不用App、不找占星师,年轻人正在用「复制粘贴」AI算命
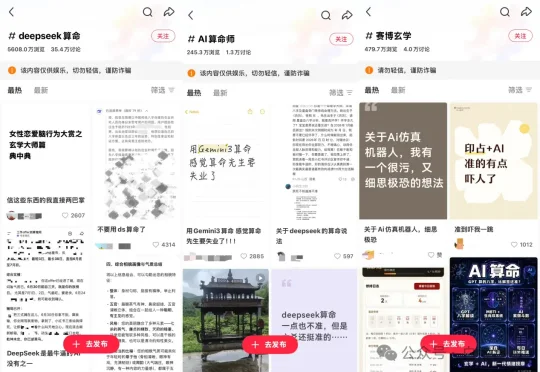
不用App、不找占星师,年轻人正在用「复制粘贴」AI算命小红书上,#deepseek 算命、#赛博玄学等话题下,大量玄学爱好者聚集,分享不同占卜体系的prompt、交流 AI 算命心得,仅 #deepseek 算命一个话题,浏览量就达到 5608 万、讨论量 35.4 万;与此同时,更深度的 AI 用户开始在 GitHub 上自行开发占卜 Skills,搜索“astrology”“bazi”等关键词,可以看到相关项目最高 Star 数已达 3.9k。
来自主题: AI资讯
8911 点击 2026-07-08 22:29