
“3秒钟算出我前世是南宋第一女同?”免费的DeepSeek快被玩成算命宗师了
“3秒钟算出我前世是南宋第一女同?”免费的DeepSeek快被玩成算命宗师了今年爆火的国产AI应用DeepSeek化身最火爆的赛博算命师,各种东西方玄学,如《三命通会》、《滴天髓》、《渊海子平》这些你压根没听过的书籍,只需要它“深度思考”几秒钟就能手到擒来。
来自主题: AI资讯
8553 点击 2025-02-07 19:22
 搜索
搜索
今年爆火的国产AI应用DeepSeek化身最火爆的赛博算命师,各种东西方玄学,如《三命通会》、《滴天髓》、《渊海子平》这些你压根没听过的书籍,只需要它“深度思考”几秒钟就能手到擒来。
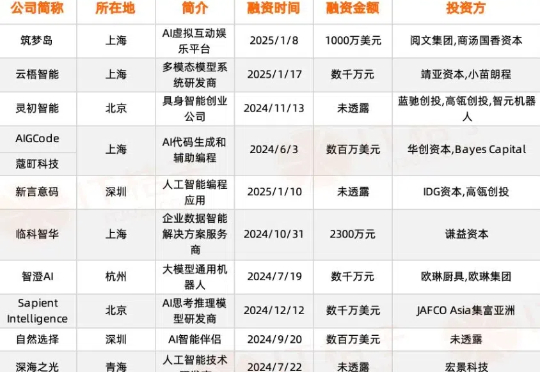
在整个春节期间,DeepSeek的一夜爆火令人印象深刻,无论公域还是私域场合都随处听到讨论它的声音。而我们注意到其开发商杭州深度求索人工智能基础技术研究有限公司是一家成立仅一年半的新公司 (背后的量化私募公司运营时间较久) 。
各位同学好,我是来自 Unlock-DeepSeek 开源项目团队的骆师傅。先说结论,我们(Datawhale X 似然实验室)使用 3 张 A800(80G) 计算卡,花了 20 小时训练时间,做出了可能是国内首批 DeepSeek R1 Zero 的中文复现版本,我们把它叫做 Datawhale-R1,用于 R1 Zero 复现教学。
阿里系第一个吃上DeepSeek“螃蟹”的出现了——钉钉:已经全面接入DeepSeek系列模型。现在,用户在钉钉上创建AI助理的时候,可以直接选择DeepSeek系列的R1、V3等三种模型!
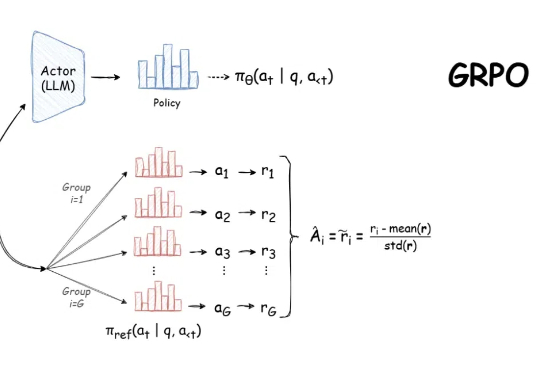
自 DeepSeek-R1 发布以来,群组相对策略优化(GRPO)因其有效性和易于训练而成为大型语言模型强化学习的热门话题。R1 论文展示了如何使用 GRPO 从遵循 LLM(DeepSeek-v3)的基本指令转变为推理模型(DeepSeek-R1)。
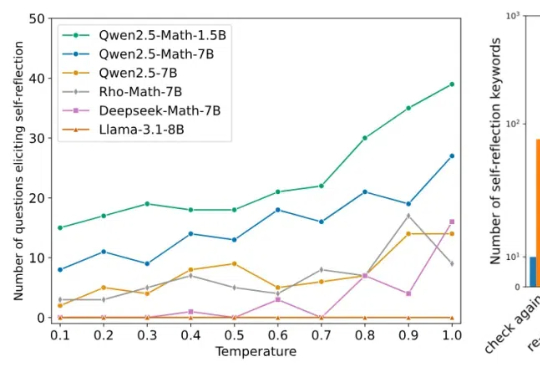
一项非常鼓舞人心的发现是:DeepSeek-R1-Zero 通过纯强化学习(RL)实现了「顿悟」。在那个瞬间,模型学会了自我反思等涌现技能,帮助它进行上下文搜索,从而解决复杂的推理问题。
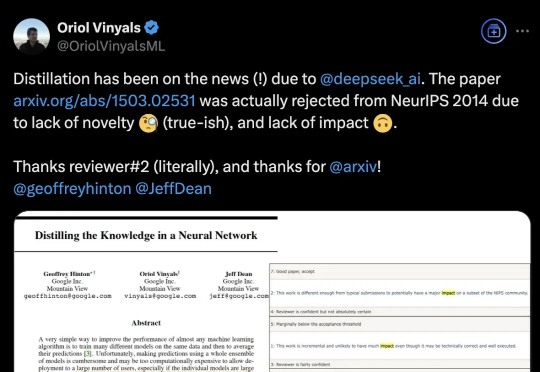
DeepSeek带火知识蒸馏,原作者现身爆料:原来一开始就不受待见。称得上是“蒸馏圣经”、由Hinton、Oriol Vinyals、Jeff Dean三位大佬合写的《Distilling the Knowledge in a Neural Network》,当年被NeurIPS 2014拒收。

2025年,软件工程要彻底变天了。先有奥特曼预言,后有微软下场All in智能体。刚刚,首个自主SWE智能体面世,不仅会主动改bug修复错误,还能自主提交PR评论。

有时,当某项技术变得更便宜时,反而会促使整体投入增加。我认为,从长期来看,人类对智能和算力的需求几乎没有上限,因此我仍然看好AI计算需求的持续增长。我认为DeepSeek-R1在地缘政治上的影响尚有待厘清,同时它也为AI应用开发者带来了巨大机遇。

春节假期后的港股市场迎来结构性行情,以AI大模型为核心的技术革命再次成为资金追逐焦点,这次的落脚点在AI应用的商业化之中。