实测可灵AI的新视频模型,它生成的动作戏酷到封神。
实测可灵AI的新视频模型,它生成的动作戏酷到封神。可灵2.5,来了。 不仅已经对可灵的超级创作者们正式进行灰度内测,还在这个周末,登上了釜山国际电影节。
来自主题: AI产品测评
9277 点击 2025-09-23 14:52
 搜索
搜索
可灵2.5,来了。 不仅已经对可灵的超级创作者们正式进行灰度内测,还在这个周末,登上了釜山国际电影节。
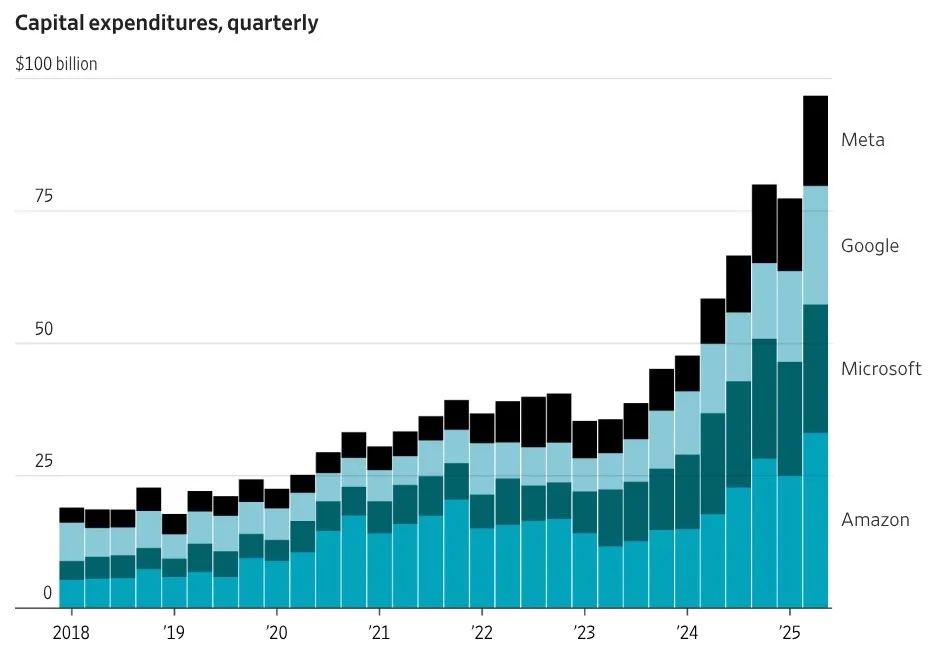
美国七巨头AI基建支出掀狂潮:经济提振了,大批人失业了。

近日,国内首次针对AI大模型的实网众测结果正式公布,一场大型“安全体检”透露出不容忽视的信号:本次活动累计发现安全漏洞281个,其中大模型特有漏洞高达177个,占比超过六成,这组数据表明,AI正面临着超出传统安全范畴的新型威胁。
今年春天,医学教育平台 AMBOSS 宣布完成 2.6 亿美元融资;不久后,AI 编程公司 Windsurf 的估值也跃升至 28.5 亿美元。与此同时,在东南亚、欧洲和印度市场,Manabie、Knowunity、Eruditus、Lingokids 等公司也相继拿下千万至上亿美元的新一轮资金。

LeCun 这次不是批评 LLM,而是亲自改造。当前 LLM 的训练(包括预训练、微调和评估)主要依赖于在「输入空间」进行重构与生成,例如预测下一个词。 而在 CV 领域,基于「嵌入空间」的训练目标,如联合嵌入预测架构(JEPA),已被证明远优于在输入空间操作的同类方法。

不用在建模、UV、贴图软件之间反复横跳,一个工作台就能得到:这是腾讯专为3D设计师、游戏开发者、建模师等打造的专业级AI工作台混元3D Studio。

论文的标题很学术,叫《心理学增强AI智能体》但是大白话翻译一下就是,想要让大模型更好地完成任务,你们可能不需要那些动辄几百上千字的复杂Prompt,不需要什么思维链、思维图谱,甚至不需要那些精巧的指令。

近期,北京大学与字节团队提出了名为 BranchGRPO 的新型树形强化学习方法。不同于顺序展开的 DanceGRPO,BranchGRPO 通过在扩散反演过程中引入分叉(branching)与剪枝(pruning),让多个轨迹共享前缀、在中间步骤分裂,并通过逐层奖励融合实现稠密反馈。

9 月 22 日下午,联发科推出的新一代旗舰 5G 智能体 AI 芯片 —— 天玑 9500,并展示了一系列新形态端侧的 AI 应用,在公众层面首次推动端侧 AI 从尝鲜到好用。现在,让手机端大语言模型(LLM)处理一段超长的文本,最长支持 128K 字元,它只需要两秒就能总结出会议纪要,AI 还能自动修改你的错别字。
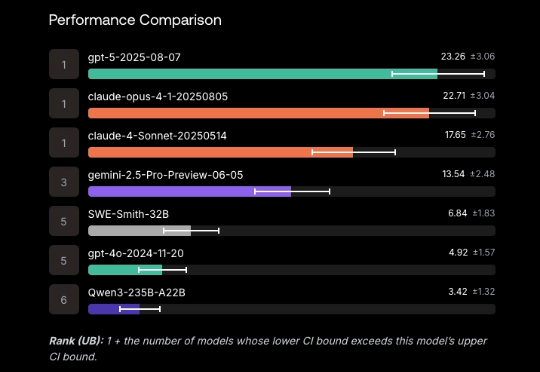
Scale AI的新软件工程基准SWE-BENCH PRO,出现反转!表面上看,“御三家”集体翻车,没一家的解决率超过25%: GPT-5、Claude Opus 4.1、Gemini 2.5分别以23.3%、22.7%、13.5%的解决率“荣”登前三。