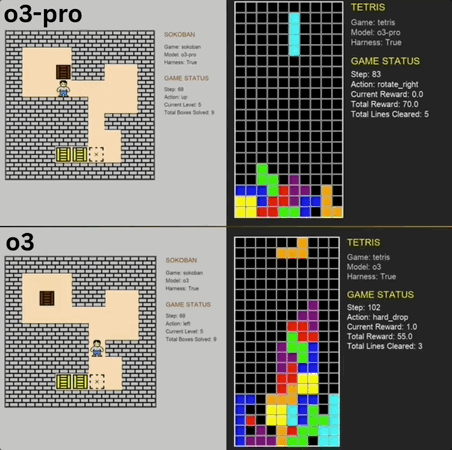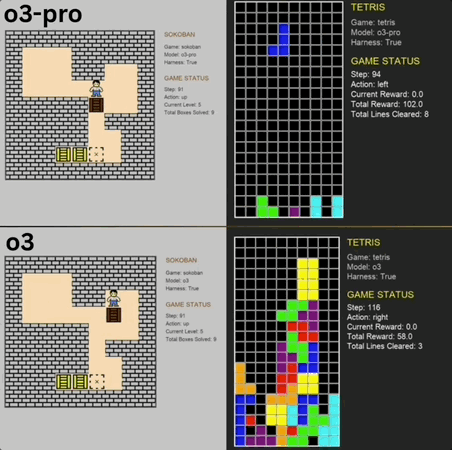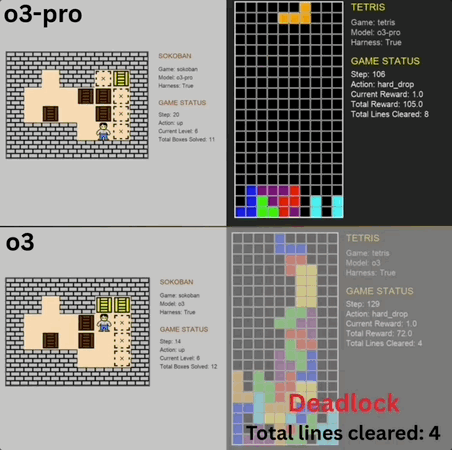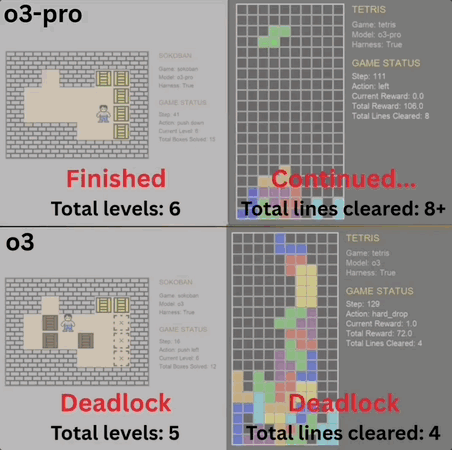
5人团队,1700万融资,现金流为正,继Reducto获Benchmark 2450万投资后,文档处理赛道又迎来重量级玩家
5人团队,1700万融资,现金流为正,继Reducto获Benchmark 2450万投资后,文档处理赛道又迎来重量级玩家你有没有想过,为什么在这个云计算和AI横行的时代,PDF文档处理依然是企业最大的痛点之一?想象一下这样的场景:一份包含数百页的贷款申请文档躺在银行系统里,等待人工审核,而申请人只能苦苦等待几天甚至几周才能知道结果。与此同时,医院里的医疗记录还在用打印机输出,然后手工传递给下一个医生。
来自主题: AI资讯
8327 点击 2025-07-01 11:03