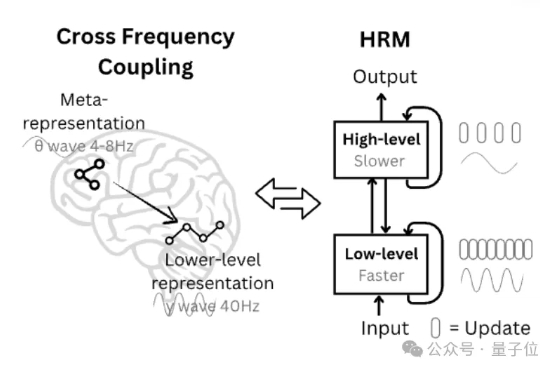
又是王冠:27M小模型超越o3-mini!拒绝马斯克的00后果然不同
又是王冠:27M小模型超越o3-mini!拒绝马斯克的00后果然不同27M小模型超越o3-mini-high和DeepSeek-R1!推理还不靠思维链。 开发者是那位拒绝了马斯克、还要挑战Transformer的00后清华校友,Sapient Intelligence的创始人王冠。
来自主题: AI技术研报
8800 点击 2025-08-10 15:00
 搜索
搜索
27M小模型超越o3-mini-high和DeepSeek-R1!推理还不靠思维链。 开发者是那位拒绝了马斯克、还要挑战Transformer的00后清华校友,Sapient Intelligence的创始人王冠。
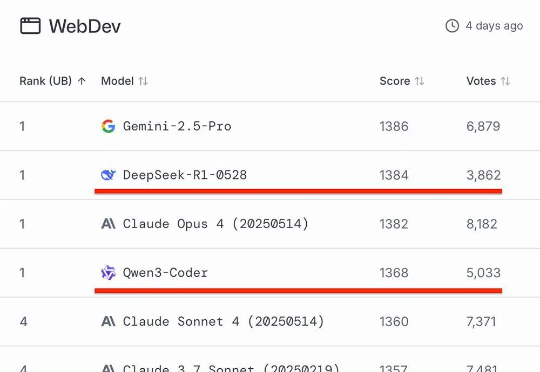
知名AI大模型评测Chatbot Arena放榜!阿里Qwen3-235B-A22B-Instruct-2507位列大语言模型总榜第三,月之暗面Kimi-K2-0711-preview、深度求索DeepSeek-R1-0528并列为总榜第五,以开源之姿超越Claude 4、GPT-4.1等顶尖闭源模型。

在人工智能快速发展的今天,我们已逐渐习惯于让 AI 识别图像、理解语言,甚至与之对话。但当我们进入真实三维世界,如何让 AI 具备「看懂场景」、「理解空间」和「推理复杂任务」的能力?这正是 3D 视觉语言模型(3D VLM)所要解决的问题。
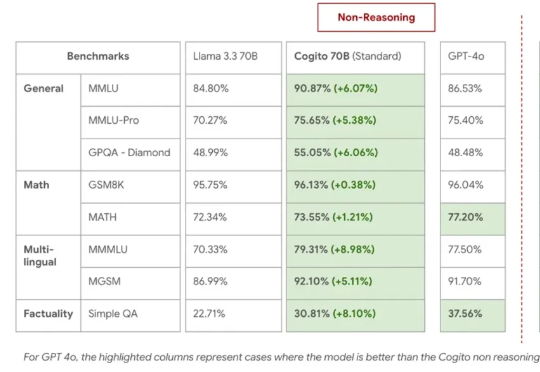
Deep Cogito,一家鲜为人知的 AI 初创公司,总部位于旧金山,由前谷歌员工创立,如今开源的四款混合推理模型,受到大家广泛关注。

