
7B的DeepSeek蒸馏Qwen数学超o1!在测试时间强化学习,MIT积分题大赛考93分
7B的DeepSeek蒸馏Qwen数学超o1!在测试时间强化学习,MIT积分题大赛考93分见识过32B的QwQ追平671的DeepSeek R1后——刚刚,7B的DeepSeek蒸馏Qwen模型超越o1又是怎么一回事?新方法LADDER,通过递归问题分解实现AI模型的自我改进,同时不需要人工标注数据。
来自主题: AI技术研报
6636 点击 2025-03-08 10:38
 搜索
搜索
见识过32B的QwQ追平671的DeepSeek R1后——刚刚,7B的DeepSeek蒸馏Qwen模型超越o1又是怎么一回事?新方法LADDER,通过递归问题分解实现AI模型的自我改进,同时不需要人工标注数据。
仅仅过了一天,阿里开源的新一代推理模型便能在个人设备上跑起来了!昨天深夜,阿里重磅开源了参数量 320 亿的全新推理模型 QwQ-32B,其性能足以比肩 6710 亿参数的 DeepSeek-R1 满血版。

M3 Ultra终极引擎,可跑千亿模型
仅用32B,就击败o1-mini追平671B满血版DeepSeek-R1!阿里深夜重磅发布的QwQ-32B,再次让全球开发者陷入狂欢:消费级显卡就能跑,还一下子干到推理模型天花板!
DeepSeek-R1 作为 AI 产业颠覆式创新的代表轰动了业界,特别是其训练与推理成本仅为同等性能大模型的数十分之一。多头潜在注意力网络(Multi-head Latent Attention, MLA)是其经济推理架构的核心之一,通过对键值缓存进行低秩压缩,显著降低推理成本 [1]。

编辑注:今天上线的Manus引发了全网的 Agent 热潮,Manus 背后的产品团队——Monica.im 的产品团队也引起了大家的关注。Manus产品负责人张涛在 2 月份曾经有过一次公开分享,解读 DeepSeek R1 成功背后的技术进步和产品思路,从中可以一窥 Manus 的部分解题思路。

今夜,Manus发布之后,随之而来赶到战场的,是阿里。
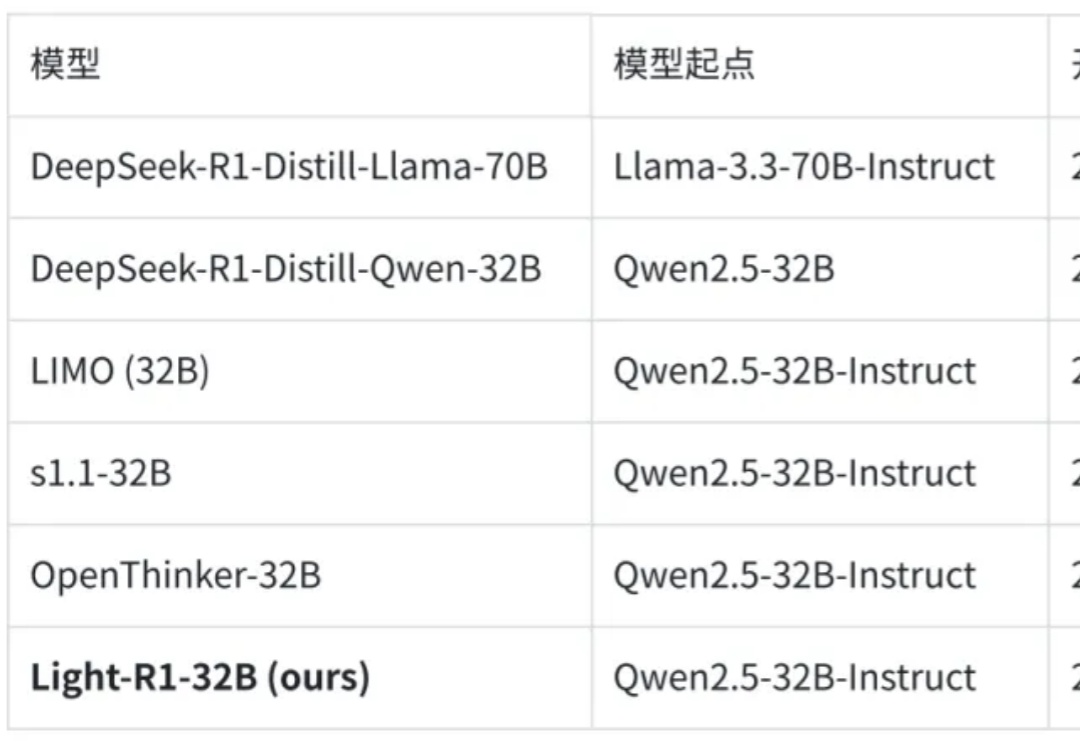
2025 年 3 月 4 日,360 智脑开源了 Light-R1-32B 模型,以及全部训练数据、代码。仅需 12 台 H800 上 6 小时即可训练完成,从没有长思维链的 Qwen2.5-32B-Instruct 出发,仅使用 7 万条数学数据训练,得到 Light-R1-32B

又一个「DeepSeek 王炸组合」,来了。2 月 28 日,两个国民级应用,百度文库和百度网盘,全量接入了 DeepSeek-R1 满血版。
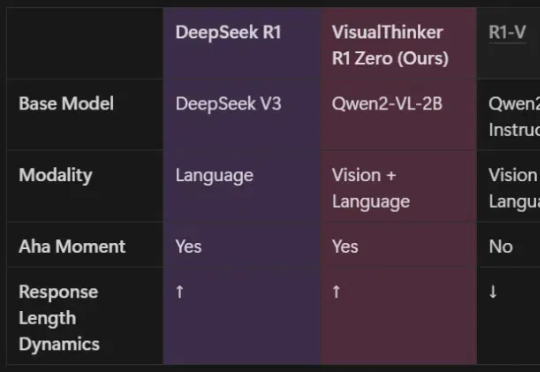
由UCLA等机构共同组建的研究团队,全球首次在20亿参数非SFT模型上,成功实现了多模态推理的DeepSeek-R1「啊哈时刻」!就在刚刚,我们在未经监督微调的2B模型上,见证了基于DeepSeek-R1-Zero方法的视觉推理「啊哈时刻」!