科研写作神器,超越Mathpix的科学公式提取工具已开源
科研写作神器,超越Mathpix的科学公式提取工具已开源LaTeX 公式的光学字符识别(OCR)是科学文献数字化与智能处理的基础环节,尽管该领域取得了一定进展,现有方法在真实科学文献处理时仍面临诸多挑战:
来自主题: AI技术研报
8164 点击 2025-08-06 12:56
 搜索
搜索
LaTeX 公式的光学字符识别(OCR)是科学文献数字化与智能处理的基础环节,尽管该领域取得了一定进展,现有方法在真实科学文献处理时仍面临诸多挑战:
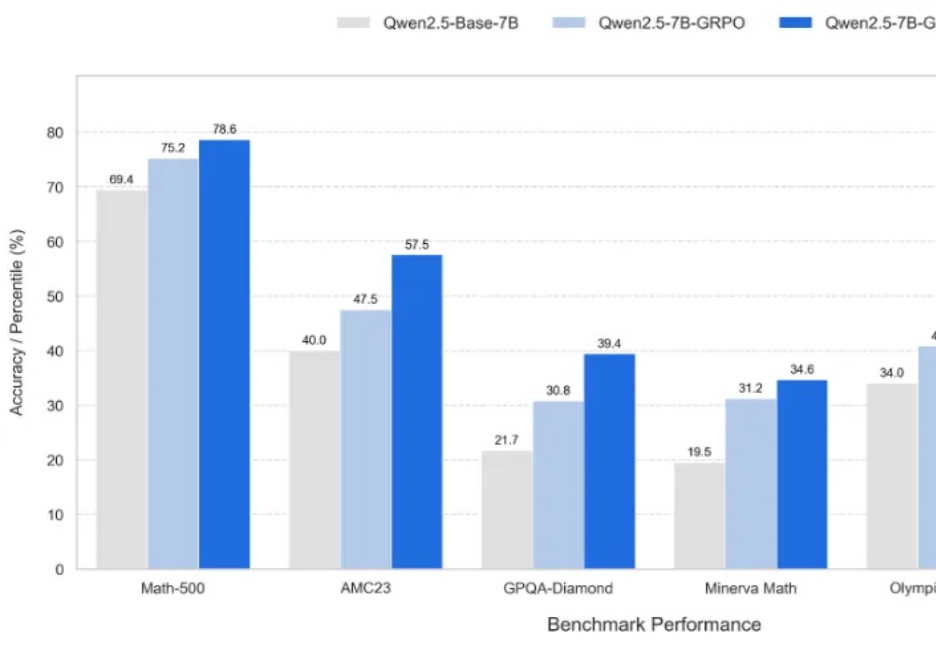
新一代大型推理模型,如 OpenAI-o3、DeepSeek-R1 和 Kimi-1.5,在复杂推理方面取得了显著进展。该方向核心是一种名为 ZERO-RL 的训练方法,即采用可验证奖励强化学习(RLVR)逐步提升大模型在强推理场景 (math, coding) 的 pass@1 能力。
