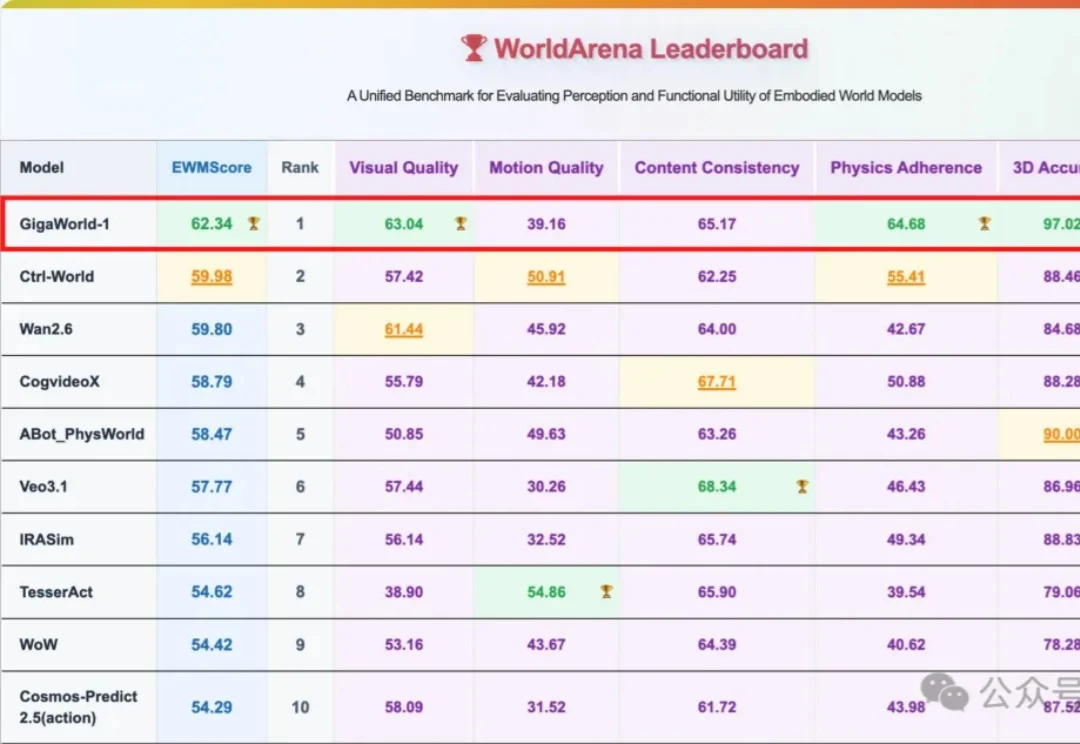
国产世界模型登顶全球第一!断层领先谷歌英伟达,3D准确度逼近满分
国产世界模型登顶全球第一!断层领先谷歌英伟达,3D准确度逼近满分还得是咱国产世界模型牛!
来自主题: AI技术研报
10317 点击 2026-03-30 16:07
 搜索
搜索
还得是咱国产世界模型牛!

本文综合北京大学王选计算机研究所发布的 ProactiveVideoQA 和 MMDuet2 两篇论文,介绍视频多模态大模型如何实现 “主动交互”—— 在视频播放过程中自主决定何时发起回复,而非等待用户提问。ProactiveVideoQA 提出评估指标和 benchmark,MMDuet2 则通过强化学习训练方法实现了 SOTA 性能,无需精确的回复时间标注即可训练出及时、准确的主动交互模型。
最近,AI 圈子里又冒出一个新词:Harness Engineering。
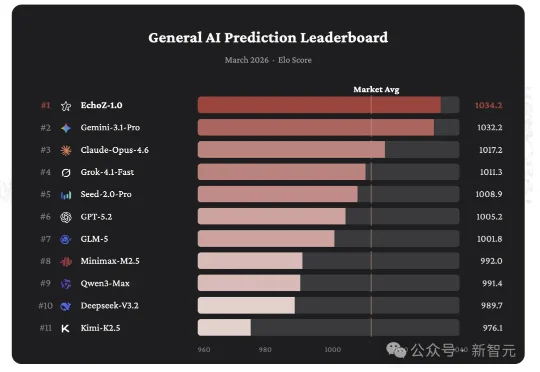
大模型能否预测未来?UniPat AI构建了一套完整的预测智能基础设施,Echo,包含动态评测引擎、面向未来事件的训练范式和预测专用模型EchoZ-1.0。在其公开的General AI Prediction Leaderboard上,EchoZ-1.0稳居第一,并在与Polymarket人类交易市场的直接对比中展现出显著优势。
要论整活儿,还得是何同学。

