
一块4090搞定实时视频生成!Adobe黑科技来了
一块4090搞定实时视频生成!Adobe黑科技来了游戏直播等实时渲染门槛要被击穿了?Adobe 的一项新研究带来新的可能。
来自主题: AI技术研报
8169 点击 2025-06-10 16:52
 搜索
搜索
游戏直播等实时渲染门槛要被击穿了?Adobe 的一项新研究带来新的可能。

研究者针对 few-shot 图像编辑提出一个新的自回归模型结构 ——InstaManip,并创新性地提出分组自注意力机制(group self-attention),在此任务上取得了优异的效果。
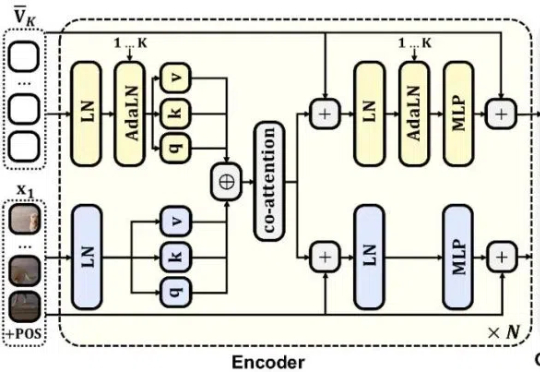
自回归(AR)范式凭借将语言转化为离散 token 的核心技术,在大语言模型领域大获成功 —— 从 GPT-3 到 GPT-4o,「next-token prediction」以简单粗暴的因果建模横扫语言领域。

不用引入外部数据,通过自我博弈(Self-play)就能让预训练大模型学会推理?
近日,以色列宣布与以色列AI“数字化身”制作平台eSelf、以色列最大的K12教科书出版商CET(Center for Educational Technology)合作,在全国范围内铺开AI辅导。

近日,来自香港科技大学、南洋理工大学等机构的研究团队最新成果让这一设想成为现实。他们提出的 SelfDefend 框架,让大语言模型首次拥有了真正意义上的 ' 自卫能力 ',能够有效识别和抵御各类越狱攻击,同时保持极低的响应延迟。
一位“出海老兵”的自救。

代码模型可以自己进化,利用自身生成的数据来进行指令调优,效果超越GPT-4o直接蒸馏!

自我纠错(Self Correction)能力,传统上被视为人类特有的特征,正越来越多地在人工智能领域,尤其是大型语言模型(LLMs)中得到广泛应用,最近爆火的OpenAI o1模型[1]和Reflection 70B模型[2]都采取了自我纠正的方法。

o1 模型何以成为企业游戏规则的改变者?