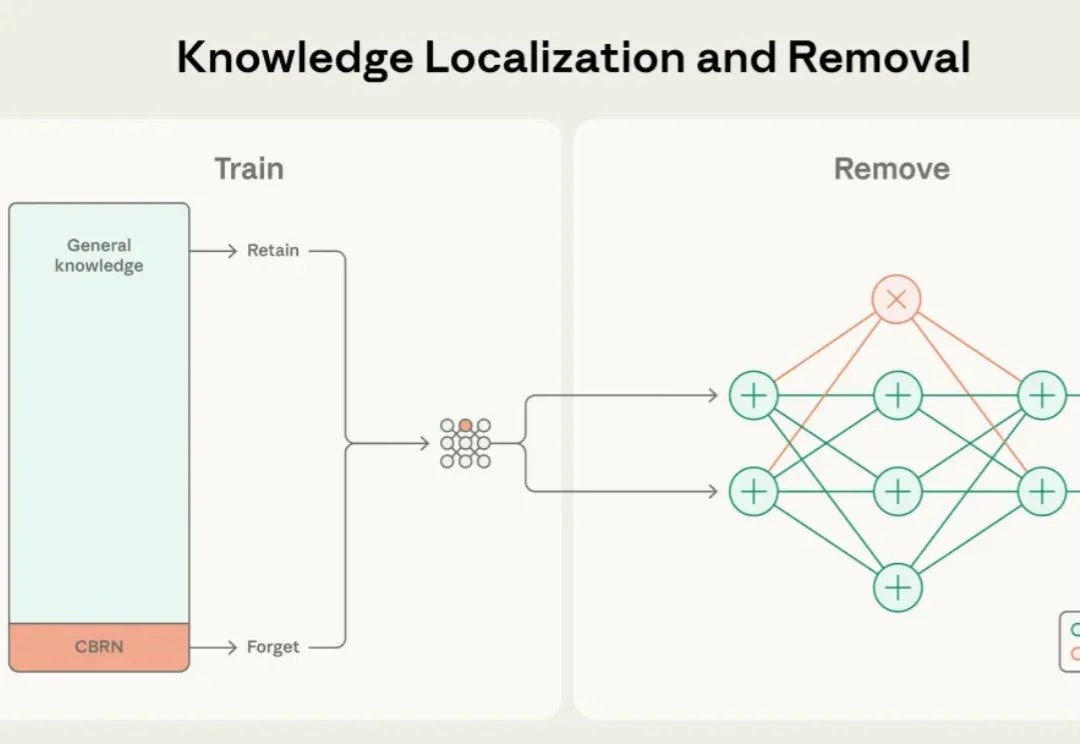
Anthropic公布新技术:不靠删数据,参数隔离移除AI危险
Anthropic公布新技术:不靠删数据,参数隔离移除AI危险近年来,大语言模型的能力突飞猛进,但随之而来的却是愈发棘手的双重用途风险(dual-use risks)。当模型在海量公开互联网数据中学习时,它不仅掌握语言与推理能力,也不可避免地接触到 CBRN(化学、生物、放射、核)危险制造、软件漏洞利用等高敏感度、潜在危险的知识领域。
来自主题: AI技术研报
9584 点击 2025-12-25 10:21
 搜索
搜索
近年来,大语言模型的能力突飞猛进,但随之而来的却是愈发棘手的双重用途风险(dual-use risks)。当模型在海量公开互联网数据中学习时,它不仅掌握语言与推理能力,也不可避免地接触到 CBRN(化学、生物、放射、核)危险制造、软件漏洞利用等高敏感度、潜在危险的知识领域。

在代码大模型(Code LLMs)的预训练中,行业内长期存在一种惯性思维,即把所有编程语言的代码都视为同质化的文本数据,主要关注数据总量的堆叠。然而,现代软件开发本质上是多语言混合的,不同语言的语法特性、语料规模和应用场景差异巨大。

AI 钉钉 1.1,不仅仅是一个 0.1 版本更新。

生成式AI狂奔三年,2025迎来架构创新的大年,三条脉络交织演进,伴随着Scaling law(规模定律)遇到天花板的争议,开始定义AI进化的新范式。

从大模型智能的“语言世界”迈向具身智能的“物理世界”,仿真正在成为连接落地的底层基础设施。

中山大学等机构推出SpatialDreamer,通过主动心理想象和空间推理,显著提升了复杂空间任务的性能。模拟人类主动探索、想象和推理的过程,解决了现有模型在视角变换等任务中的局限,为人工智能的空间智能发展开辟了新路径。

霍尔特计划收购老东家新山资本旗下最成功的五家医疗科技公司,并将其合并到其新创立的AI医疗平台——Thoreau。这五家公司分别是:健康数据交换巨头Datavant、AI理赔优化平台Machinify、精准医疗营销商Swoop、医疗流程自动化公司Smarter Technologies 以及电子医疗记录平台Office Ally。
MiniMax海螺视频团队不藏了!首次开源就揭晓了一个困扰行业已久的问题的答案——为什么往第一阶段的视觉分词器里砸再多算力,也无法提升第二阶段的生成效果?翻译成大白话就是,虽然图像/视频生成模型的参数越做越大、算力越堆越猛,但用户实际体验下来总有一种微妙的感受——这些庞大的投入与产出似乎不成正比,模型离完全真正可用总是差一段距离。

2025 年还有一周结束,年底,AI 视频圈又卷起来了。
Sebastian 在分析中指出,Profit AI 的核心功能非常简单:用户上传一张股票图表的照片,AI 就会给出分析。他甚至直接展示了这个应用的全部技术:就是调用 ChatGPT API,上传图片,发送提示词,然后返回分析结果。如果你直接用 ChatGPT 做同样的事情,得到的信息几乎一模一样。这个应用唯一做的,就是把这个过程包装得更精美一些,界面更友好一些。