
实时监测全球媒体热点,还有比Grok AI更好用的工具吗?
实时监测全球媒体热点,还有比Grok AI更好用的工具吗?Grok AI 最近网页版刚刚上线。我看到不少人都在比较 Grok 对标 ChatGPT 等等 LLM 大模型的研究和生成能力。我想说,背靠 X (前推特)数据库的 Grok AI,最好的使用方式难道不是实时监测全球媒体热点吗?
来自主题: AI资讯
8535 点击 2025-01-21 10:05
Grok AI 最近网页版刚刚上线。我看到不少人都在比较 Grok 对标 ChatGPT 等等 LLM 大模型的研究和生成能力。我想说,背靠 X (前推特)数据库的 Grok AI,最好的使用方式难道不是实时监测全球媒体热点吗?
AI编程蓝皮书火了,发布3天,阅读量超过3万!
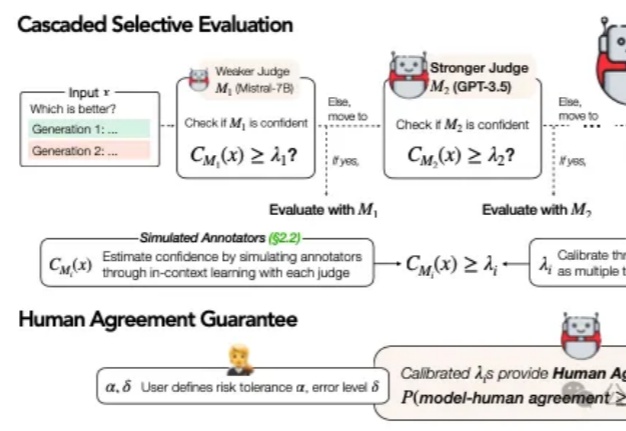
在当今AI技术迅猛发展的背景下,大语言模型(LLM)的评估问题已成为一个不可忽视的挑战。传统的做法是直接采用最强大的模型(如GPT-4)进行评估,这就像让最高法院的大法官直接处理所有交通违章案件一样,既不经济也不一定总能保证公正。

2024又是AI精彩纷呈的一年。LLM不再是AI舞台上唯一的主角。随着预训练技术遭遇瓶颈,GPT-5迟迟未能问世,从业者开始从不同角度寻找突破。以o1为标志,大模型正式迈入“Post-Training”时代;开源发展迅猛,Llama 3.1首次击败闭源模型;中国本土大模型DeepSeek V3,在GPT-4o发布仅7个月后,用 1/10算力实现了几乎同等水平。

大型语言模型(LLMs)能够解决研究生水平的数学问题,但今天的搜索引擎却无法准确理解一个简单的三词短语。
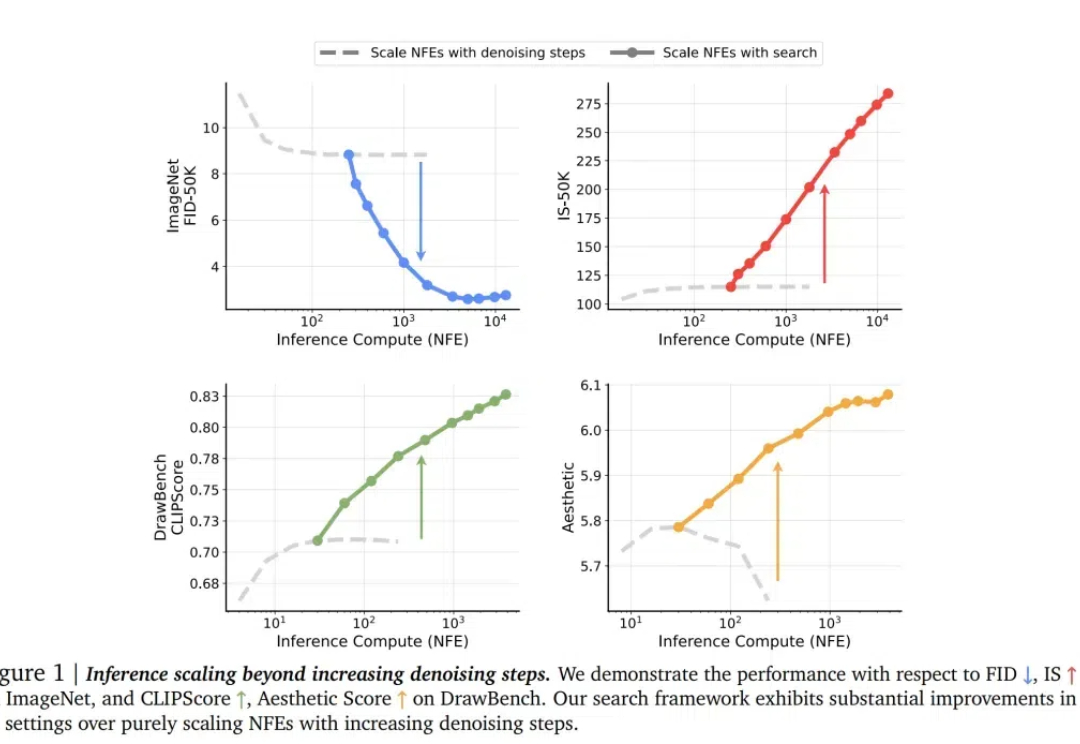
对于 LLM,推理时 scaling 是有效的!这一点已经被近期的许多推理大模型证明:o1、o3、DeepSeek R1、QwQ、Step Reasoner mini……

