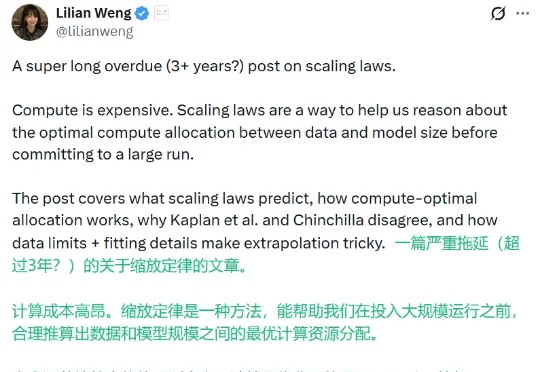
刚刚,翁荔博客上新:谨慎对待Scaling Law
刚刚,翁荔博客上新:谨慎对待Scaling Law刚刚,翁荔(Lilian Weng)的博客 Lil'Log 终于更新了!要知道,自从她联合创立了 Thinking Machines Lab 之后,她那让许多人受益良多的博客就鲜少更新了——距离她上一次更新,已经过去了 13 个月。
来自主题: AI技术研报
9957 点击 2026-06-26 11:14
 搜索
搜索
刚刚,翁荔(Lilian Weng)的博客 Lil'Log 终于更新了!要知道,自从她联合创立了 Thinking Machines Lab 之后,她那让许多人受益良多的博客就鲜少更新了——距离她上一次更新,已经过去了 13 个月。
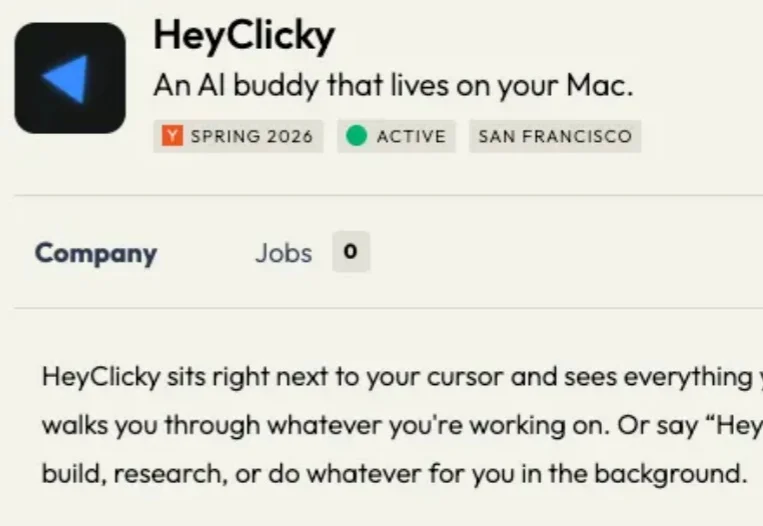
HeyClicky 做的是一个 Mac 上的 AI 桌面助手。

过去一个多月,大模型圈依旧热闹。从 GPT-5.5、DeepSeek V4 到 Claude Opus 4.8,后训练正在成为模型能力提升的关键引擎。

致力于成为金融界“DeepSeek”。金融垂域大模型公司Grace Investment Machine(简称GIM)宣布一连完成过亿元天使轮和天使+轮融资。成立于2025年7月,GIM正在做一件事:为金融行业打造一个垂直领域的DeepSeek——专为投资决策而生的推理大模型。

在具身智能训练中,“把计算全部塞进GPU”似乎成了唯一的提速密码,机器人运控并行训练的框架,IsaacLab、MuJoCoPlayground、mjlab都默认遵循这一范式,这些系统都牢牢绑定在NVIDIA生态中。
英伟达版Macbook Pro,真的要来了。

今天,扣子 3.0 正式上线,扣子手机端 (iOS / Android)、电脑端(Mac OS / Windows)、网页端(coze.cn)三端全量更新。这一次,扣子带来了全新电脑端,扣子 App 也全面升级,我们把 Agent 带进了更完整的工作现场:
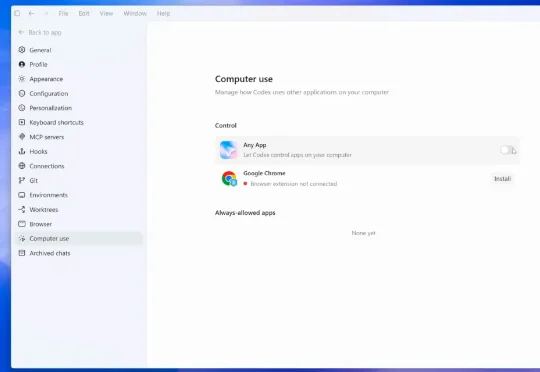
Codex ,现在就是 OpenAI 最好用的产品,没有之一。APPSO 最近也出过好几期关于 Codex 的指南,每次留言区总有一批用户却对 Codex 十分不满,那就是 Windows 用户。
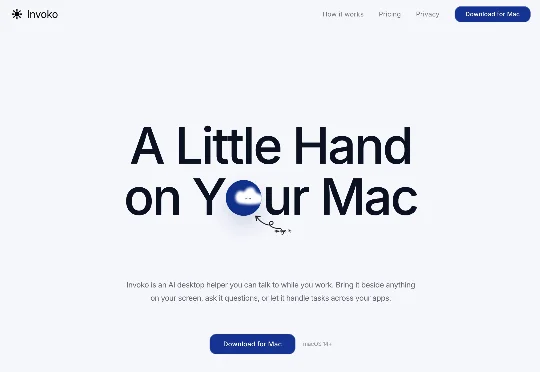
SophiaPro 成立于 2025 年 6 月。 最早,他们做的是一款叫 Karis.im 的 ToB 产品,给出海企业提供市场营销数字员工。后来转向 C 端产品,先是做了浏览器插件 TryClico,最近又推出了桌面端产品 Invoko.ai,一个长在 Mac 灵动岛位置的 notch 工具,帮用户在不同 app 之间自由切换上下文。
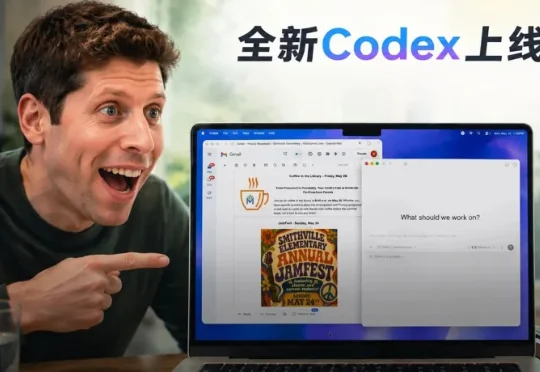
OpenAI凌晨又拉满了狂更模式!全新Codex发布:双击Command一键读通全屏隐藏文本、/goal自主编码正式毕业。最绝的是,Mac锁屏,AI也能隔空打工了。