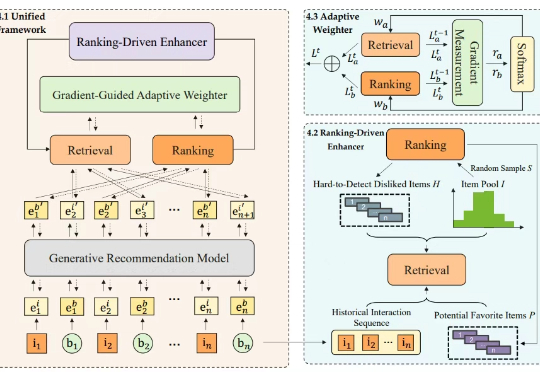
打破推荐系统「信息孤岛」!中科大与华为提出首个生成式多阶段统一框架,性能全面超越 SOTA
打破推荐系统「信息孤岛」!中科大与华为提出首个生成式多阶段统一框架,性能全面超越 SOTA在信息爆炸的时代,推荐系统已成为我们获取资讯、商品和服务的核心入口。无论是电商平台的 “猜你喜欢”,还是内容应用的信息流,背后都离不开推荐算法的默默耕耘
来自主题: AI技术研报
7346 点击 2025-06-21 12:53
 搜索
搜索
在信息爆炸的时代,推荐系统已成为我们获取资讯、商品和服务的核心入口。无论是电商平台的 “猜你喜欢”,还是内容应用的信息流,背后都离不开推荐算法的默默耕耘

华为正将「根深」的自研能力,转化为赋能千行万业智能化升级的「叶茂」。
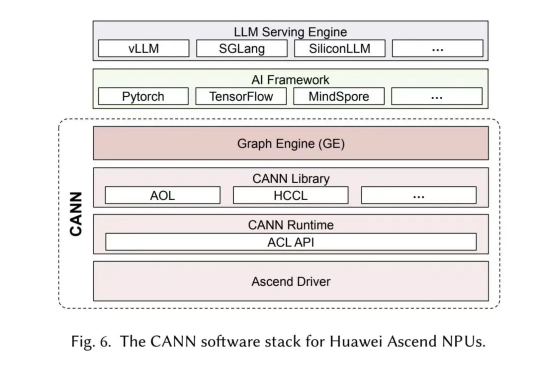
今年 4 月,围绕“华为芯片效率是否超越国际主流 AI 芯片和架构”的问题,网上曾引发一场激烈争论。

没有一个大模型可以一统天下。 这,或许已经成为了AI大模型时代行业里的一个共识。
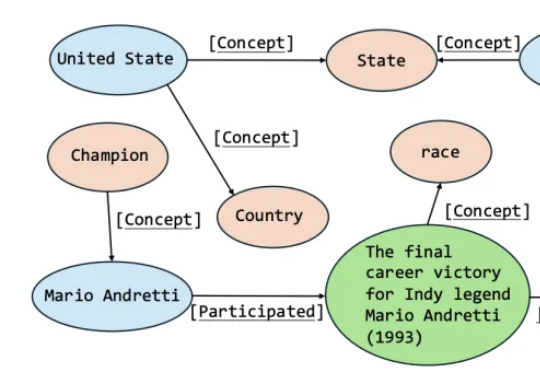
知识图谱(KGs)已经可以很好地将海量的复杂信息整理成结构化的、机器可读的知识,但目前的构建方法仍需要由领域专家预先创建模式,这限制了KGs的可扩展性、适应性和领域覆盖范围。

就在刚刚,华为首次亮相了一套“虚”的技术—— 数字化风洞,一个在正式训推复杂AI模型之前,可以在电脑中“彩排”的虚拟环境平台

IT桔子在2024年做过一次统计:AI创业者曾在非常优秀的大厂/名企工作过的,在已透露职业背景的AI创业者中占比达到90%。其中,培养中国AI创业者较多的25家名企,包括百度、阿里、腾讯、华为、网易、360等13家中国企业;还有12家外企和跨国公司。

大模型的落地能力,核心在于性能的稳定输出,而性能稳定的底层支撑,是强大的算力集群。其中,构建万卡级算力集群,已成为全球公认的顶尖技术挑战。
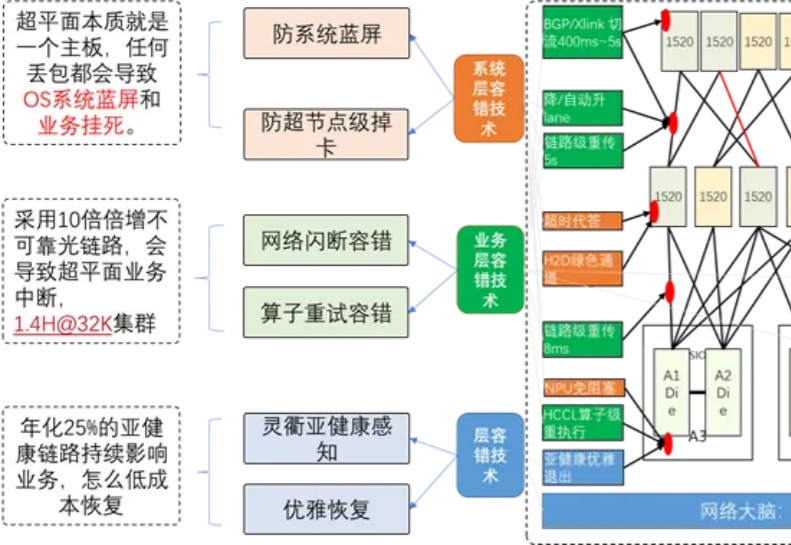
你是否注意到,现在的 AI 越来越 "聪明" 了?能写小说、做翻译、甚至帮医生看 CT 片,这些能力背后离不开一个默默工作的 "超级大脑工厂"——AI 算力集群。

国内大厂探索AI变现呈现四类方式:模型产品(订阅)、模型服务(MaaS)、AI功能嵌入主业、算力基础设施。百度、阿里、腾讯、华为处于第一梯队,AI显著拉动营收增长;快手、字节、美图属第二梯队,AI提效主业或打造爆款应用初见成效;科大讯飞、昆仑万维尚处投入期。虽部分路径初步盈利,但巨额研发投入远超当前回报,尚无企业实现AI正现金流,技术投入更多带来市值提升效应。