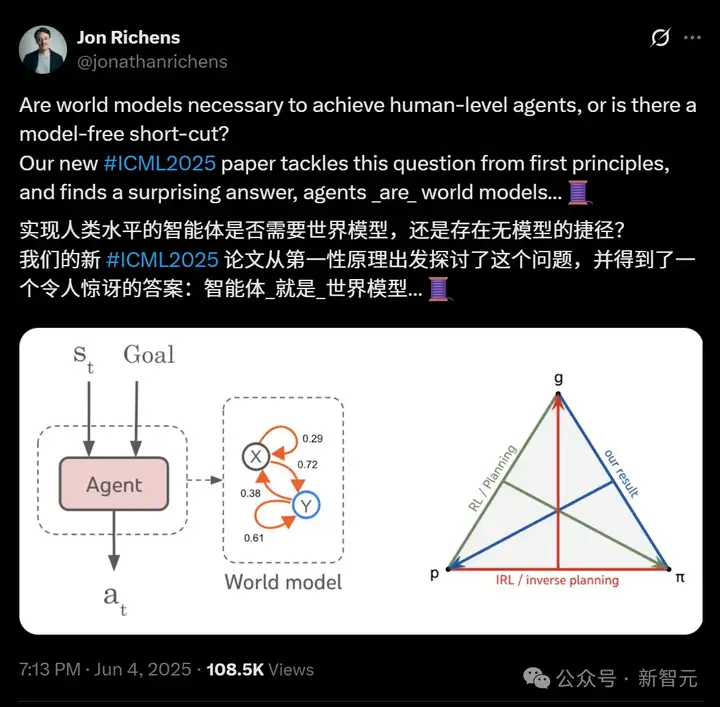
DeepMind揭惊人答案:智能体就是世界模型!跟Ilya 2年前预言竟不谋而合
DeepMind揭惊人答案:智能体就是世界模型!跟Ilya 2年前预言竟不谋而合就在刚刚,DeepMind科学家Jon Richens表示,自己的一篇ICML 2025论文发现,智能体就是世界模型!总之,如果要实现AGI,是绝对不存在无模型的捷径的。而这个说法,恰巧跟Ilya 23年的预言不谋而合了。
来自主题: AI资讯
8734 点击 2025-06-06 12:15
 搜索
搜索
就在刚刚,DeepMind科学家Jon Richens表示,自己的一篇ICML 2025论文发现,智能体就是世界模型!总之,如果要实现AGI,是绝对不存在无模型的捷径的。而这个说法,恰巧跟Ilya 23年的预言不谋而合了。

