
小米AI语音新框架:人人都能当声音导演
小米AI语音新框架:人人都能当声音导演语音合成大家都不陌生,这两年市面上各种AI配音也层出不穷。
来自主题: AI技术研报
10855 点击 2026-04-08 16:58
 搜索
搜索
语音合成大家都不陌生,这两年市面上各种AI配音也层出不穷。

刚刚,深圳机器人芯片公司地瓜机器人宣布拿下1.5亿美元(约合人民币10.24亿元)B2轮新融资,某零售科技与供应链巨头、滴滴、Prosperity7风投基金、高瓴创投、淡马锡旗下Vertex Growth、五源资本等产业巨头及一线资本参投。
今天《纽约客》发表了历时 18 个月的调查报道,首次披露 OpenAI 首席科学家 Ilya Sutskever 在 2023 年秋天汇编的 70 页内部备忘录,以及 Anthropic 联合创始人 Dario Amodei 保留多年的 200 余页私人笔记。

就在大家都急头白脸地等待DeepSeek-V4的时候,冷不丁一篇新论文引起了网友们的注意—— 提出新稀疏注意力机制HISA(分层索引稀疏注意力),突破64K上下文的索引瓶颈,相比DeepSeek正在用的DSA(DeepSeek Sparse Attention)提速2-4倍。

许多长期与文字和代码打交道的创作者,应该对 Obsidian 这款软件并不陌生。作为目前全球最具影响力的本地化 Markdown 笔记应用之一,它凭借独树一帜的知识图谱和开源生态,在知名度与用户忠诚度上,已然能与 Notion 分庭抗礼。

2026 年,阿联酋哈利法大学的邹航博士和他所在的团队,做出了全世界第一个射频大模型,名字叫 RF GPT。这个模型能直接看懂无线信号,就像 GPT 4o 能看懂图片、Qwen2 Audio 能听懂声音一样。你把无线信号扔给它,它不仅能告诉你这里面有几种信号、分别是什么技术,还能分析出有没有信号在打架、哪个是 5G 哪个是蓝牙、甚至能数出来 WiFi 网络里有多少个用户同时在用。
OpenAI 的下一代图像模型 GPT-Image-2,今天在 Chatbot Arena 上被人发现了。独立开发者 levelsio 率先爆料,这个模型以三个代号悄悄上线了 Arena:maskingtape-alpha、gaffertape-alpha、packingtape-alpha。
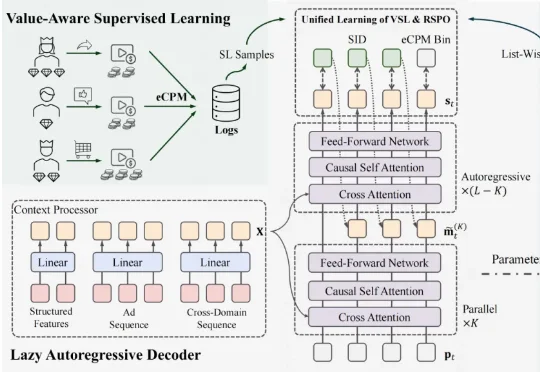
快手的这篇论文,正是对这一问题交出的一份沉甸甸的工业级答卷。他们提出了 GR4AD(Generative Recommendation for ADvertising),一个横跨表征、学习、服务三大层面协同设计的生成式广告推荐系统,并已全量部署于快手广告平台,服务超过 4 亿用户。

最近,GitHub又炸出了一个明星项目:让「一个人开游戏公司」变成现实的Claude-Code-Game-Studios。与此同时,另一个「让普通人把想象变成游戏」的产品Aippy,也在欧美年轻人中风靡。与前者的专业工具属性不同,Aippy要做的是新一代数字原住民的「游戏社区」。
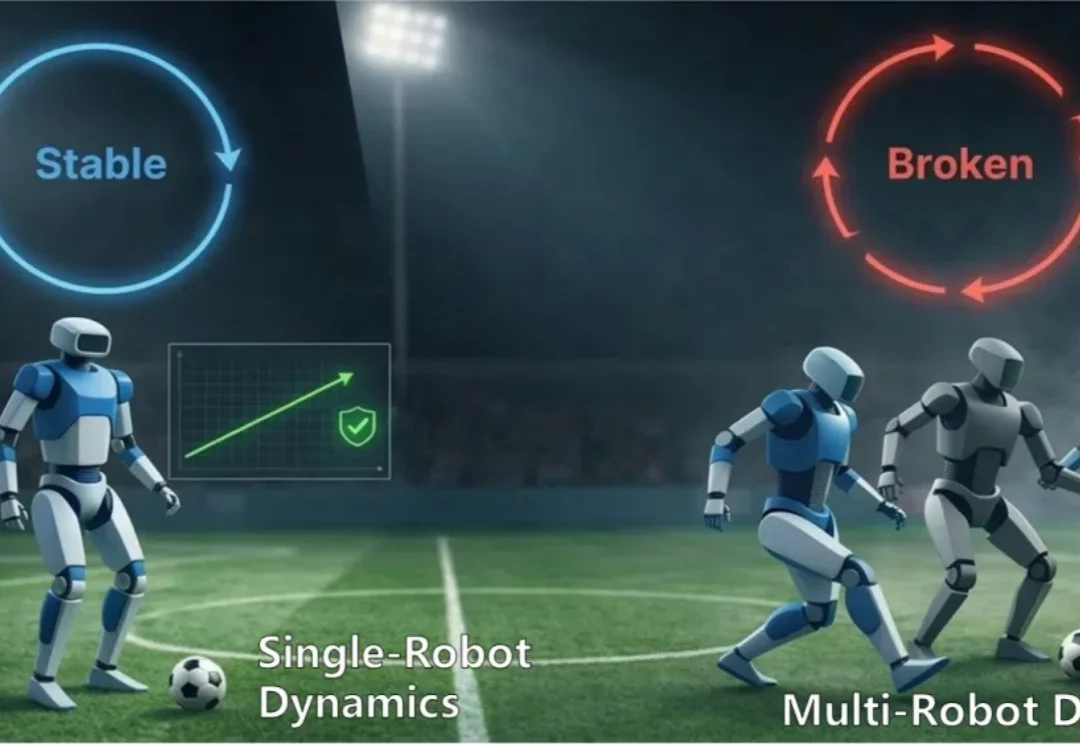
近年来,Decision-Coupled World Model 与 Model-based RL 在机器人领域取得了显著成功。通过学习环境动力学模型,智能体能够在内部模拟未来,从而进行规划与决策。但当系统从单机器人扩展到多机器人时,问题开始变得棘手。