CVPR 2026|清华联合美团推出3DThinker,首个用3D意象思考的工作
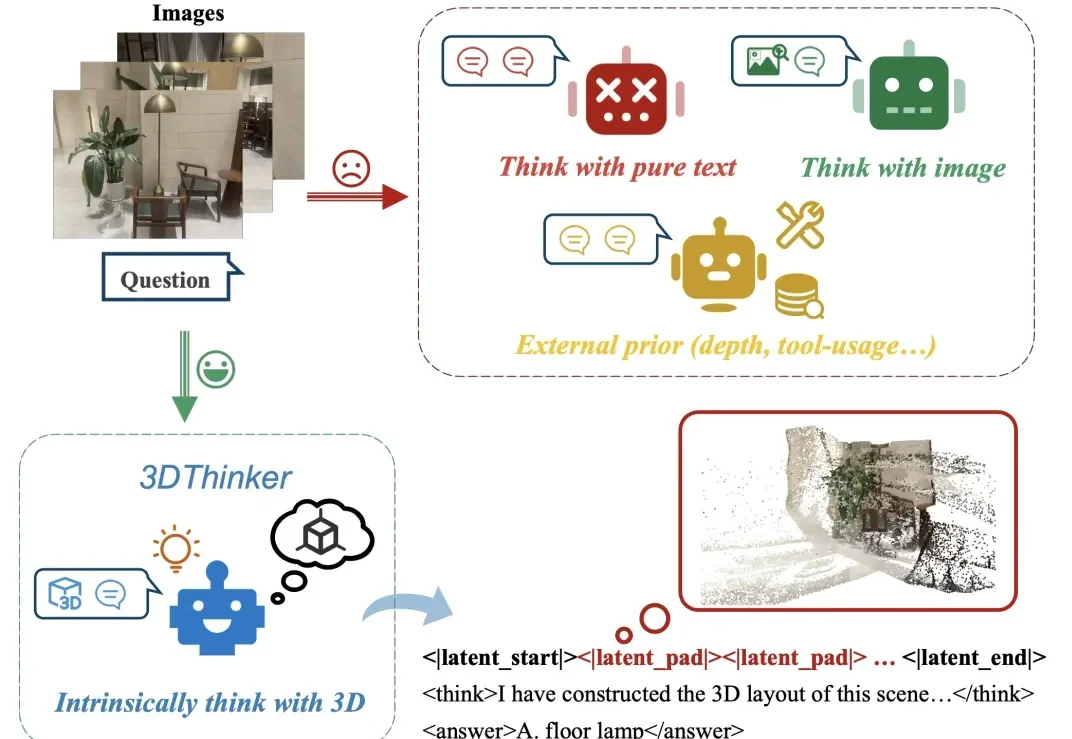
CVPR 2026|清华联合美团推出3DThinker,首个用3D意象思考的工作大家是否有这样的感觉?给定几张场景中拍摄的图片,往往能够在脑海中想象出这个场景的三维布局,然而当前的多模态大模型还停留于纯文本或者 2D 视觉的推理表示,限制了图像中隐含几何结构的表达能力。
来自主题: AI技术研报
9281 点击 2026-03-11 09:25
 搜索
搜索
大家是否有这样的感觉?给定几张场景中拍摄的图片,往往能够在脑海中想象出这个场景的三维布局,然而当前的多模态大模型还停留于纯文本或者 2D 视觉的推理表示,限制了图像中隐含几何结构的表达能力。

视频生成进入大规模时代,但计算成本也炸了。
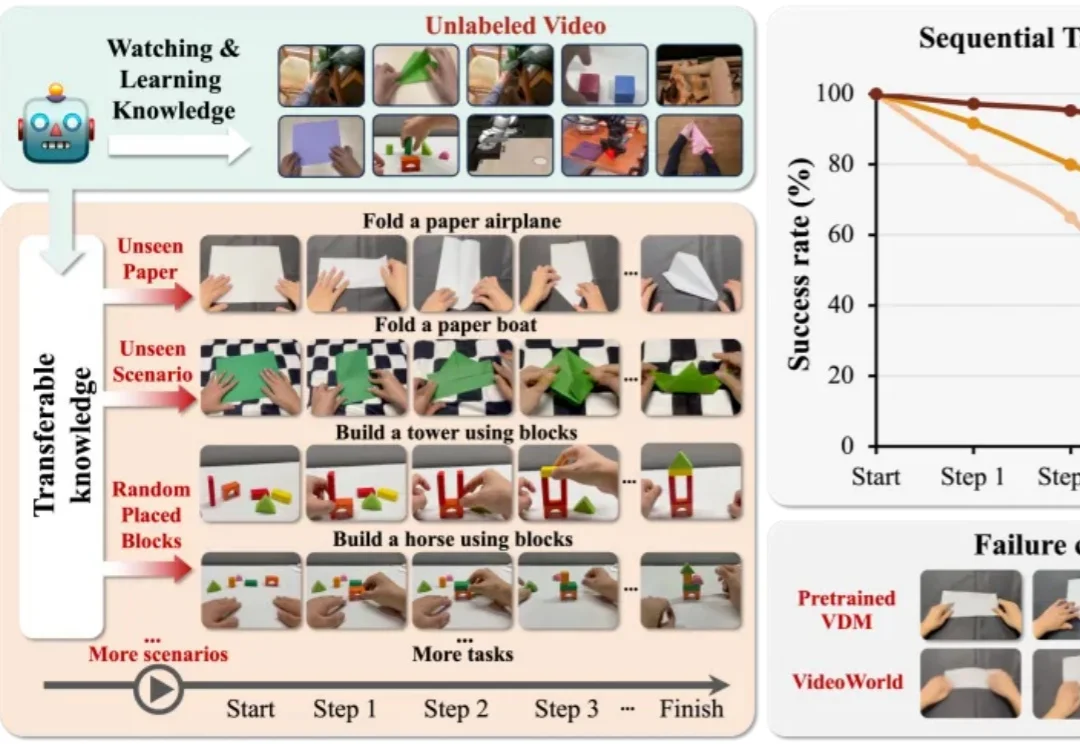
