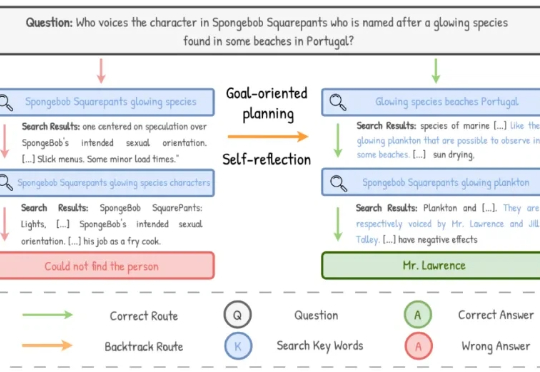
搜索智能体的关键一课:先立目标,再照镜子
搜索智能体的关键一课:先立目标,再照镜子随着 AI 能力不断增强,它正日益融入我们的工作与生活。我们也更愿意给予它更多「授权」,让它主动去搜集信息、分析证据、做出判断。搜索智能体正是 AI 触达人类世界迈出的重要一步。
来自主题: AI技术研报
8529 点击 2025-10-23 16:04
 搜索
搜索
随着 AI 能力不断增强,它正日益融入我们的工作与生活。我们也更愿意给予它更多「授权」,让它主动去搜集信息、分析证据、做出判断。搜索智能体正是 AI 触达人类世界迈出的重要一步。
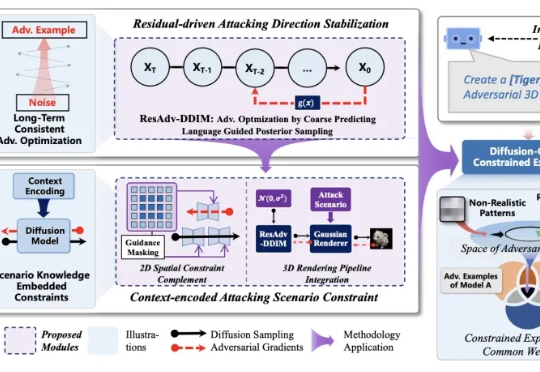
人工智能模型的安全对齐问题,一直像悬在头顶的达摩克利斯之剑。 自对抗样本被发现以来,这一安全对齐缺陷,广泛、长期地存在与不同的深度学习模型中。
AI 检测准确率高达 98.9%,也防不住有人给真视频 P 上 Sora 水印。前段时间刷到一个视频,标题就是「中俄混血女明星回应地下室打婆婆传闻」,试问谁看了这个标题能不燃起熊熊的八卦之心?

时隔两月,Baichuan-M2 Plus重磅出世!成为业内首个循证增强的医疗大模型,幻觉要比DeepSeek-R1低3倍,可信度比肩资深临床专家。新模型将「循证医学」理念深度融入训练和推理,通过首创「六源循证范式」,模拟人类医生思维,有效辨别不同层级医学证据、评估其可靠性,并在回答中优先引用高等级证据。

随着多模态大模型的不断演进,指令引导的图像编辑(Instruction-guided Image Editing)技术取得了显著进展。然而,现有模型在遵循复杂、精细的文本指令方面仍面临巨大挑战,往往需要用户进行多次尝试和手动筛选,难以实现稳定、高质量的「一步到位」式编辑。

整个Hugging Face的趋势版里,前4有3个OCR,甚至Qwen3-VL-8B也能干OCR的活,说一句全员OCR真的不过分。然后在我上一篇讲DeepSeek-OCR文章的评论区里,有很多朋友都在把DeepSeek-OCR跟PaddleOCR-VL做对比,也有很多人都在问,能不能再解读一下百度那个OCR模型(也就是PaddleOCR-VL)。
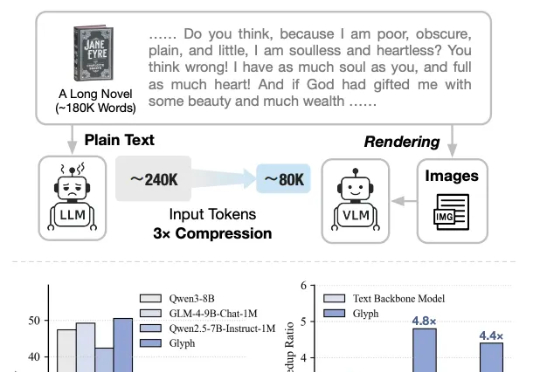
太卷了,DeepSeek-OCR刚发布不到一天,智谱就开源了自家的视觉Token方案——Glyph。既然是同台对垒,那自然得请这两天疯狂点赞DeepSeek的卡帕西来鉴赏一下:

虽然浏览器 AI agent 的概念听起来很美好,但实际构建这样的系统却面临巨大挑战。这正是 Kernel 要解决的核心问题。我发现很多开发者想要构建 AI agent,但却在基础设施层面遇到了各种障碍:性能不稳定、运行时间不可靠、定价不合理、身份认证复杂、权限管理混乱,以及一个本来就不是为 agent 设计的互联网世界。

刚刚,这个开源的VLA一站式平台,不仅让UR5e真机实现了100%成功率,还在五大仿真环境中全面领先,最高性能提升高达46%,而且还支持RTX 4090训练!最近,由Dexmal 原力灵机重磅开源的Dexbotic,则构建了一个「VLA统一平台」。Dexbotic作为具身智能VLA模型一站式科研服务平台,可以为VLA科研提供基础设施,加速研究效率。
美国 AI 圈开始出现“担心中国开源断供”的苗头了吗?10 月 20 日,在专注于开源模型讨论、拥有 55 万成员的 Reddit 分论坛“r/LocalLLaMA”上,一位网友发布了一则“当中国公司停止提供开源模型时会发生什么?”的提问,并表达了假如中国模型逐渐闭源或开始收费该怎么办的担忧。