2026年最"无聊"的AI商业模式,为什么反而最赚钱
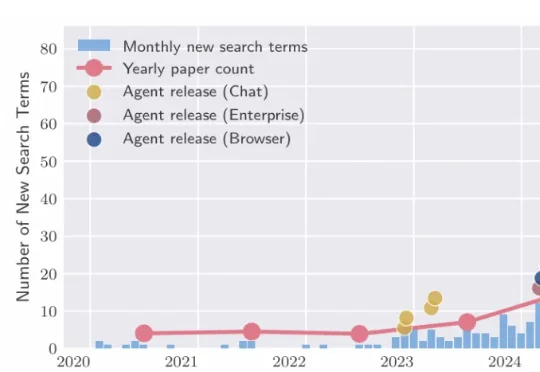
2026年最"无聊"的AI商业模式,为什么反而最赚钱Ben在视频中提到了一个令人震惊的数据对比。虽然ChatGPT的使用率在飞速增长,企业也在疯狂尝试各种AI解决方案,但真正能看到商业价值的却少之又少。根据MIT的研究,在供应商销售的AI解决方案中,只有5%的试点项目最终进入了生产环境。Deloitte(德勤)发现只有15%的组织表示他们从AI中获得了显著的、可衡量的ROI。
来自主题: AI技术研报
10173 点击 2026-03-12 11:23