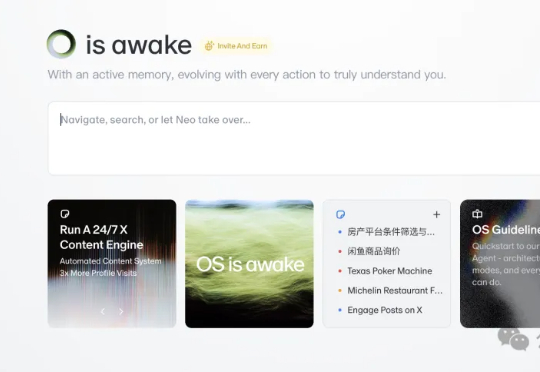
实测专盯Agent上工的OS:长得有点像AI浏览器,双系统通用
实测专盯Agent上工的OS:长得有点像AI浏览器,双系统通用这不,Flowith最近也搞了个新东西:FlowithOS,全球首款专为AI Agent打造的操作系统,重点是Windows用户也能用,终于不是Mac专属了:它的最大特点是:虽然长得像浏览器,但干的却是执行的事儿,能让Agent自己动鼠标、跑流程、干活。
来自主题: AI产品测评
11308 点击 2025-11-15 11:21
 搜索
搜索
这不,Flowith最近也搞了个新东西:FlowithOS,全球首款专为AI Agent打造的操作系统,重点是Windows用户也能用,终于不是Mac专属了:它的最大特点是:虽然长得像浏览器,但干的却是执行的事儿,能让Agent自己动鼠标、跑流程、干活。
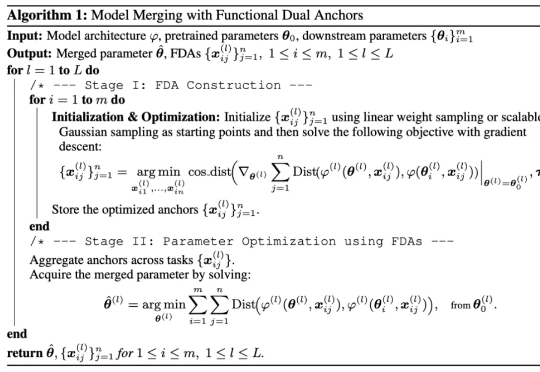
研究者们提出了 FDA(Model Merging with Functional Dual Anchors)——一个全新的模型融合框架。与传统的参数空间操作不同,FDA 将专家模型的参数知识投射到输入-表征空间中的合成锚点,通过功能对偶的方式实现更高效的知识整合。
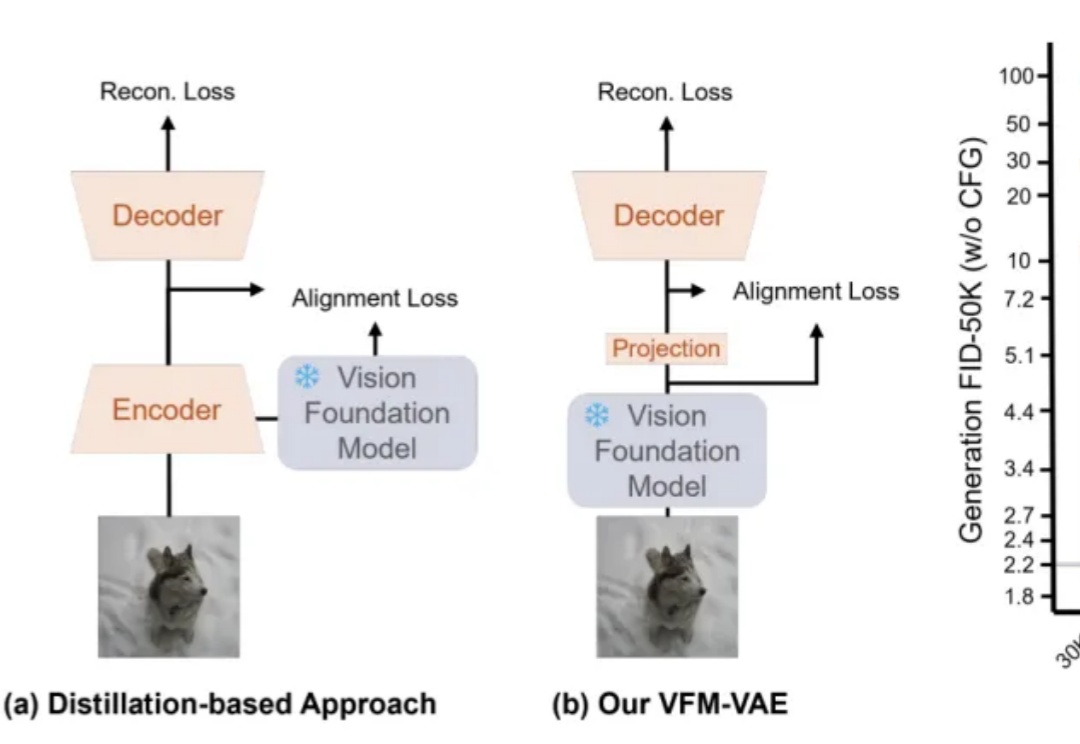
近期,RAE(Diffusion Transformers with Representation Autoencoders)提出以「 冻结的预训练视觉表征」直接作为潜空间,以显著提升扩散模型的生成性能。

