ICLR 2026 | 帝国理工大学提出DyMo:让多模态模型学会「选择」,突破模态缺失难题
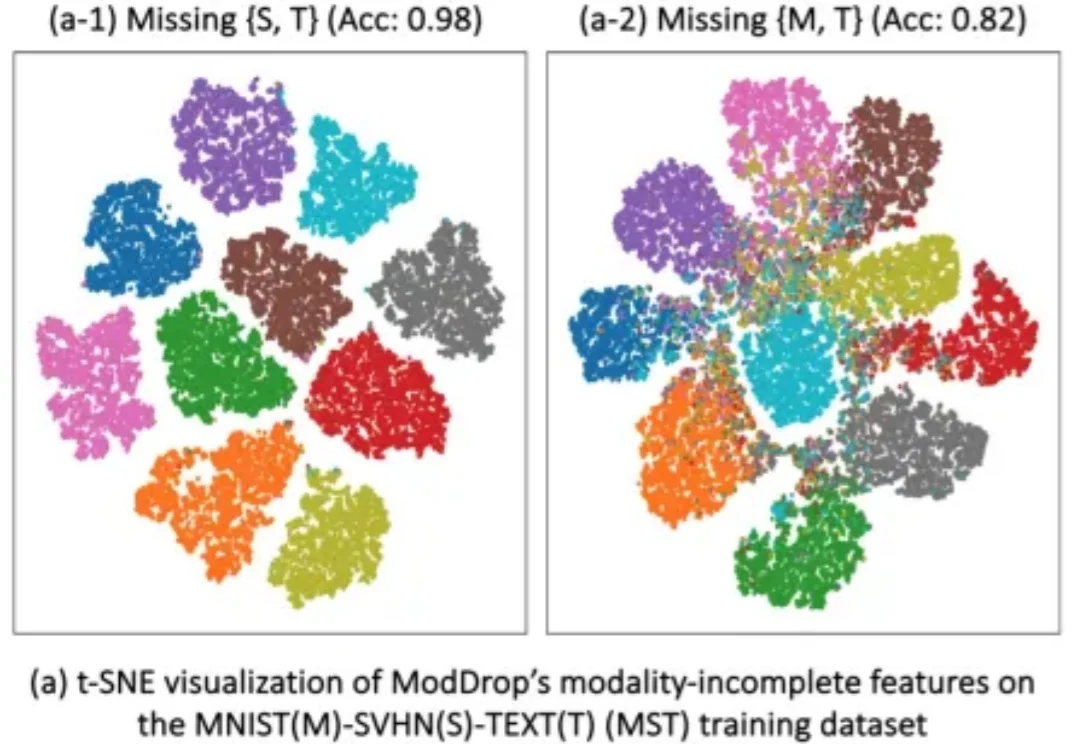
ICLR 2026 | 帝国理工大学提出DyMo:让多模态模型学会「选择」,突破模态缺失难题多模态学习(Multimodal Learning)正在推动 AI 在医学影像、自动驾驶、人机交互等领域取得突破。通过融合图像、文本、表格等多种模态,模型能够获得更全面的信息,从而显著提升性能。
来自主题: AI技术研报
9567 点击 2026-03-09 14:28
 搜索
搜索
多模态学习(Multimodal Learning)正在推动 AI 在医学影像、自动驾驶、人机交互等领域取得突破。通过融合图像、文本、表格等多种模态,模型能够获得更全面的信息,从而显著提升性能。

十亿参数的三维重建模型,能塞进手机吗?

