Agentic时代推荐系统范式认知或被颠覆?个性化推荐或将从平台中心转向用户主导
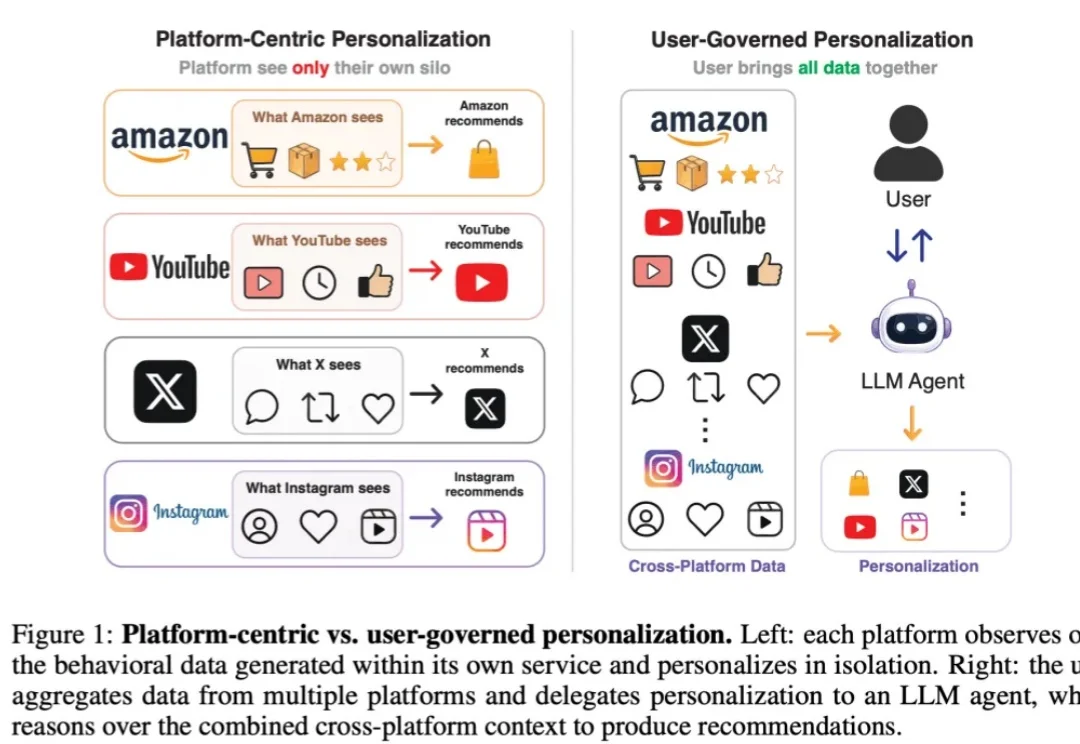
Agentic时代推荐系统范式认知或被颠覆?个性化推荐或将从平台中心转向用户主导在过去二三十年的互联网发展中,个性化推荐几乎一直是平台的核心能力之一。打开视频 app,平台决定你接下来会刷到什么视频;打开购物软件,平台预测你可能会购买什么商品;打开短视频 app,平台根据你的浏览、点赞、停留和互动,不断优化信息流。某种意义上,现代互联网的用户体验本身就是由推荐系统塑造的。
来自主题: AI技术研报
9479 点击 2026-07-13 14:43