在人工智能快速发展的今天,大型语言模型(LLM)在各类任务中展现出惊人的能力。然而,当面对需要复杂推理的任务时,即使是最先进的开源模型也往往难以保持稳定的表现。现有的模型集成方法,无论是在词元层面还是输出层面的集成,都未能有效解决这一挑战。

Sakana AI发布了Transformer²新方法,通过奇异值微调和权重自适应策略,提高了LLM的泛化和自适应能力。新方法在文本任务上优于LoRA;即便是从未见过的任务,比如MATH、HumanEval和ARC-Challenge等,性能也都取得了提升。
自适应 LLM 反映了神经科学和计算生物学中一个公认的原理,即大脑根据当前任务激活特定区域,并动态重组其功能网络以响应不断变化的任务需求。
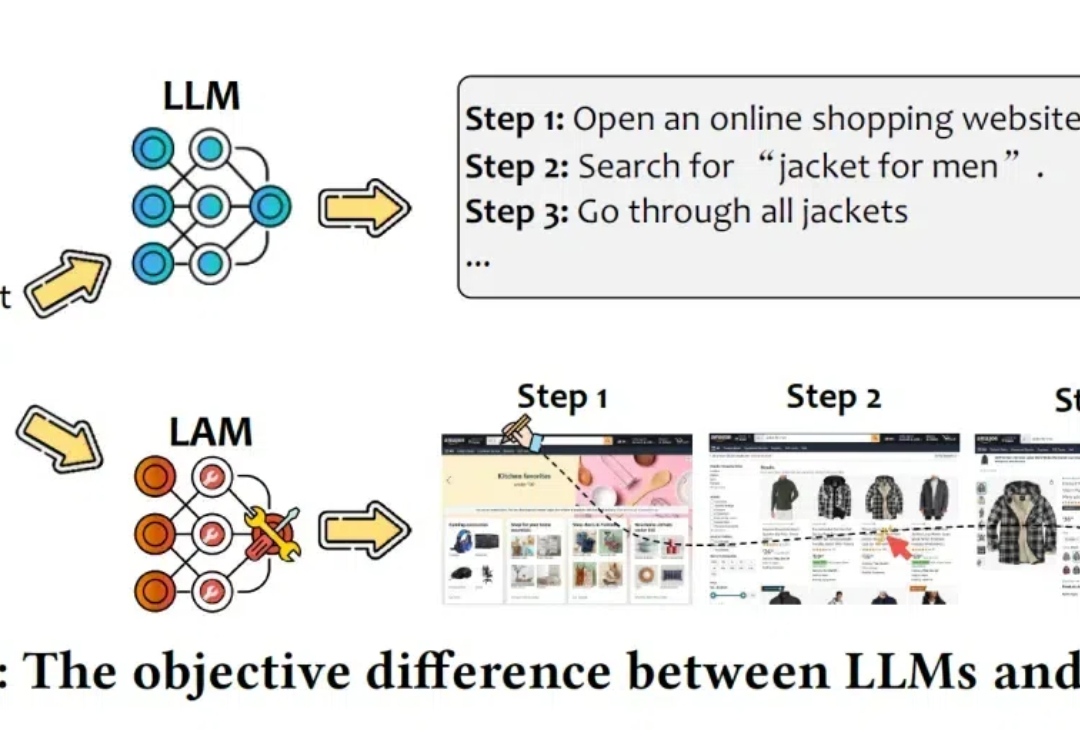
AI大模型正从仅会聊天的LLM进化为能够执行任务的大型行动模型LAM。它不仅能理解用户的指令,还能在软件环境中自主执行任务。