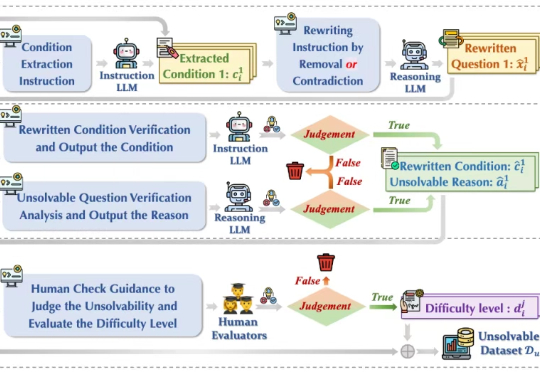
今年初以 DeepSeek-r1 为代表的大模型在推理任务上展现强大的性能,引起广泛的热度。然而在面对一些无法回答或本身无解的问题时,这些模型竟试图去虚构不存在的信息去推理解答,生成了大量的事实错误、无意义思考过程和虚构答案,也被称为模型「幻觉」 问题,如下图(a)所示,造成严重资源浪费且会误导用户,严重损害了模型的可靠性(Reliability)。
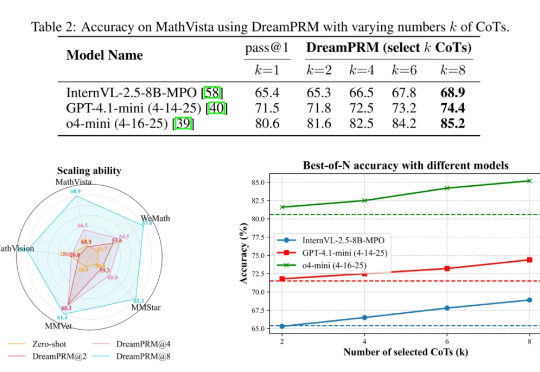
使用过程奖励模型(PRM)强化大语言模型的推理能力已在纯文本任务中取得显著成果,但将过程奖励模型扩展至多模态大语言模型(MLLMs)时,面临两大难题:

大语言模型在数学证明中常出现推理漏洞,如跳步或依赖特殊值。斯坦福等高校团队提出IneqMath基准,将不等式证明拆解为可验证的子任务。结果显示,模型的推理正确率远低于答案正确率,暴露出其在数学推理上的缺陷。