近期,随着OpenAI-o1/o3和Deepseek-R1的成功,基于强化学习的微调方法(R1-Style)在AI领域引起广泛关注。这些方法在数学推理和代码智能方面展现出色表现,但在通用多模态数据上的应用研究仍有待深入。
近年来,OpenAI o1 和 DeepSeek-R1 等模型的成功证明了强化学习能够显著提升语言模型的推理能力。通过基于结果的奖励机制,强化学习使模型能够发展出可泛化的推理策略,在复杂问题上取得了监督微调难以企及的进展。
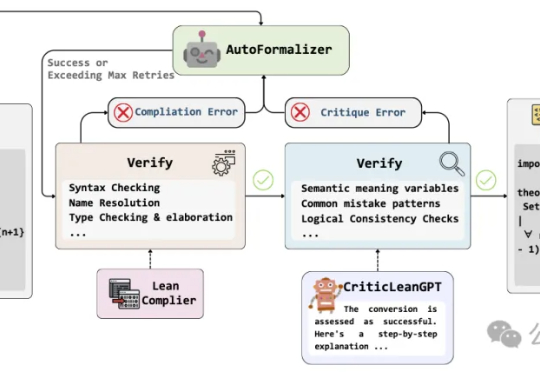
当人工智能已经能下围棋、写代码,如何让机器理解并证明数学定理,仍是横亘在科研界的重大难题。

在社交平台上,「AI 帮我选基金,结果赚了 8%」、「AI 自动炒股,秒杀巴菲特?」之类的帖子不时刷屏,炒股机器人、对话式理财助手有关的 Agent 也不断涌现。
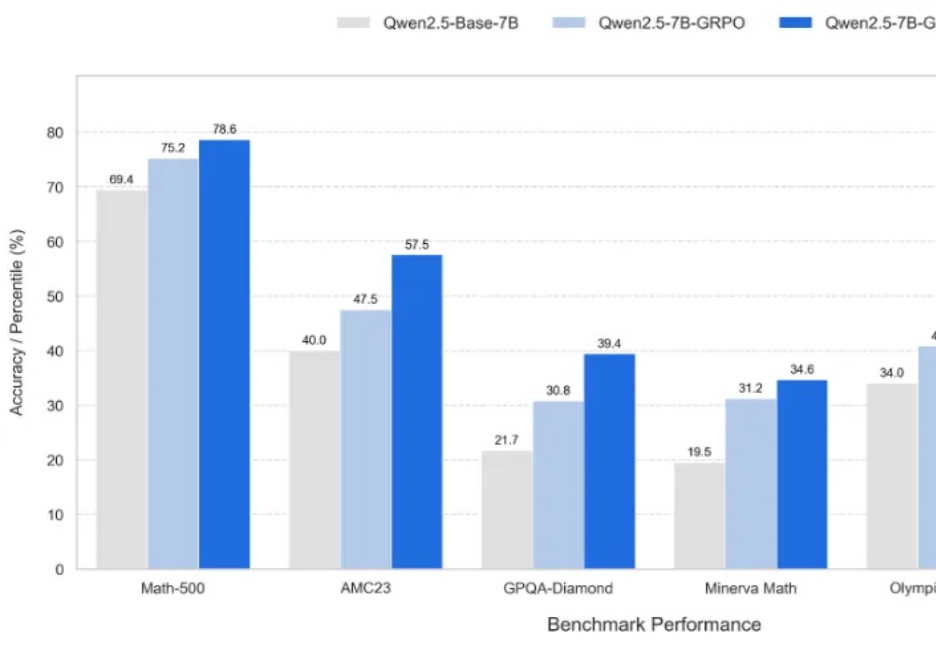
新一代大型推理模型,如 OpenAI-o3、DeepSeek-R1 和 Kimi-1.5,在复杂推理方面取得了显著进展。该方向核心是一种名为 ZERO-RL 的训练方法,即采用可验证奖励强化学习(RLVR)逐步提升大模型在强推理场景 (math, coding) 的 pass@1 能力。
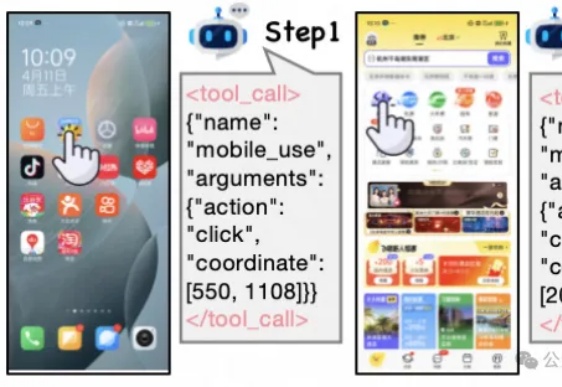
现有Mobile/APP Agent的工作可以适应实时环境,并执行动作,但由于它们大部分都仅依赖于动作级奖励(SFT或RL)。