AI 搜索引擎正逐渐取代传统搜索入口,「问 AI」已经成为日常习惯。随着 OpenAI 宣布在 ChatGPT 中引入商业推荐,搜索与内容分发的边界正在被重新定义。在这样的环境下,你的内容能否在 AI 搜索中成为「爆款」,不再只取决于标题和流量,而是更大程度取决于 AI 本身的引用偏好。
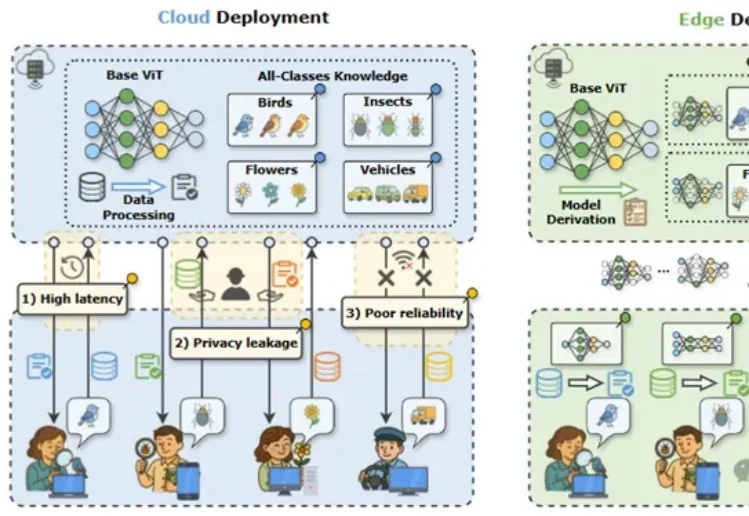
近年来,视觉大模型在自动驾驶、智慧医疗等场景中得到广泛应用,但在真实业务环境中,“大而全”的通用模型往往并不是最优选择。
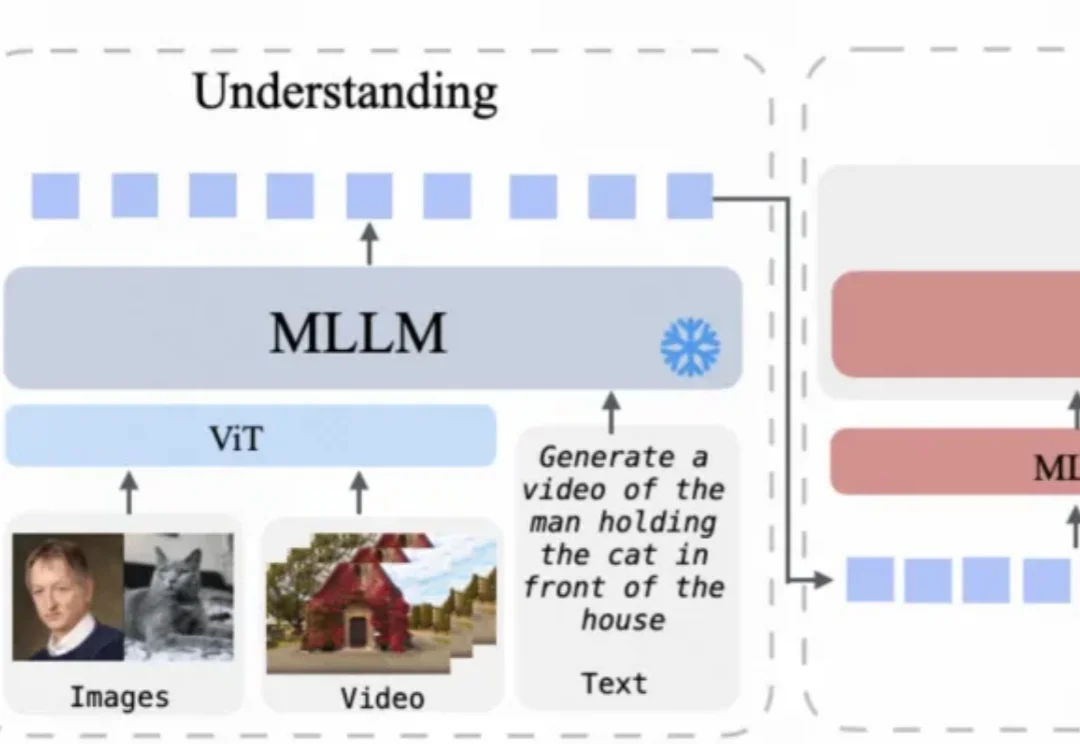
统一多模态模型在多模态内容理解与生成方面已展现出良好效果,但目前仍主要局限于图像领域。

长期以来,计算机视觉领域陷入了一个 “表征(Representation)” 的执念。我们习惯设计各种精巧的 Encoder,试图将动态世界压缩成一组特征向量。然而,视频作为现实的高维投影,其熵值之高、动态之复杂,让这种试图 “定格” 的表征显得力不从心。

全新的具身模型空间能力评估范式 Theory of Space 突破了传统静态图文问答的局限,系统性地考察基础模型能否像人一样,在部分可观测的动态环境中,通过自主探索来构建、修正和利用空间信念。该论文已被 ICLR 2026 接收。