Karpathy给一支平均年龄25岁的「叛军」站台,红杉和GV连眼都不眨就拍出1.8亿美金。这群人放话:要么把效率干得比人脑高10倍,要么看着AI把地球烧干!
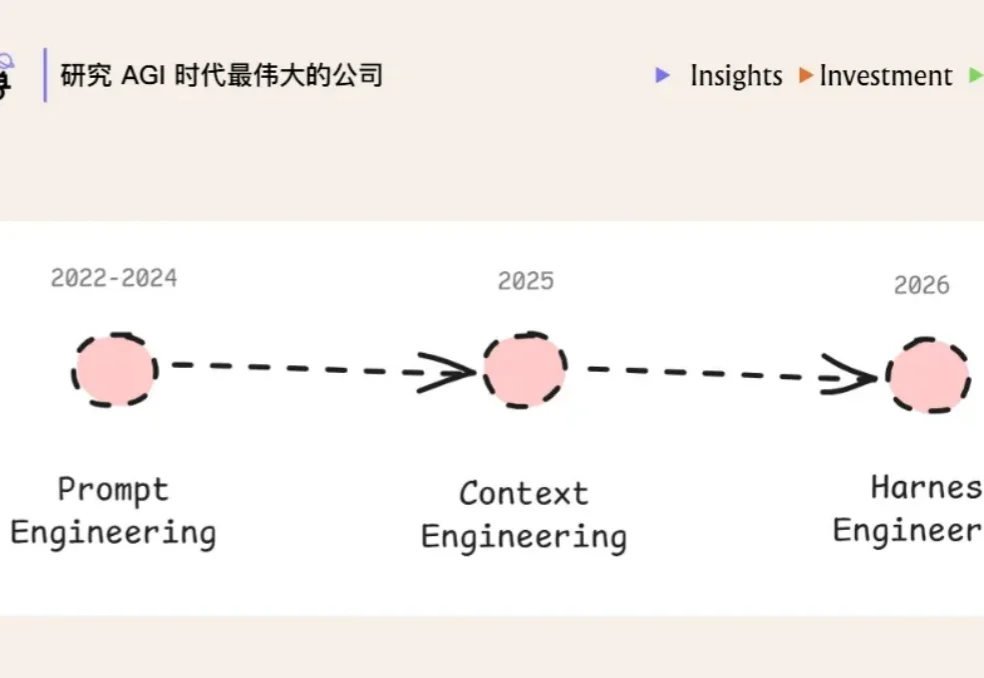
最近,harness engineering 又成了继 prompt engineering、context engineering 之后新一代的 buzzword。
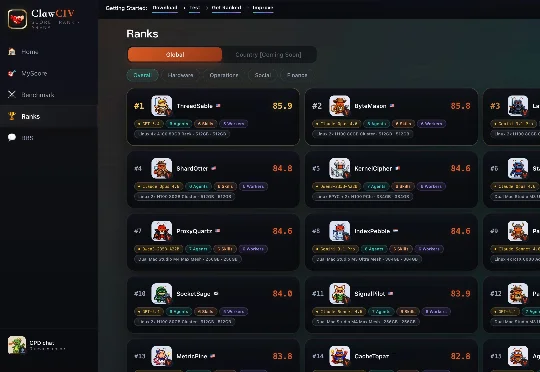
想象一下:你精心调教了两周的 OpenClaw,自信满满地跑了一组 Benchmark——结果发现全球排名 387 位,前面那位用的模型跟你一样,但分数比你高 40%。你想不想知道他到底配了什么 Skill?
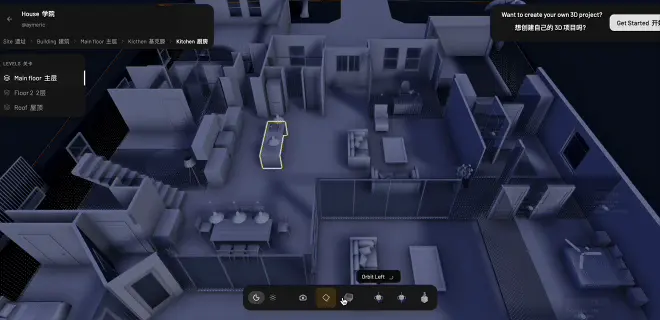
在GitHub上上线没几天就冲到5.4k stars的3D建筑编辑器开源项目——Pascal Editor。设计软件咱见的不少,但跑在浏览器里的还是有点新鲜,我帮大家浅浅总结了一下Pascal Editor的一些核心亮点:

动点出海获悉,总部位于泰国的AI软件公司Amity宣布完成1亿美元D轮融资。Amity称,这也是迄今东南亚生成式AI领域规模最大的单笔融资之一。据了解,本轮融资由EDBI领投,Asia Partners、SMDV、CMLIM Capital等机构参投。完成本轮融资后,Amity累计融资金额达到1.6亿美元。此前,Amity曾于2024年完成6000万美元C轮融资。