
还好我没学剪映,这个 skill 做的视频真不错
还好我没学剪映,这个 skill 做的视频真不错身边做短视频的朋友,几乎人手一个剪映。
来自主题: AI资讯
9478 点击 2026-04-20 09:45
 搜索
搜索
身边做短视频的朋友,几乎人手一个剪映。

据知情人士透露,一家从哈佛大学独立出来的新型人工智能实验室正在与投资者进行谈判,以筹集约1 亿美元,以追求一项听起来像科幻小说的使命 :"一个人类可以记住一切的世界"。

多数 AI 创业公司卖的是一个更好的模型。CREAO AI 卖的是一个更好的循环。 这家公司刚刚完成千万级美金融资,领投方为 Prosperity7 Ventures——阿美风险投资(Aramco V

每月5美刀,就能在你家服务器里养个AI打工人,无缝接入Telegram、Discord、Slack、飞书、企业微信等平台。它不仅能帮你干活,还会自己攒技能并反哺训练。网友直呼:换掉OpenClaw太爽了!

EigenLayer 创始人 Sreeram Kannan 在纽约 Digital Asset Summit 上扔出一个论点:智能体会变成公司。不是帮公司干活,不是给公司做助手——是直接变成公司本身。

第一篇论文来自字节SEED团队, 打了一些基础; 《Over-Tokenized Transformer》。 论文标题看上去在讨论“过度分词”。 而重点必然是在第二篇上—— DeepSeek公司的学术成果Engram。 《Conditional Memory via Scalable Lookup》 也就是Engram模块所出处的论文。

ICLR论文STEM架构率先提出「查表式记忆」架构,早于DeepSeek Engram三个月。它将Transformer的FFN从动态计算改为静态查表,用token索引的embedding表直接读取记忆,彻底解耦记忆容量与计算开销。
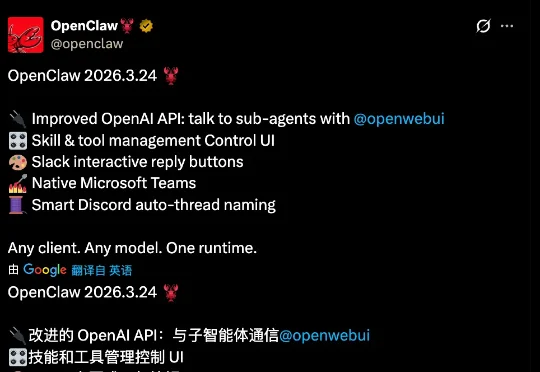
OpenClaw 又开始日更了:Skills 安装终于不用自己猜缺什么了,系统会手把手告诉你下一步;控制台界面也大改,找东西不再像在迷宫里转。另外堵上了一个文件访问的安全漏洞,Telegram、Discord、WhatsApp 的频道 bug 也扫了一轮。

刚刚,五角大楼一份绝密备忘录曝光,Palantir的AI系统正式确立为美军的「记录项目」(Program of Record)。也就是说,Palantir AI,正式成为美军跨军种的核心「操作系统」。人类的未来战争,将很大程度上由AI决定了!

Claude Code又上杀手锏!新增Channels功能,Telegram/Discord直连编程会话,手机直接遥控AI写代码。