AI一眼认出95万物种,还能分辨雄雌老幼,2亿生物图像炼成“生命视觉”大模型
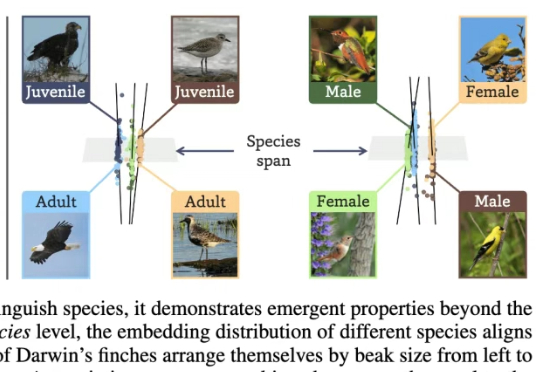
AI一眼认出95万物种,还能分辨雄雌老幼,2亿生物图像炼成“生命视觉”大模型让AI看懂95万物种,并自己悟出生态关系与个体差异!俄亥俄州立大学研究团队在2亿生物图像数据上训练了BioCLIP 2模型。大规模的训练让BioCLIP 2取得了目前最优的物种识别性能。
来自主题: AI技术研报
7821 点击 2025-06-29 16:59
 搜索
搜索
让AI看懂95万物种,并自己悟出生态关系与个体差异!俄亥俄州立大学研究团队在2亿生物图像数据上训练了BioCLIP 2模型。大规模的训练让BioCLIP 2取得了目前最优的物种识别性能。

带着最新最强的模型,走向最热门的赛道,这用来形容 Google 昨天推出的 Gemini CLI 最合适不过了。
前天分享了一篇介绍Gemini CLI的文章《谷歌杀疯了!免费2.5 Pro+开源Gemini CLI,就是要卷死所有AI编程工具..》 没想到还有点小火...这篇文章,我带大家来解决一下这个登录不上的问题。另外,Gemini CLI的Github上提的问题太多了。。。目前已经有516个Issues

朋友们,大家好呀! Google 昨晚发布并且开源了自己的终端代码运行助手,GEMINI-CLI ,完全是照着 Claude Code 来对标。如果你已经非常习惯使用 Claude Code 了,相信也可以无缝切换到 Gemini-Cli 来尝试使用。
这两天Google推出了Gemini-CLI这个编程工具,功能和Claude Code基本一致,结果根本排不上队,登录一下很快闪退,和下图一样,使用感受令人不愉悦。很多人都在等着体验这个新工具,但现实是您可能要等很久才能轮到。

开源且免费!谷歌对编程Agent出手了。
就在刚刚,谷歌深夜悄无声息地扔下了一颗重磅炸弹,正式推出了一个全新的开源AI编程工具:Gemini CLI
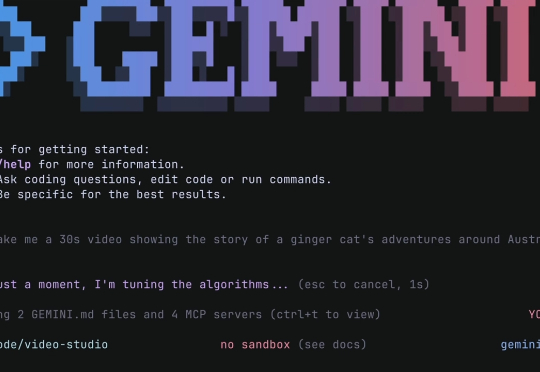
刚刚谷歌推出了 Gemini CLI,一个开源的 AI Agent,把 Gemini 的能力直接带到你的终端里。可以把它看作是谷歌版的 Claude Code。最香的是,这玩意儿开源、免费用,背后是带百万上下文的最强 Gemini 模型。
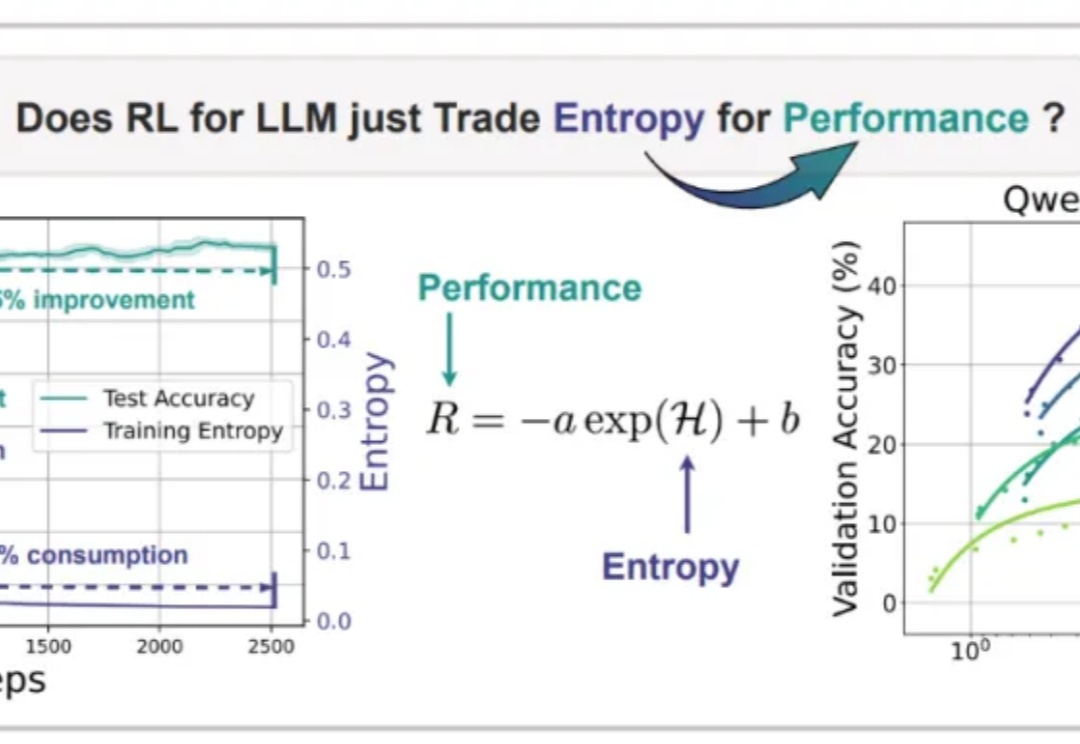
Nature never undertakes any change unless her interests are served by an increase in entropy. 自然界的任何变化,唯有在熵增符合其利益时方会发生——Max Planck
刚刚,OpenAI 正式对外推出了 AI 编码神器 Codex,其目前向 ChatGPT Plus 用户开放。据悉,Codex 在限定时段内提供宽松的使用额度,但在需求高峰期间,可能会对 Plus 用户设置速率限制,以确保其能广泛可用。