
入职第三年,团队连斩CVPR三奖:南加州王越的PSI Lab做对了什么?
入职第三年,团队连斩CVPR三奖:南加州王越的PSI Lab做对了什么?在南加州大学,王越的 PSI Lab(Physical Superintelligence Lab)是过去两三年里具身智能方向上升最快的年轻团队之一。
来自主题: AI资讯
10645 点击 2026-06-09 14:52
 搜索
搜索
在南加州大学,王越的 PSI Lab(Physical Superintelligence Lab)是过去两三年里具身智能方向上升最快的年轻团队之一。
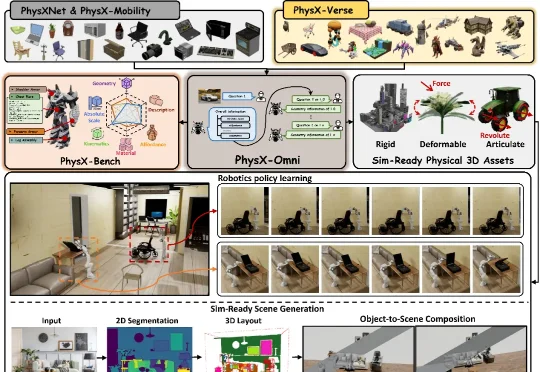
该论文第一作者为曹子昂,研究方向主要聚焦于 3D AIGC、Physical AI 与具身智能。论文主要合作者包括来自南洋理工大学的李海天、姚润茂、洪方舟、陈昭熹,以及大晓机器人的刘英豪和潘亮。通讯作者为南洋理工大学刘子纬教授。
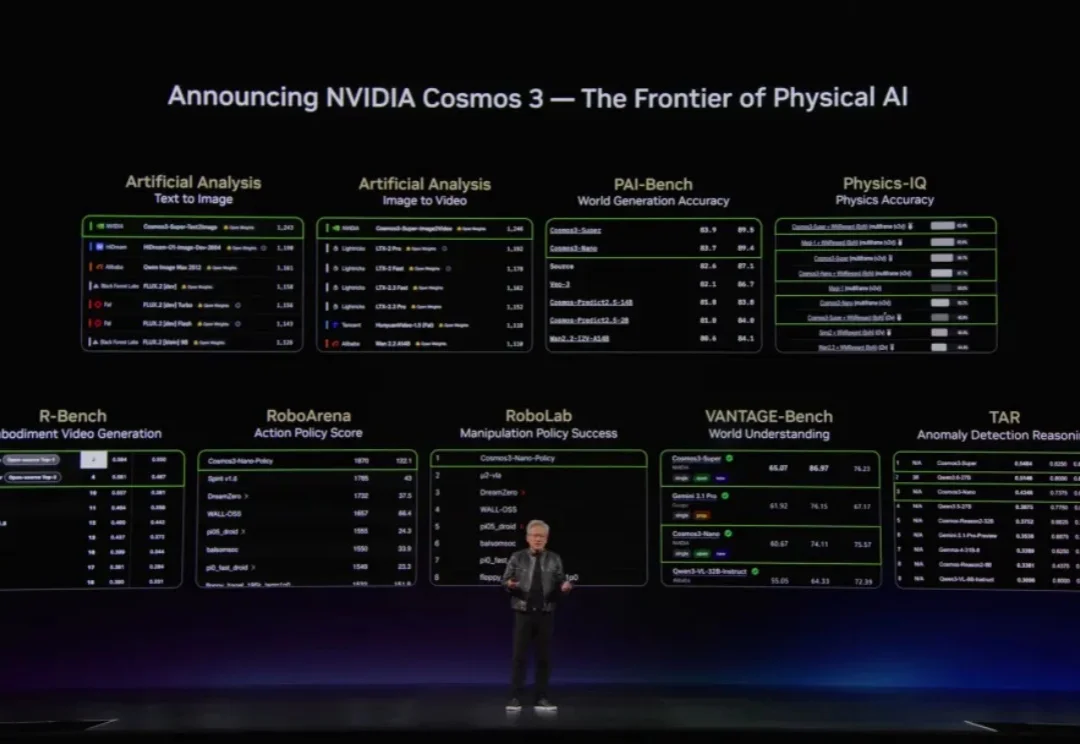
6 月 1 日,老黄在 GTC 上用了不小的篇幅讲物理 AI 和具身智能,并重磅发布了 Cosmos 3。英伟达将其定义为面向 Physical AI 的最新前沿模型,也是全球首个完全开放的全能模型,原生具备视觉推理、世界生成和动作生成能力。

8.99万元操作天花板,6月发货,具身智能的「苹果时刻」!中国版Figure,星尘智能自研「AI模型-具身OS-绳驱本体」三位一体架构,用击穿底线的定价,推动Physical AI落地。一句话:今年必Buy!