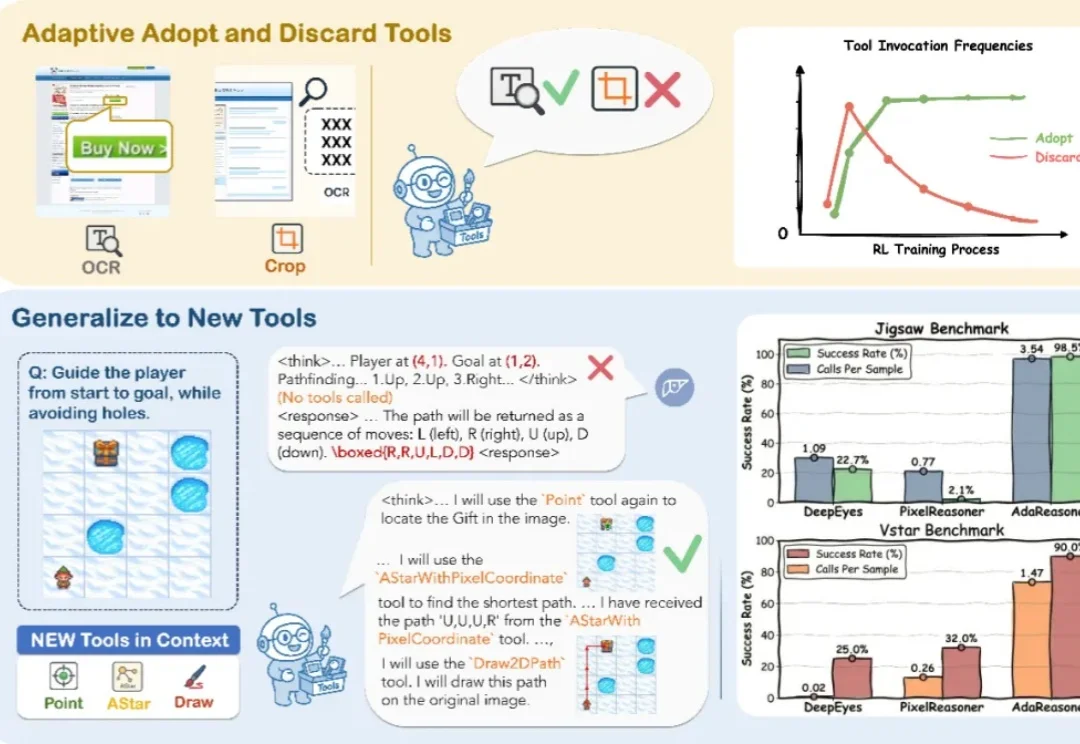
你见过 7B 模型在拼图推理上干翻 GPT-5 吗?
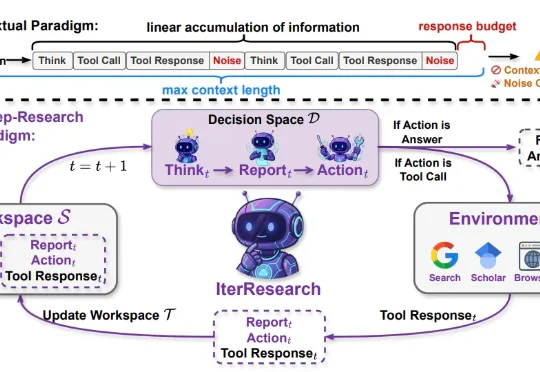
来自中国人民大学与阿里巴巴通义实验室的研究团队提出了 IterResearch,一种全新的迭代式深度研究范式。通过马尔可夫式的工作空间重构,IterResearch 让 Agent 在仅 40K 上下文长度下完成了 2048 次工具交互且性能不衰减,在 BrowseComp 上从 3.5% 一路攀升至 42.5%。
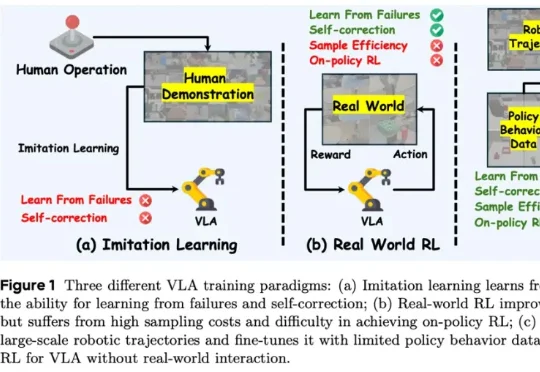
香港科技大学 PEI-Lab 与字节跳动 Seed 团队近期提出的 WMPO(World Model-based Policy Optimization),正是这样一种让具身智能在 “想象中训练” 的新范式。该方法无需在真实机器人上进行大规模强化学习交互,却能显著提升策略性能,甚至涌现出 自我纠错(Self-correction) 行为。