
70%时间在救火,增长反而不是核心!Anthropic增长负责人自曝Claude增长核心秘方:人才+文化才是真正秘方!传统策略失效了!模型是关键
70%时间在救火,增长反而不是核心!Anthropic增长负责人自曝Claude增长核心秘方:人才+文化才是真正秘方!传统策略失效了!模型是关键今天,Anthropic又出了一条引爆AI圈的新闻:年化收入已经超过了OpenAI,达到了300亿美元!
来自主题: AI资讯
8447 点击 2026-04-08 09:15
 搜索
搜索
今天,Anthropic又出了一条引爆AI圈的新闻:年化收入已经超过了OpenAI,达到了300亿美元!
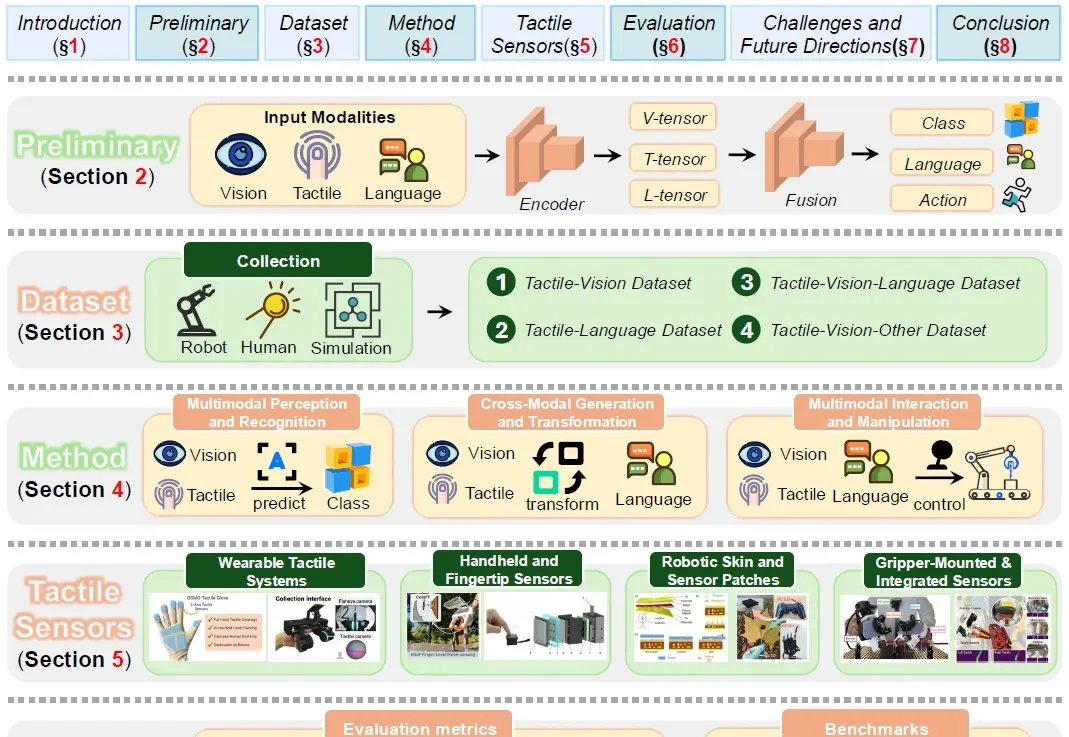
在具身智能的感知拼图中,触觉一直扮演着不可或缺却难以被完美量化的角色。它提供了视觉等远程传感器无法替代的关于接触几何、材料特性和交互动态的直接反馈。

上个月,Anthropic 最强模型 Claude Mythos 意外被曝光。 被泄露的内部文档里面写着,它比 Anthropic 的 Opus 模型更大、更智能,是迄今为止开发过的最强大的 AI 模

从OpenClaw刷屏开始,人人都能拥有专属的AI“个人助理”仿佛不再是科幻电影里的未来。在这场通往新世界的拥挤赛跑中,一家聚焦海外市场的初创公司Boxy刚刚获得红杉中国种子基金投资的数百万元美元融资。