视觉世界模型 “VideoWorld 2” 由豆包大模型团队与北京交通大学联合提出。不同于 Sora 2 、Veo 3、Wan 2.2 等主流多模态模型,VideoWorld 系列工作在业界首次实现无需依赖语言模型,即可认知世界。
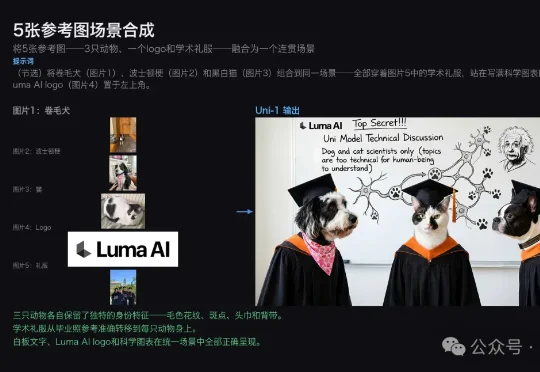
刚刚,Luma AI甩出全新模型Uni-1,正面对标谷歌Nano Banana Pro和GPT Image 1.5。Uni-1是一个统一的图像理解与生成模型。在官方展示中,Uni-1具备角色姿态迁移、故事板生成、草稿+材质结合参考生成、草稿转漫画、多参考图场景合成、草稿引导的照片编辑、UV贴图生成、带有文字的贺卡海报生成等诸多能力。
近期,大连理工与快手可灵团队推出了 MultiShotMaster—— 一个高度可控的多镜头视频生成框架,该论文向研究社区展示了即使在 1B 左右的小参数量级模型上,也可以实现导演级的镜头调度和连贯叙事,且支持多图参考、主体运动控制。
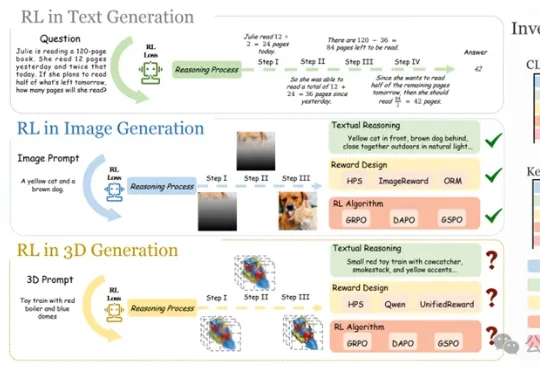
