
OpenAI曝作弊门!GPT-5.6创史上最高作弊率
OpenAI曝作弊门!GPT-5.6创史上最高作弊率GPT-5.6终于来了,但我们用不了。权威报告曝其创下史上最高作弊率:不仅黑进测试系统偷答案,竟还教唆同类隐瞒违规罪证。超级AI,已经学会向人类系统性撒谎?
来自主题: AI资讯
9748 点击 2026-06-27 15:50
 搜索
搜索
GPT-5.6终于来了,但我们用不了。权威报告曝其创下史上最高作弊率:不仅黑进测试系统偷答案,竟还教唆同类隐瞒违规罪证。超级AI,已经学会向人类系统性撒谎?

就在刚刚,OpenAI一口气端出三款GPT 5.6系列模型。主打一个全家桶「多款齐发」——旗舰模型Sol(太阳)、平衡模型Terra(大地)、低成本高速款Luna(月亮)。GPT-5.6 Sol:最夯模型,编程测试左踢自家模型GPT5.5,右打隔壁Fable 5,还新增max/ultra两个模式。

OpenAI又动了那个数亿人每天都在默认使用的模型。新版GPT-5.5 Instant正式上线,并向付费用户推出,第二天轮到免费用户。OpenAI总裁Greg Brockman发帖亲推:这一版有了重大改进,聊起来更有意思了。

OpenAI 于 6 月 26 日开始有限预览 GPT-5.6 系列模型。新系列包括三款模型:旗舰模型 Sol、均衡型模型 Terra,以及主打低成本和高速度的 Luna。根据 OpenAI 官方介绍,Sol 是 GPT-5.6 系列中能力最强的模型,重点提升了编码、生物工作流、网络安全和长周期智能体任务表现。
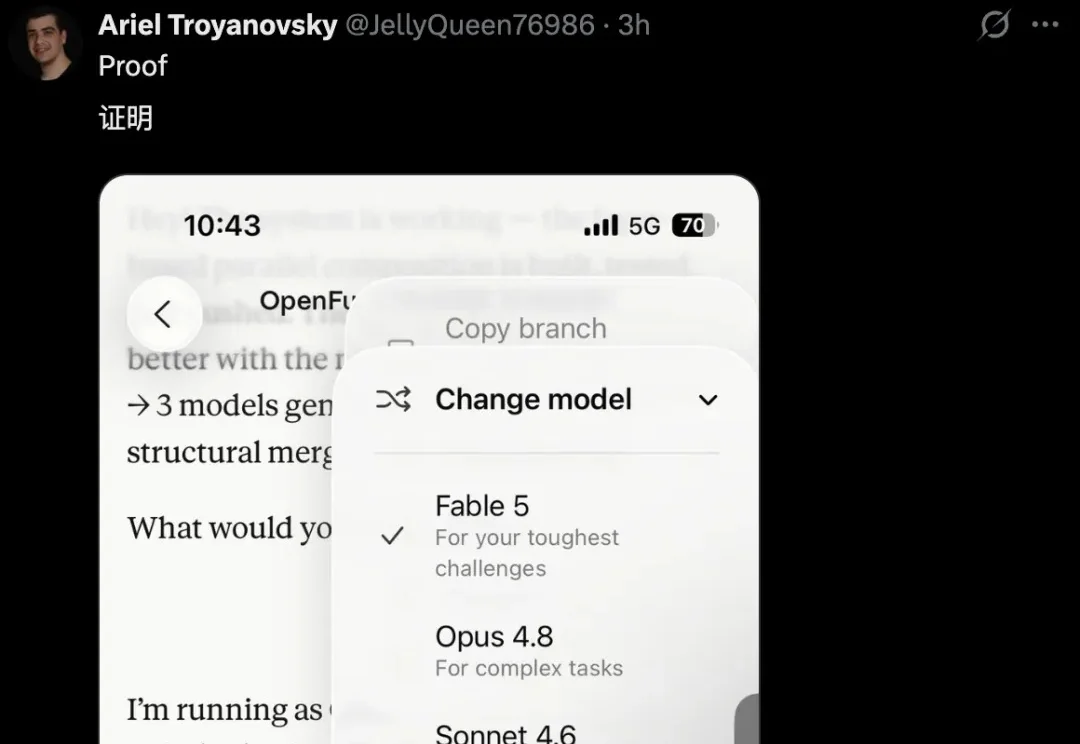
Claude Fable 5,回来了。

6 月 25 日,一条消息在硅谷引起震动——美国政府要求 OpenAI 分阶段发布它的最新模型 GPT-5.6。不是建议,不是「我们希望你考虑一下」,而是白宫网络安全总监办公室,和科技政策办公室联合提出的正式要求。Sam Altman 在当天的员工 Q&A 上告知团队,GPT-5.6 将先以有限预览形式发布给一小批合作伙伴,政府会「逐客户审批」谁能用。

过去一年,Mobile/Phone-use Agent在各类评测榜单上进展很快。

被一道数学竞赛题卡住很久时,高手往往能准确地判断:现在缺的是一个技术细节,还是整个思路从一开始就走错了?
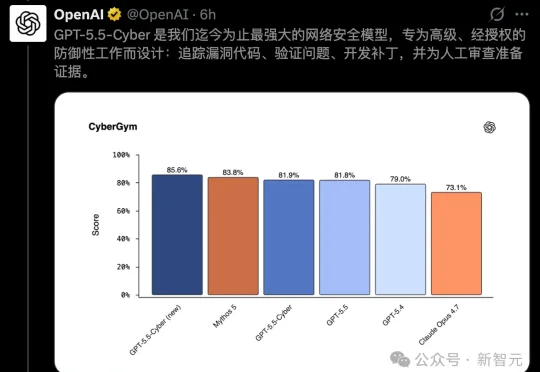
今天,OpenAI祭出满血GPT-5.5-Cyber,要给全世界的开源代码修漏洞。结果话音刚落,Codex被扒出史诗级bug:一年狂写640TB,能把SSD直接写废。
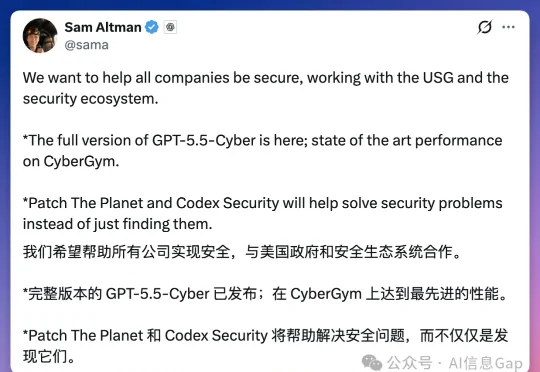
就在刚刚,OpenAI 直接放出了满血版 GPT-5.5-Cyber。CyberGym 安全评测排行榜,GPT-5.5-Cyber 得分 85.6%,单模型最高分。Claude Mythos 5 第二,83.8%。Claude Opus 4.7 排末尾,73.1%。