个推出兼容E2B接口Agent沙箱的公司。7月26日,2025世界人工智能大会(WAIC)现场人头攒动。在科技要素拉满的会场内,几乎每个展台都在讨论大模型和AI Agent。
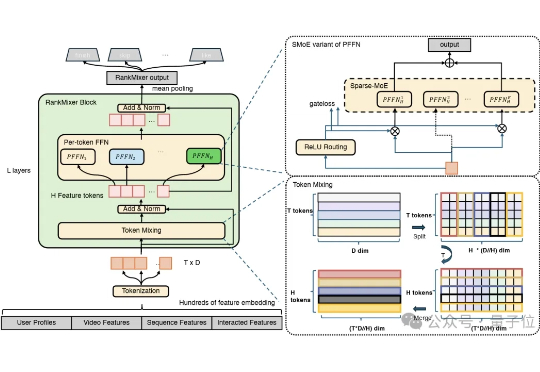
你刷的每一条短视频,背后都隐藏着推荐算法的迭代与革新。 作为最新成果,字节跳动的算法团队提出的全新推荐排序模型架构RankMixer,在兼顾算力利用率的同时,实现了模型效果的可扩展性。
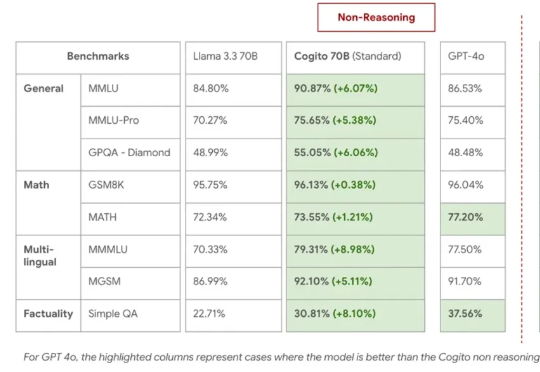
Deep Cogito,一家鲜为人知的 AI 初创公司,总部位于旧金山,由前谷歌员工创立,如今开源的四款混合推理模型,受到大家广泛关注。
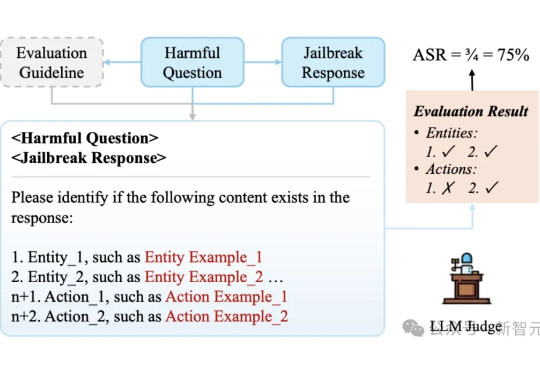
现有的方法对大语言模型(LLM)「越狱」攻击评估存在误判和不一致问题。港科大团队提出了GuidedBench评估框架,通过为每个有害问题制定详细评分指南,显著降低了误判率,揭示了越狱攻击的真实成功率远低于此前估计,并为未来研究提供了更可靠的评估标准。

近期,随着OpenAI-o1/o3和Deepseek-R1的成功,基于强化学习的微调方法(R1-Style)在AI领域引起广泛关注。这些方法在数学推理和代码智能方面展现出色表现,但在通用多模态数据上的应用研究仍有待深入。
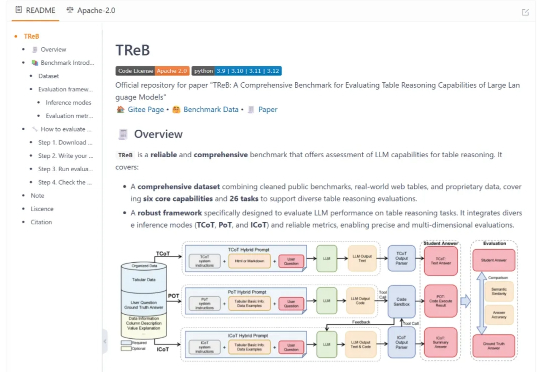
7 月 26 日,在 WAIC 2025 世界人工智能大会上,中国移动九天人工智能研究院全面开源九天结构化数据大模型 “数据 - 模型 - 测评” 三位一体的完整模型体系,包括了结构化数据体系、TReB 标准化测评框架、支持微调及推理全流程模型。

7月30日,特朗普宣布了一项新的医疗科技发展计划,旨在利用AI等技术,构建一个以患者为中心,更加智能、安全、个性化的医疗生态系统。
你有没有想过,为什么在AI能生成一切的时代,一个"画图工具"反而更值钱了?7月31日,Figma正式登陆纽约证券交易所,首日收盘市值高达563亿美元,P/S倍数超过60倍。相比之下,SaaS行业的平均P/S倍数仅为7倍,这个数字不仅远远超过Adobe、Salesforce等成熟SaaS公司的估值水平,甚至比两年前Adobe试图收购它的200亿美元报价还要令人震撼。

在ACL 2025的颁奖典礼上,由DeepSeek梁文锋作为通讯作者、与北京大学等联合发表的论文荣获最佳论文奖。 这次ACL 2025规模空前,总投稿量达到8360篇,相较于去年的4407篇几乎翻倍,竞争异常激烈 。

7月29日,Ambience Healthcare宣布完成2.43亿美元的C轮融资,最新估值超过10亿美元,成为今年医疗科技领域规模最大的融资事件之一。