新架构模型HRM-Text创新纪录!1B参数、1000美元,图灵奖得主都亲自下场了
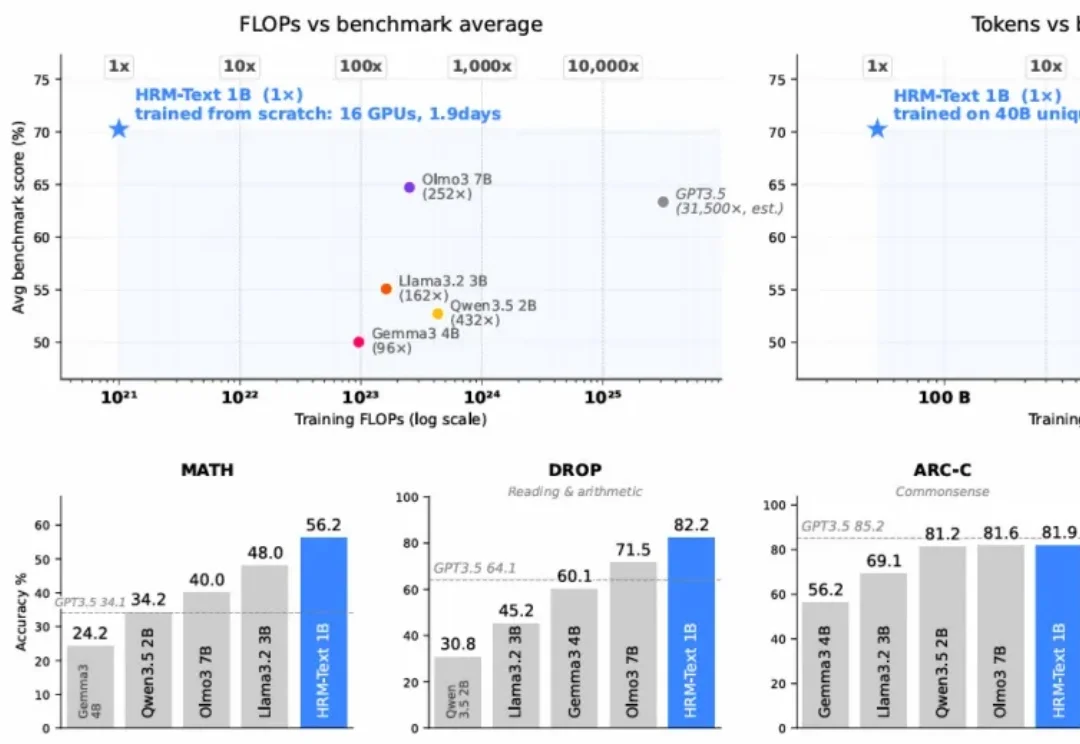
新架构模型HRM-Text创新纪录!1B参数、1000美元,图灵奖得主都亲自下场了一个约 1B 参数的模型,在 MATH 上拿到 56.2,在 GSM8K 上拿到 84.5,在 ARC-Challenge 上拿到 81.9。训练成本约 1500 美元,16 块 H100 跑了不到两天。
来自主题: AI技术研报
8965 点击 2026-06-09 14:57
 搜索
搜索
一个约 1B 参数的模型,在 MATH 上拿到 56.2,在 GSM8K 上拿到 84.5,在 ARC-Challenge 上拿到 81.9。训练成本约 1500 美元,16 块 H100 跑了不到两天。

近日,普林斯顿大学的研究团队发布了一篇新论文,提出了一个名为 Goedel-Architect 的智能体框架。他们用的核心模型,是国内开源大模型 DeepSeek-V4-Flash。

智东西6月3日报道,宣布和英伟达合作后,Nous Research在昨日晚间,终于放出了他们开发的Hermes桌面版(预览)。在此之前,Hermes用户一直窝在终端里跑命令,有人转投民间开发者做的Web UI和桌面版,有人干脆不折腾,直接连飞书在上面养马,这次官方突然发布桌面版,很多人第一反应就四个字:早该有了。

近日,「智能知识」(Human Intelligence)完成天使轮融资,由耀途资本、锦秋基金联合投资。本轮融资资金将用于两个方向:前沿数据品类扩张:深耕 Coding、Enterprise Office(GDPVal)、Agentic Tool Use 等高价值数据,并积极探索 AI4Math、AI4Science、AutoResearch 等新场景;
DeepSeek 研究员陈德里(Deli Chen)和 AI 合作的第二篇论文来了!论文地址:https://victorchen96.github.io/continual_learning_survey.pdf这篇论文聚焦 continual learning(持续学习) 与 self-iteration(自我迭代)。在陈德里看来,这是 AI 迈向 AGI 过程中极为关键的一步。

5 月下旬,NVIDIA 联合清华大学、多伦多大学和 Vector Institute 发布 Gamma-World,共一第一为清华大学电子系博士刘芳甫,核心 Research 方向是世界模型和空间智能。

GPT-5.5 把进攻性网络安全最难的 7 个基准全部打穿,92.4% 正确率,评估体系直接失灵。AI 黑客能力每 6 个月翻一倍,而衡量它有多危险的尺子,已经先被干碎了。
「借助 CodeAgent,我终于可以重新捡起很多过去因为精力不足而搁置的事情了,写博客就是其中之一。这篇博客大概 1% 是我写的,99% 是 Agent 写的 😂」。

当对话型 AI 服务于数十亿用户时,我们能否看见用户没说出口的那一层?JHU、MIT 和 Google Research 给出了新的解法。
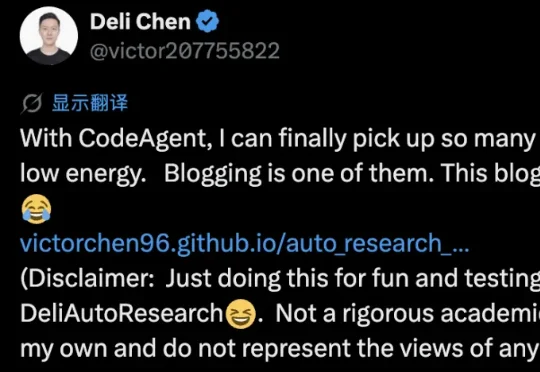
DeepSeek研究员陈德里,在个人博客更新一篇研究综述论文。用的是他自己的技能DeliAutoResearch,DeepSeek-V4-Pro研究和写作,GPT-Image2画图。论文共迭代6次(V1:4 次,V2:1 次,V3:1 次),总耗时6天,进行了约108轮Agent调用,消耗64.8万token,写了2234行LaTeX代码。