
前米哈游、快手增长操盘手创业,AI原生增长Agent公司LeapMind Growth完成天使+轮融资
前米哈游、快手增长操盘手创业,AI原生增长Agent公司LeapMind Growth完成天使+轮融资熊晓鸽,阎焱等大佬云集投资黄埔实战研修班 暗战 在2026年4月29日,上海。 一笔看似并不算大的融资,却悄然搅动了整个创投圈水面之下最为汹涌的那股暗流。 AI原生增长Agent公司LeapMind
来自主题: AI资讯
8599 点击 2026-05-04 10:43
 搜索
搜索
熊晓鸽,阎焱等大佬云集投资黄埔实战研修班 暗战 在2026年4月29日,上海。 一笔看似并不算大的融资,却悄然搅动了整个创投圈水面之下最为汹涌的那股暗流。 AI原生增长Agent公司LeapMind

湖南经视在《经视新闻》宣布启用 AI 主播「声声」和「双双」,这也不是说湖南卫视要用 AI 。完全替代真人,这两位 AI 主播暂时只在五一假期期间播报常态化新闻,同时画面中也标注「AI 生成」。
事情是这样的,前两天,一位博主 Henry Shi 在 X 上发文称,自己看到科技界正在发生奇怪的事情,「一些曾经管理着数十亿美元公司业务的 CTO,纷纷离职,转而加入 Anthropic,去做一名个人贡献者 (IC, Individual Contributor)。」
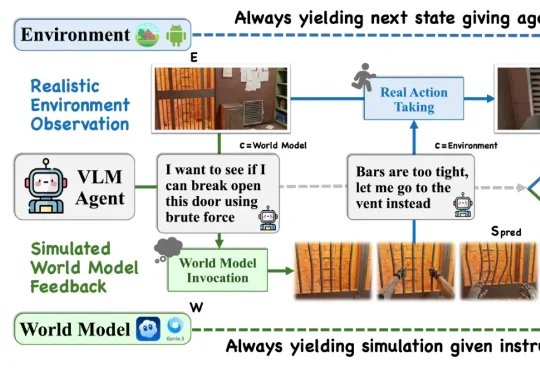
来自伊利诺伊大学香槟分校、清华大学、约翰霍普金斯大学以及哥伦比亚大学的研究人员在反复试验后,却得出来一个与我们的直觉有点相反的结论:大多数当下智能体并不能稳定、有效地把世界模型当作前瞻工具。
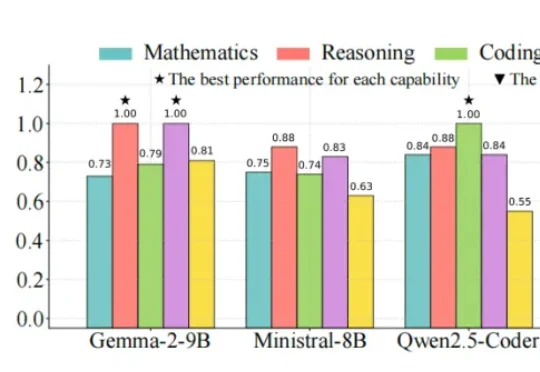
研究者开始尝试让 MoA 变稀疏。例如,一些方法如 Sparse MoA 会先让模型池中的所有模型生成回答,再通过额外的评审模型进行打分和筛选,只保留一部分模型进入后续协作。这样虽然减少了后续融合的负担,但本质上仍然绕不开一个问题:为了决定该选谁,系统还是得先让所有模型都推理一遍。

在整个会议期间,阿贝尔对人工智能的态度,与当下争先恐后拿AI重新包装自己的企业界形成了一种微妙的对立。“我们不会为了人工智能而做人工智能。”这句话被他反复强调,贯穿始终。

一位中国开发者,在横跨大西洋的航程中,在飞机上用 MacBook 本地跑 Llama 70B,整整 11 小时没有网络,帖子瞬间在X上爆火!但是随后,越来越多网友发现,这故事不太对啊?

过去几十年里,人类使用计算机的方式始终没有发生根本变化:我们编写程序,机器按照指令执行。 但随着大模型的发展,这种关系正在悄然改变,人类开始不再描述“如何做”,而是直接表达“想做什么”,而系统则负责推
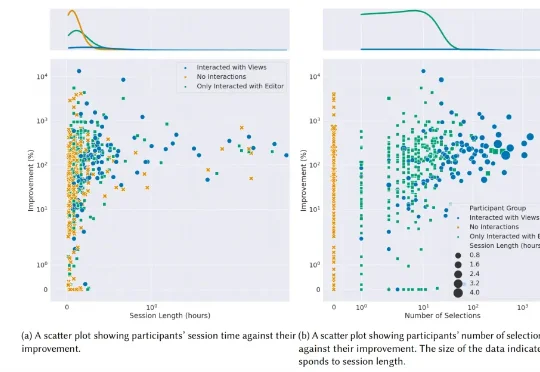
上个月刚充了 ChatGPT Plus,这个月又买了Cursor Pro,OpenClaw 也研究的差不多了。我们对 AI 的期待,说起来非常简单:给最好的方案、最准确的代码、最精确的回答。
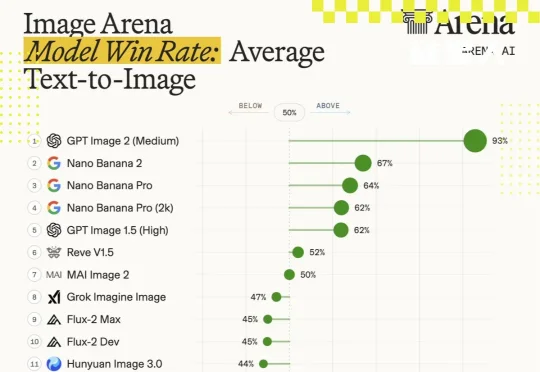
GPT Image 2 凭什么这么强?是扩散模型又迭代了一版?是把 DiT 的参数量从 7B 扩到 20B?是训了更多高质量数据?先给结论:OpenAI 很可能已经不在“纯扩散模型”这条主赛道上了。他们已经把图像生成从“美术课”调到了“语文课”——用一个能读懂指令、能记住上下文、能理解物体关系的 LLM 主导语义规划,至于最后一步的像素生成,可能由扩散组件或其他解码器完成。