本研究由广州趣丸科技团队完成,团队长期致力于 AI 驱动的虚拟人生成与交互技术,相关成果已应用于游戏、影视及社交场景

在多智能体AI系统中,一旦任务失败,开发者常陷入「谁错了、错在哪」的谜团。PSU、杜克大学与谷歌DeepMind等机构首次提出「自动化失败归因」,发布Who&When数据集,探索三种归因方法,揭示该问题的复杂性与挑战性。
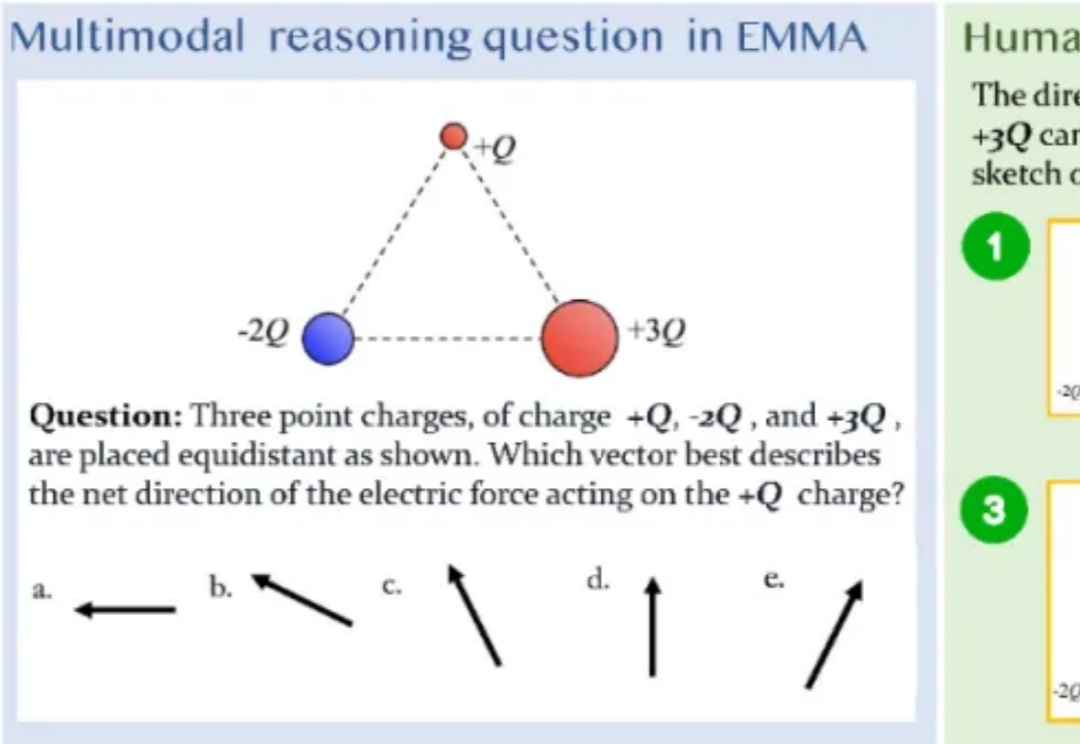
「三个点电荷 + Q、-2Q 和 + 3Q 等距放置,哪个向量最能描述作用在 + Q 电荷上的净电力方向?」
本文作者分别来自中国科学院大学和中国科学院计算技术研究所。第一作者裴高政为中国科学院大学博士二年级学生,本工作共同通讯作者是中国科学院大学马坷副教授和黄庆明教授。
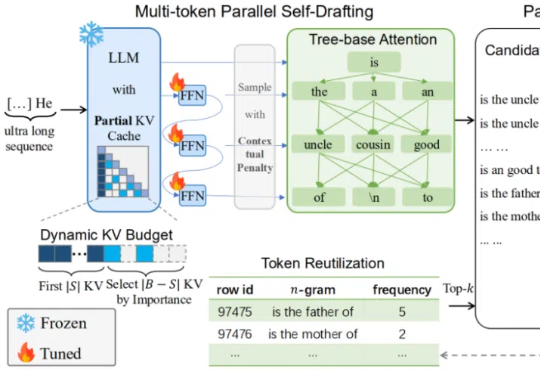
在当前大模型推理愈发复杂的时代,如何快速、高效地产生超长文本,成为了模型部署与优化中的一大核心挑战。
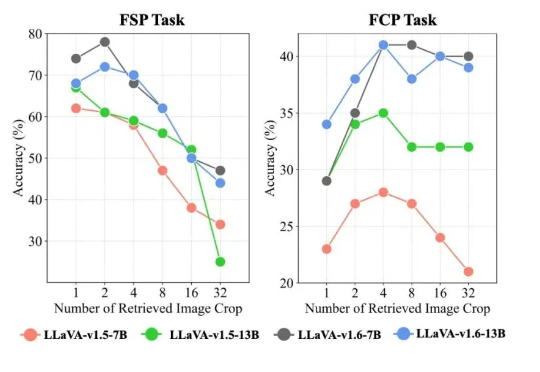
该工作由南洋理工大学陶大程教授团队与武汉大学罗勇教授、杜博教授团队等合作完成。
空间音频,作为一种能够模拟真实听觉环境的技术,正逐渐成为提升沉浸式体验的关键。
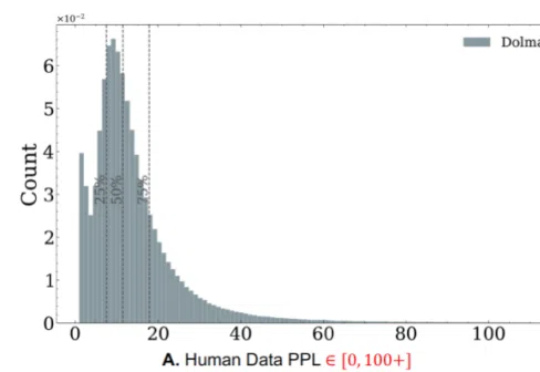
随着生成式人工智能技术的飞速发展,合成数据正日益成为大模型训练的重要组成部分。未来的 GPT 系列语言模型不可避免地将依赖于由人工数据和合成数据混合构成的大规模语料。

开发能在开放世界中完成多样任务的通用智能体,是AI领域的核心挑战。开放世界强调环境的动态性及任务的非预设性,智能体必须具备真正的泛化能力才能稳健应对。然而,现有评测体系多受限于任务多样化不足、任务数量有限以及环境单一等因素,难以准确衡量智能体是否真正「理解」任务,或仅是「记住」了特定解法。