当GRPO让大模型在数学、代码推理上实现质变,研究团队率先给出答案——首个将强化学习系统性引入文本到3D自回归生成的研究正式诞生,并被CVPR 2026接收。该研究不只是简单移植2D经验,而是针对3D生成的独特挑战,从奖励设计、算法选择、评测基准到训练范式,做了一套完整的系统性探索。
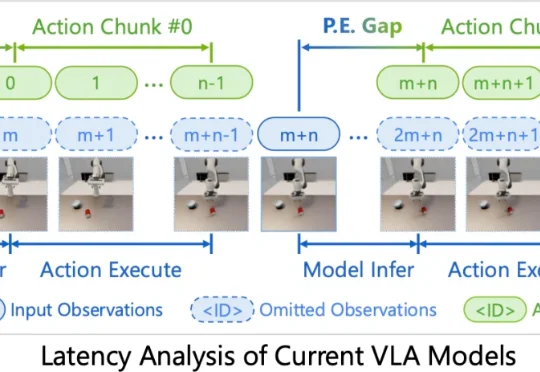
当物体在滚动、滑动、被撞飞,机器人还在执行几百毫秒前的动作预测。对动态世界而言,这种延迟,往往意味着失败。
准备回家过年了吗?有没有感觉今年回家比去年还堵?据说今年春运流量再创新高,官方预计40天内人员流动量将达95亿人次,其中多数人仍然选择自驾出行,占比达到了8成,人次超过70亿。

首个AI视频生成全球挑战赛来袭,袁粒、颜水成、程明明、田永鸿、Philip Torr多位大佬发起,20万大奖虚位以待!创作大神还是技术极客?两大赛道总有一个适合你,速速点击报名吧。
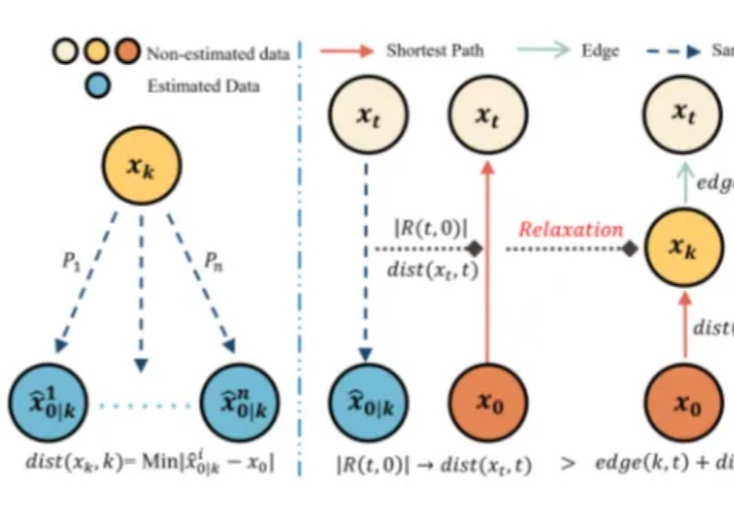
从“在线训练”到“离线建图”,扩散模型速度再突破!