
田渊栋AI创业估值315亿,老黄苏妈都投了,姚班施天麟也是合伙人
田渊栋AI创业估值315亿,老黄苏妈都投了,姚班施天麟也是合伙人离职Meta后的田渊栋,现身独角兽联创名单,成了AI创业合伙人。Recursive Superintelligence(RSI),不到30人,刚从隐身状态走出来,就拿到6.5亿美元融资(约44亿元人民币),估值46.5亿美元(约316亿元人民币)。
来自主题: AI资讯
10090 点击 2026-05-14 09:13
 搜索
搜索
离职Meta后的田渊栋,现身独角兽联创名单,成了AI创业合伙人。Recursive Superintelligence(RSI),不到30人,刚从隐身状态走出来,就拿到6.5亿美元融资(约44亿元人民币),估值46.5亿美元(约316亿元人民币)。

就在今天,Carnegie Mellon University(CMU:卡内基梅隆大学)2026 年毕业典礼上,身价逼近 1860 亿美元的「皮衣刀客」黄仁勋站上演讲台,接过科学与技术荣誉博士学位。

4 月 9 日,Anthropic 在 X 上宣布 Claude Managed Agents 上线。同一天,一位 ID 叫 @jiayuan_jy 的中国创业者也发了一条推,“We created the open source version of Claude Managed Agents. Introducing Multica.”

自学习 AI 的融资神话,正在告诉我们一件事——这场 AI 军备竞赛,连研究员本身都要被「卷」进去了。 作者|桦林舞王 编辑|靖宇 1956 年,一批科学家聚在达特茅斯,第一次正式讨论「机器能否思考」
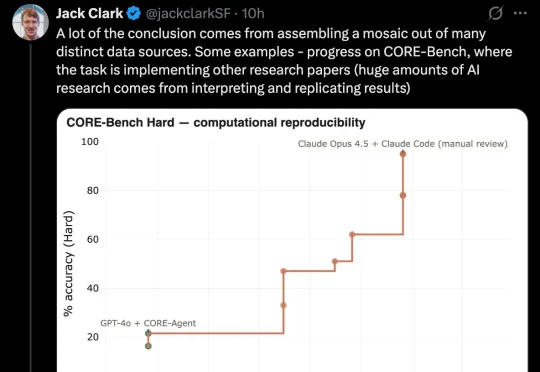
AI 很快就能自己改造自己了?Anthropic 联合创始人 Jack Clark 发帖称,他最近几周阅读了大量公开的 AI 开发数据后,认为到 2028 年底,递归自我改进(recursive self-improvement)发生的概率有 60%。

最近,来自Meta与University of Copenhagen的研究者提出了OneStory: Coherent Multi-Shot Video Generation with Adaptive Memory(收录于CVPR 2026)。这项工作聚焦于一个核心问题:如何在生成多镜头视频时,有效保留长程跨镜头上下文,从而实现更强的叙事一致性。

现有Rectified Flow(RF)模型在反演阶段面临的核心挑战,是逆向ODE对微小误差高度敏感,容易沿着数值不稳定方向偏离前向流形,导致轨迹发散、重建不一致、编辑不可控。为解决这一问题,团队提出PMI(Prox-Mean-Inversion),一种针对RF反演稳定性的轻量化修正机制。
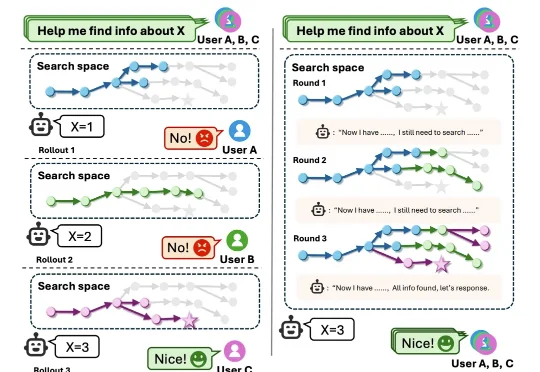
来自东南大学、微软亚洲研究院等机构的研究团队提出了一种全新的解决方案——Re-TRAC(REcursive TRAjectory Compression),这个框架让 AI 智能体能够「记住」每次探索的经验,在多个探索轨迹之间传递经验,实现渐进式的智能搜索。

Matt Shumer 是 AI 创业者和投资者,已在 AI 领域深耕超过 6 年。他是 OthersideAI 的联合创始人兼 CEO,同时通过个人投资基金 Shumer Capital 投资了 Groq、Etched、OpenRouter 等多家前沿 AI 初创公司。
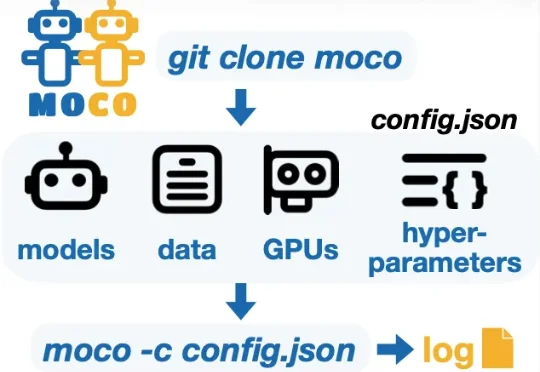
为了支持多模型协同研究并加速这一未来愿景的实现,华盛顿大学 (University of Washington) 冯尚彬团队联合斯坦福大学、哈佛大学等研究人员提出 MoCo—— 一个针对多模型协同研究的 Python 框架。MoCo 支持 26 种在不同层级实现多模型交互的算法,研究者可以灵活自定义数据集、模型以及硬件配置,比较不同算法,优化自身算法,以此构建组合式人工智能系统。MoCo 为设计、