大语言模型解决不等式证明问题时,可以给出正确答案,但大多数时候是靠猜。推理过程经不起推敲,逻辑完全崩溃。
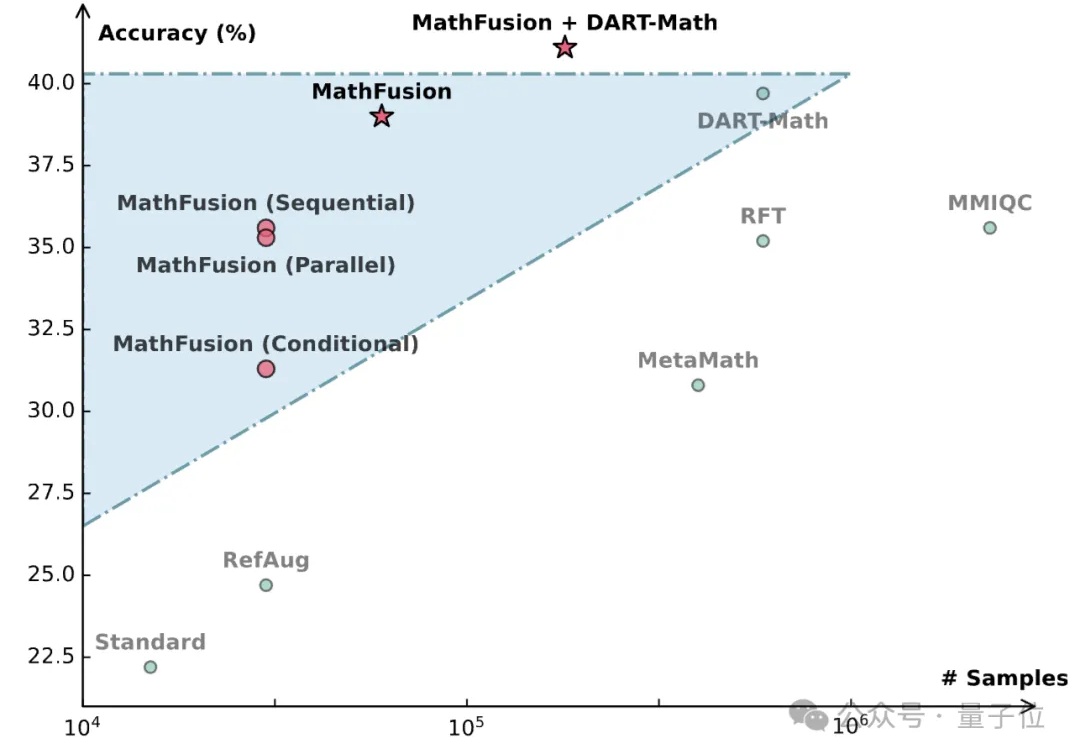
当前数学领域的数据生成方法常常局限于对单个问题进行改写或变换,好比是让学生反复做同一道题的变种,却忽略了数学题目之间内在的关联性。
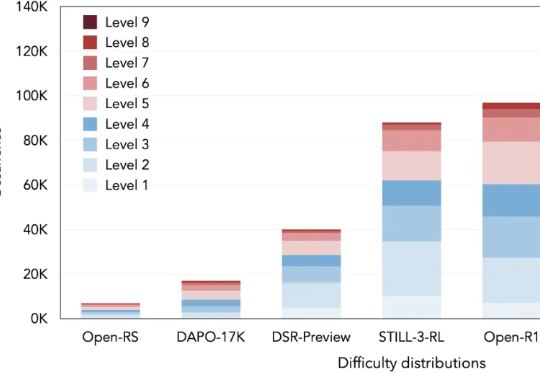
本文将介绍 DeepMath-103K 数据集。该工作由腾讯 AI Lab 与上海交通大学团队共同完成。
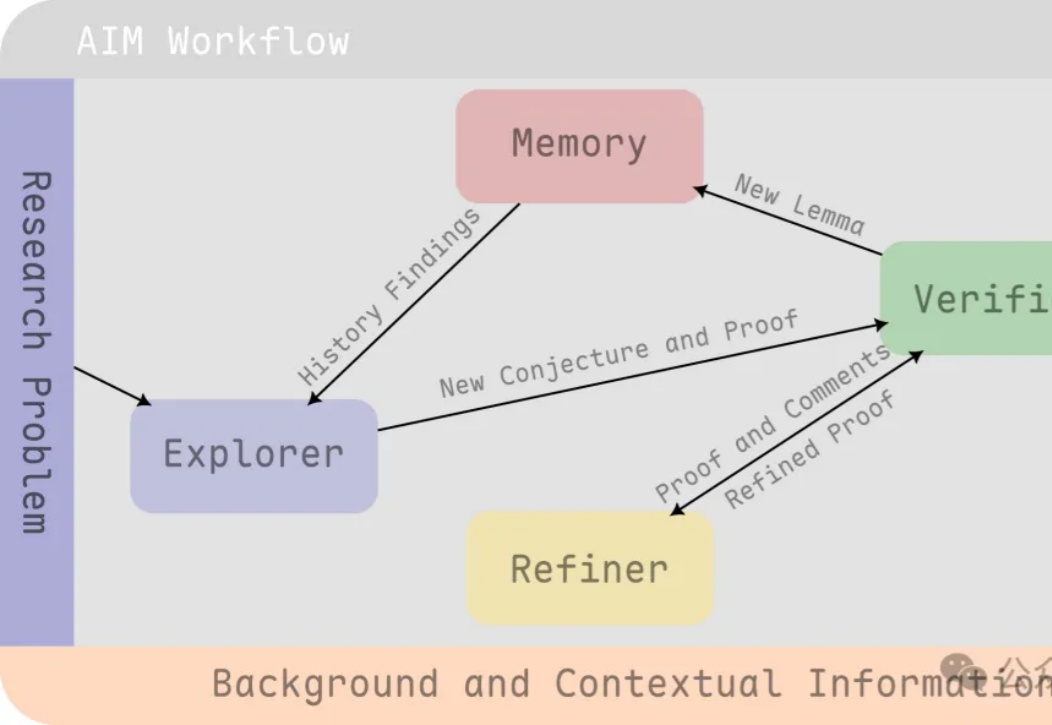
AI数学家来了!清华团队出品—— 他们推出AI Mathematician(AIM)框架,推理模型也能求解前沿理论研究,并且证明完成度很高。
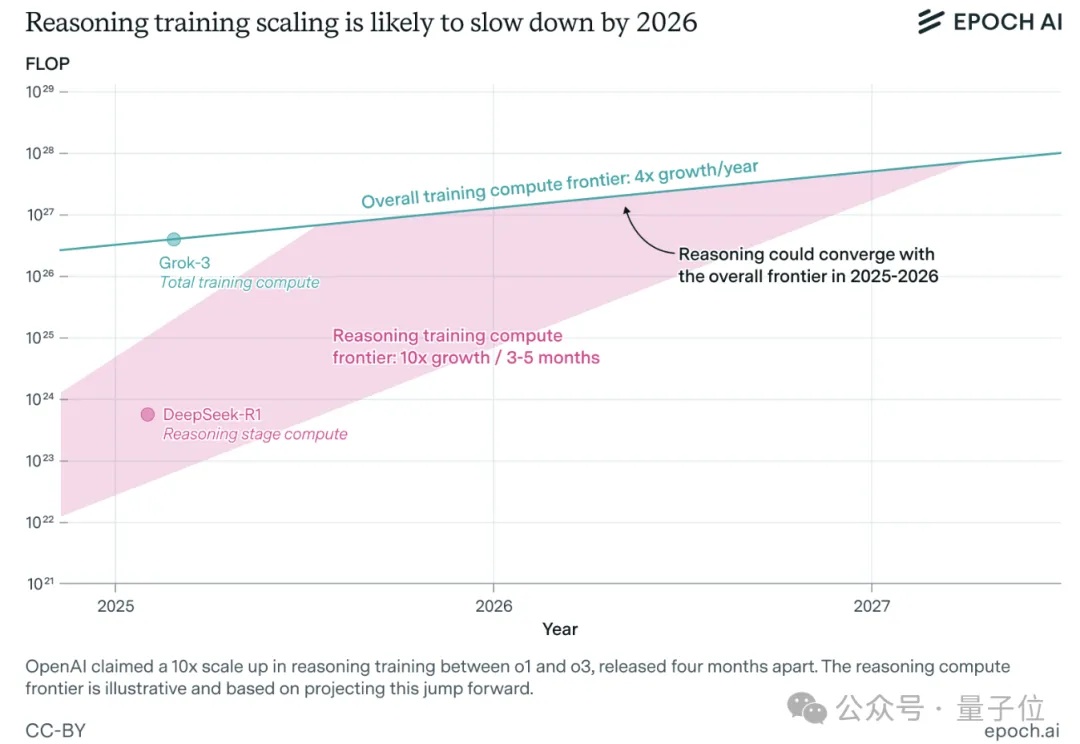
一年之内,大模型推理训练可能就会撞墙。