过去几年,大模型竞争主要发生在 AI 公司之间。但随着 AI 开始从数字世界进入真实设备与物理世界,竞争逻辑正在发生变化。

Agent Skills不应该只以SKILL.md、README或自然语言说明文档的形式存在,而应该被转成一种机器可检索、可检查、可治理的结构化表示。这是《From Skill Text to Skill Structure: The Scheduling-Structural-Logical Representation for Agent Skills》这篇论文的核心主张。

来自华为泰勒实验室、北京大学和上海财经大学的研究团队提出了 SHAPE(Stage-aware Hierarchical Advantage via Potential Estimation),给推理链装上了一套「里程碑 + 推理税」机制——不仅告诉模型每一步推得对不对,还让它为啰嗦付出代价。结果是:准确率平均提升 3%,token 消耗直降 30%。

AI科技评论独家获悉,卡内基梅隆⼤学机器⼈研究院(CMURI)博⼠后、悉尼⼤学(USYD)⻓聘助理教授WilliamZhi联合创办具⾝智能公司⸺ZenoAI(芝诺机器⼈),致⼒于打造通⽤全栈物理智能(Full-stackPhysicalAI),提供可靠的全⾝灵巧操作解决⽅案。

如何创建大规模的Physical AI数据,来加速Physical AI开发者的进展。我们采取的方法,本质上是用算力去换数据;
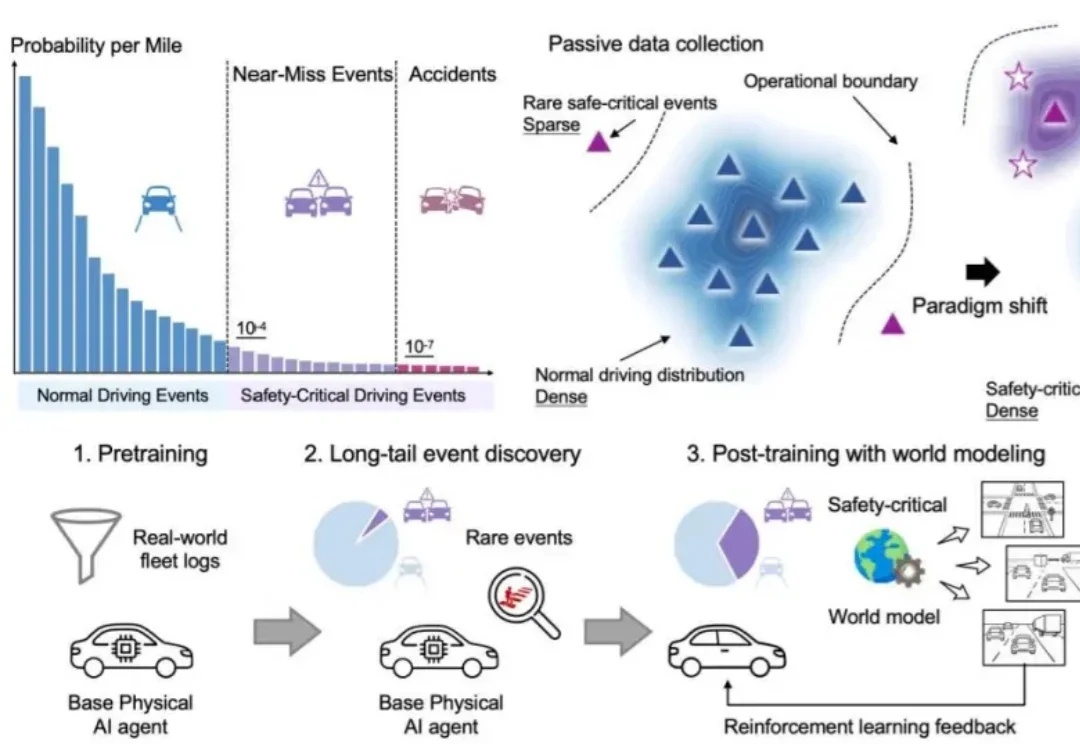
一年前,DeepSeek R1 横空出世,人们才意识到,真正让模型产生推理能力质变的,不必是更大的预训练规模 —— 后训练,用强化学习、过程奖励、闭环反馈,以极低的代价解锁了原本需要数倍算力才能触达的能力边界。