2026 年 3 月 30 日,#CreaoAI 冲上 X 全球热搜 Top 3。我们刷到这条热搜的时候,第一反应是:这次的用户反应有点不一样。不是常见的"AI新闻"传播路径——科技媒体报道、KOL转发、然后消失。这次的评论区里,不同语种的用户开始自己动手,有人让它每周一给 Gmail 邮箱里发送实时报价报告,
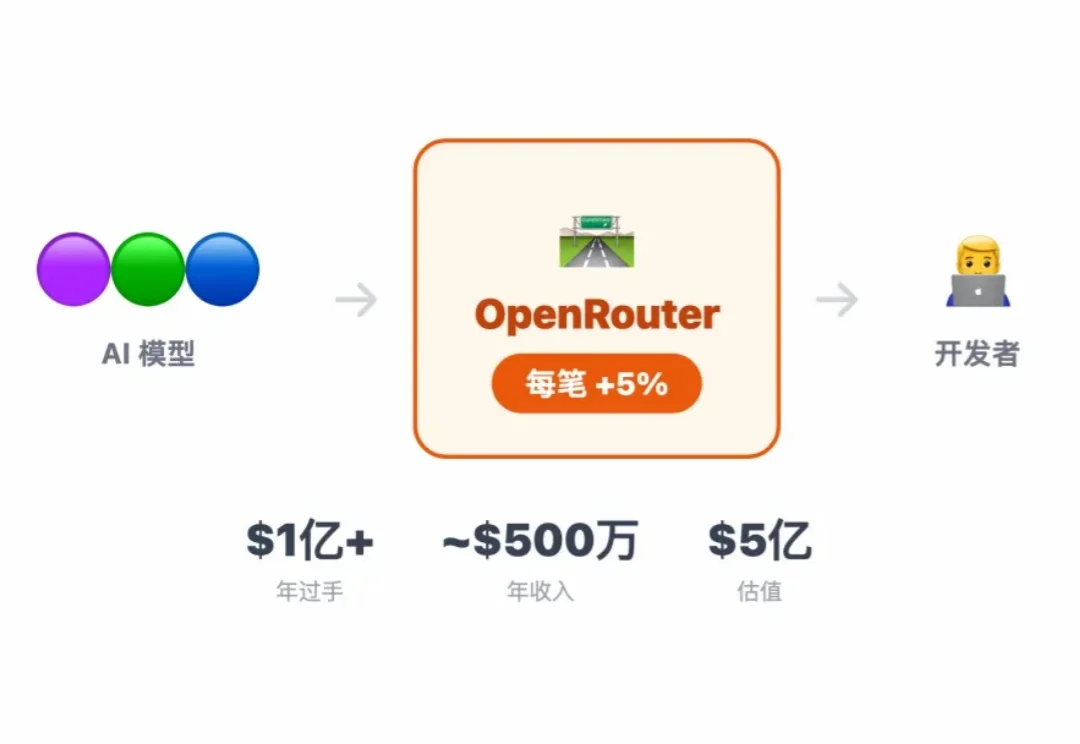
本文是「小龙虾搞钱指南」系列第 4 篇。前两篇拆了 Polymarket 交易 Bot 和 Skill 经济变现 以及用 ai 实现股票快速跟踪,这篇聊一个更底层的生意——帮别人调 AI 的"中间商",是怎么赚到钱的。

AI 时代最赚钱的公司,可能从来不是做 AI 的那个。
在使用体验上,龙虾的另一大特色是“活人感极强”。以往的AI,用户不搭话,它就永远沉默;而龙虾的机制则是「心跳」:每隔30秒,自己给自己发一条消息,反思有没有事情做,有的话就去做,没有的话就“没事,继续睡”。当然,这种活人感的代价,是燃烧的Tokens。

就在大家都急头白脸地等待DeepSeek-V4的时候,冷不丁一篇新论文引起了网友们的注意—— 提出新稀疏注意力机制HISA(分层索引稀疏注意力),突破64K上下文的索引瓶颈,相比DeepSeek正在用的DSA(DeepSeek Sparse Attention)提速2-4倍。
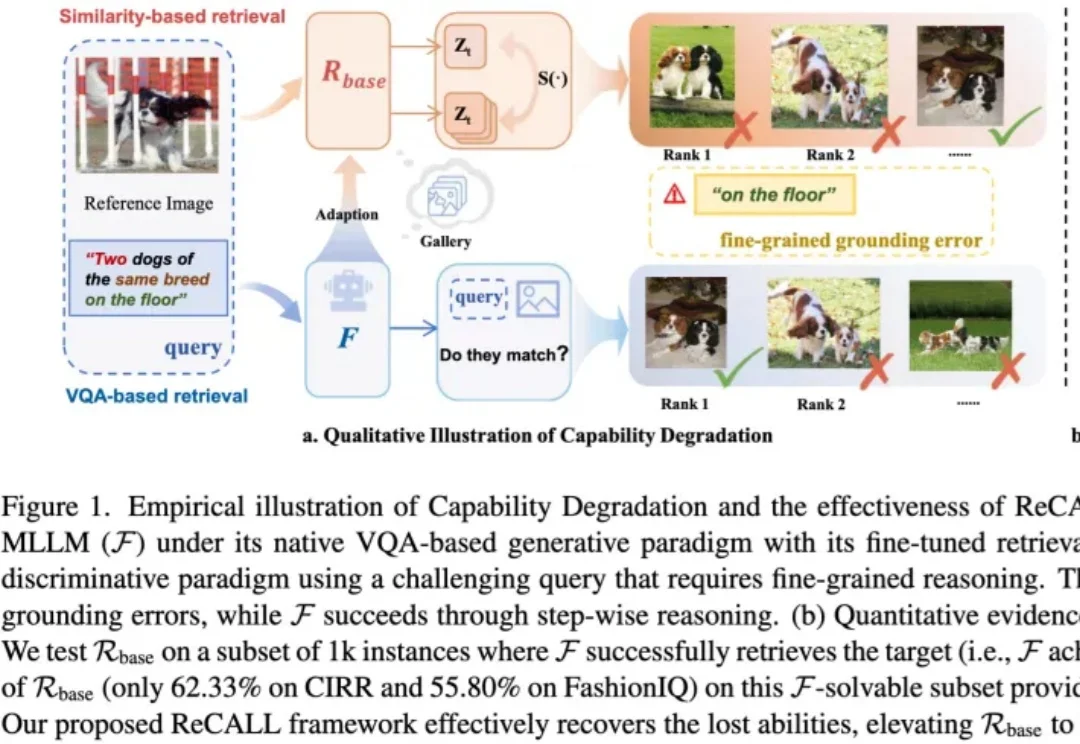
生成式模型当检索器大材小用效果还不好?