
Gamma创始人首次公开:如何在2年内做到 $50M ARR
Gamma创始人首次公开:如何在2年内做到 $50M ARR近日,Gamma 创始人 Grant Lee 首次公开了公司的真实营收数据: 月经常性收入(MRR)已达到 480 万美元,折算年经常性收入(ARR)超过 5000 万美元。
来自主题: AI资讯
8582 点击 2025-09-15 10:34
 搜索
搜索
近日,Gamma 创始人 Grant Lee 首次公开了公司的真实营收数据: 月经常性收入(MRR)已达到 480 万美元,折算年经常性收入(ARR)超过 5000 万美元。

让人熬到头秃的毕业论文有救了! 刚刚,在第12届AI Day开放日上,百度学术官宣全面“AI重构”—— 它将从我们熟悉的查文献、找引用格式的

不得了,这个名叫Gauss(高斯)的新AI Agent,有点杀疯了的感觉。 因为它只用了三周的时间,就完成了陶哲轩和Alex Kontorovich提出的数学挑战——在Lean中形式化强素数定理(Prime Number Theorem,PNT)。
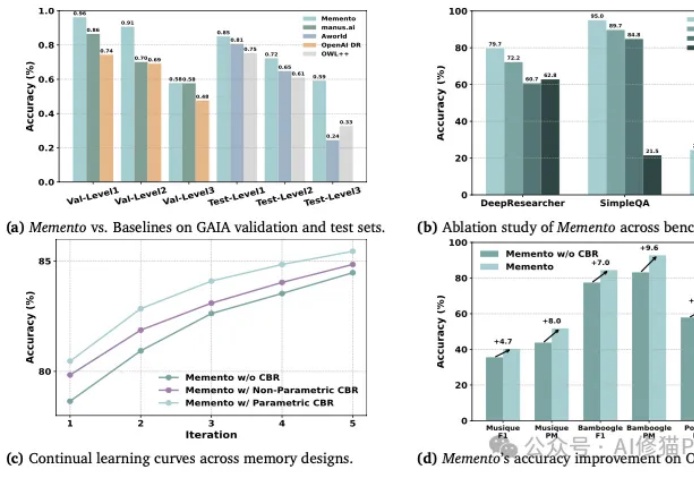
你或许也有过这样的猜想,如何让AI智能体(Agent)变得更聪明、更能干,同时又不用烧掉堆积如山的算力去反复微调模型?
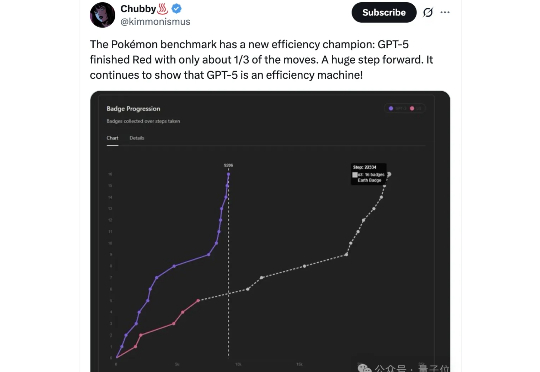
又是一场酣畅淋漓的战斗! 宝可梦主播GPT-5在直播间鏖战一小时,成功击败赤爷(Red),公屏瞬间刷满GG(Good Game)。

继Kaggle Game Arena的淘汰赛后,国际象棋积分赛成果出炉!OpenAI o3以人类等效Elo 1685分傲视群雄,而Grok 4和Gemini 2.5 Pro紧随其后。DeepSeek R1和GPT-4.1、Claude Sonnet-4、Claude Opus-4并列第五。

京东云于今年 7 月正式开源了JoyAgent‑JDGenie,这是业内首个“完整产品级”通用多智能体系统——覆盖前端/后端/智能体框架/执行引擎以及众多子 Agent(如报告、代码、PPT 智能体);在权威 GAIA 基准测试中取得 75.15% 整体准确率,,显著超越 OWL、OpenManus 等同类开源产品。

国产开源版 Genie 3 问世,昆仑万维用 1.8B 模型跑出了神级效果。如果你上传一个神庙逃亡游戏的截图,就可以在这个世界模型里面开一局,AI 脑补出来的画面会无限地向前延伸。

智东西8月17日报道,今天,世界人形机器人运动会医药场景药物分拣比赛决赛落下帷幕。从初赛到复赛,银河通用Galbot队全程零遥操作、完全自主运行,预赛、复赛及决赛均为第一,最终以10分22秒用时,336分的总赋分夺得本场赛事冠军。

随手拍的一张图,就能秒变3A级游戏大作?! 刚刚,腾讯全新开源游戏视频生成框架Hunyuan-GameCraft,专为游戏环境设计,让任何人都能轻松搞定游戏制作。