厦门大学和腾讯合作的最新论文《FlashWorld: High-quality 3D Scene Generation within Seconds》获得了海内外的广泛关注,在当日 Huggingface Daily Paper 榜单位列第一,并在 X 上获得 AK、Midjourney 创始人、SuperSplat 创始人等 AI 大佬点赞转发。

就像 Windows 或 macOS 为软件提供运行环境,Flowith OS 为 AI Agent 提供思考与行动的环境。Flowith 正式发布了一个全新的产品:名为 Flowith OS 的新物种。它选择了一个「另辟蹊径」的路径,尝试为 AI Agent 打造一个全新的 AI-Native 式的操作系统。

昨晚 11 点,绕了好几道弯,我终于找朋友拿到了 FlowithOS 的内测码。这款产品昨天在 X 上挺火的,很多人转发。 体验了大半天之后,我非常兴奋。相比 Manus,或者 OpenAI 最近发布

世界在AI眼中活了过来!谷歌Grounding with Google Maps功能上线,Gemini可调用2.5亿地点信息,结合搜索工具,提供更准确、更及时的答案,完美适用于旅行规划和本地服务。

2023年Meta推出SAM,随后SAM 2扩展到视频分割,性能再度突破。近日,SAM 3悄悄现身ICLR 2026盲审论文,带来全新范式——「基于概念的分割」(Segment Anything with Concepts),这预示着视觉AI正从「看见」迈向真正的「理解」。
说出概念,SAM 3 就明白你在说什么,并在所有出现的位置精确描绘出边界。 Meta 的「分割一切」再上新? 9 月 12 日,一篇匿名论文「SAM 3: SEGMENT ANYTHING WITH CONCEPTS」登陆 ICLR 2026,引发网友广泛关注。
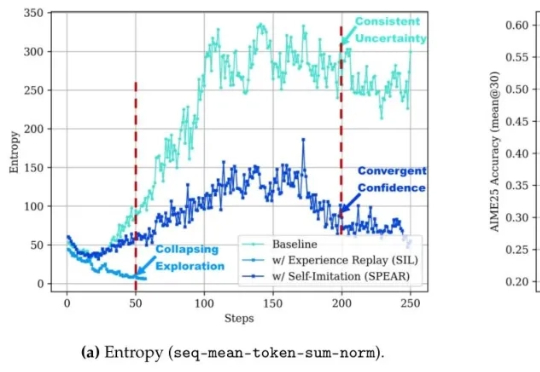
让智能体自己摸索新方法,还模仿自己的成功经验。腾讯优图实验室开源强化学习算法——SPEAR(Self-imitation with Progressive Exploration for Agentic Reinforcement Learning)。