
DeepSeek R1发布一年了,不卷功能、不融资、不着急,凭什么「硬控」硅谷
DeepSeek R1发布一年了,不卷功能、不融资、不着急,凭什么「硬控」硅谷「服务器繁忙,请稍后再试。」
来自主题: AI资讯
7524 点击 2026-01-20 16:40
 搜索
搜索
「服务器繁忙,请稍后再试。」
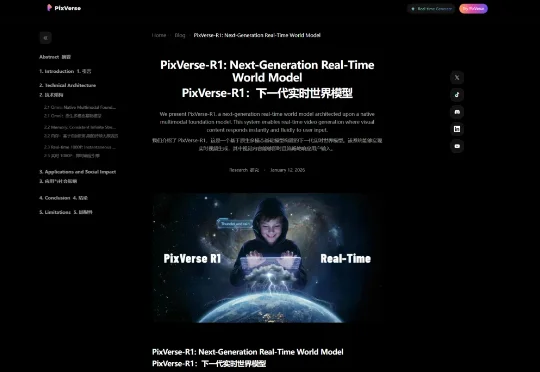
昨晚夜里快12点,AI视频公司PixVerse毫无预兆的发了一个项目。PixVerse R1,下一代实时世界生成模型。这玩意你看文字,可能不是很好理解,我直接放一个官方的demo视频,大家的感觉应该会强一些。

GRPO 是促使 DeepSeek-R1 成功的基础技术之一。最近一两年,GRPO 及其变体因其高效性和简洁性,已成为业内广泛采用的强化学习算法。

几天前,DeepSeek 毫无预兆地更新了 R1 论文,将原有的 22 页增加到了现在的 86 页。新版本充实了更多细节内容,包括首次公开训练全路径,即从冷启动、训练导向 RL、拒绝采样与再微调到全场景对齐 RL 的四阶段 pipeline,以及「Aha Moment」的数据化验证等等。
两天前,DeepSeek悄无声息地把R1的论文更新了,从原来22页「膨胀」到86页。DeepSeek向世界证明:开源不仅能追平闭源,还能教闭源做事!

具身智能是2025年的最大的“泡沫”吗?年初,宇树突然放大招,发布了5900美元的R1人形机器人。要知道,就在一年前,业内普遍认为人形机器人的成本底线还在2到3万美元,宇树这一招,相当于把整个行业的价格预期直接打碎。

我们不会和 Meta 竞价,即便待遇远低于对方,核心人才仍愿意留在 OpenAI,只因大家坚信这里的发展潜力和 AGI 愿景。

多模态大语言模型(MLLMs)已成为AI视觉理解的核心引擎,但其在真实世界视觉退化(模糊、噪声、遮挡等)下的性能崩溃,始终是制约产业落地的致命瓶颈。

AI不仅会做PPT,写代码,它还能理解更深层次的问题。在美国的一项偏重于文化领域的新基准测试中,中国开源模型Qwen3夺冠,DeepSeek的R1跻身前六,力压多家全球顶级的明星模型。
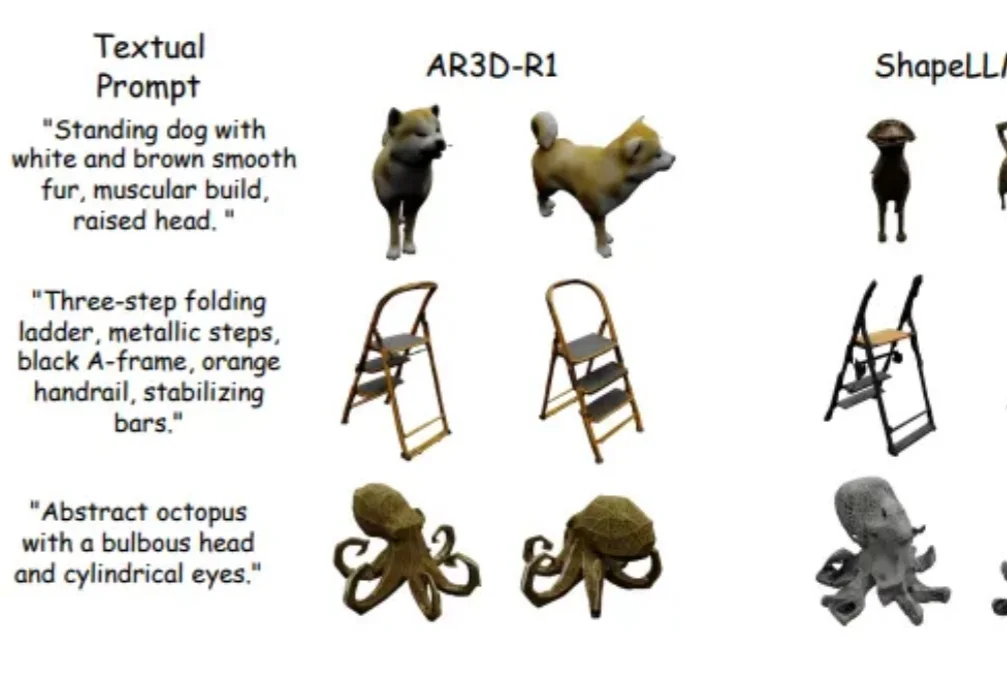
强化学习(RL)在大语言模型和 2D 图像生成中大获成功后,首次被系统性拓展到文本到 3D 生成领域!面对 3D 物体更高的空间复杂性、全局几何一致性和局部纹理精细化的双重挑战,研究者们首次系统研究了 RL 在 3D 自回归生成中的应用!