有人只用API就猜出了GPT、Claude、Gemini的参数量?社区吵翻了
有人只用API就猜出了GPT、Claude、Gemini的参数量?社区吵翻了基于此,研究者在 89 个参数量已知的开源模型(规模从 1.35 亿到 1.6 万亿参数)上拟合出事实准确率与参数量的对数线性关系,拟合优度 R² = 0.917,并据此对闭源模型进行参数估算。
来自主题: AI技术研报
9458 点击 2026-05-01 13:13
 搜索
搜索
基于此,研究者在 89 个参数量已知的开源模型(规模从 1.35 亿到 1.6 万亿参数)上拟合出事实准确率与参数量的对数线性关系,拟合优度 R² = 0.917,并据此对闭源模型进行参数估算。

AI医疗最成熟的领域,迎来了一款重磅产品——颅脑CT超级智能体“小君医生2.0”。这是全球首个临床可用+检查项目级的颅脑CT智能体,能够覆盖90%的颅脑病变,诊断准确率达87.8%,90%以上病例无需修改或仅小幅度修改即可使用,将报告时效从15分钟大幅压缩至1分钟,已落地中国顶流三甲北京天坛医院,极大提升了医院影像诊断的效率。

过去十年,压缩在 CV 学术圈一直是个边缘方向——做生成、做大模型才是显学。但 SparcAI 的两位95后创始人各自做了多年压缩,然后在同一间 NTU 实验室相遇,两年后发布了 Sparc3D。模型 demo 上线当日冲上 HuggingFace Trending 榜首,论文被 NeurIPS 2025 录用。如今他们创办了 SparcAI,目标是一家世界模型公司。
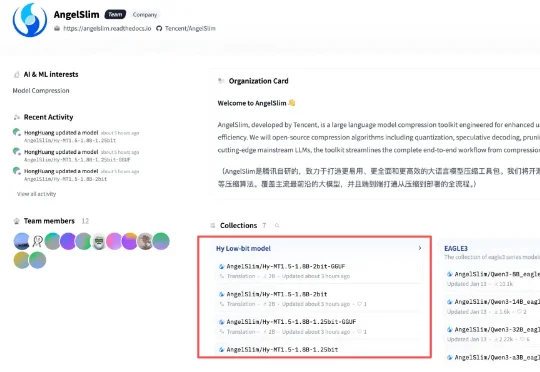
今日,腾讯混元开源翻译模型Hy-MT1.5-1.8B-1.25bit。该模型仅0.4G,就实现了33种语言高质量互译,且下载后可直接在手机本地离线运行,翻译表现优于谷歌翻译。这一原始模型的参数规模为1.8B,为降低用户手机内存压力,腾讯混元团队通过量化压缩推出了适配中高性能手机的2-bit、适配全系列手机的1.25-bit两种方案,模型体积分别被压缩至574MB、440MB。
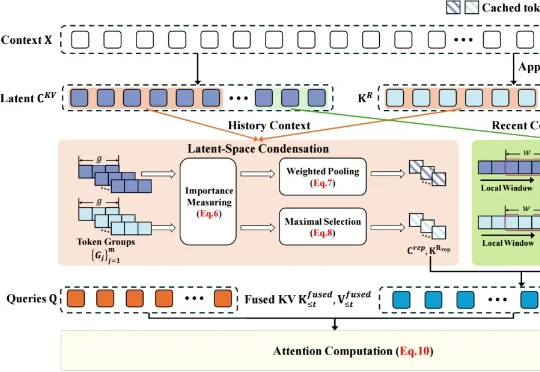
近日,琶洲实验室、华南理工大学、蔻町(AIGCode)等单位科研团队联合提出潜在空间压缩注意力(Latent-Condensed Attention,LCA),研究成果入选 ACL 2026。

哈尔滨工业大学(深圳)等机构的研究者提出了 ReBalance 方法,并首次系统性引入 Balanced Thinking 这一新视角。该工作的核心观点明确:高效推理的关键并非盲目压缩推理长度,而是在过度思考与思考不足之间维持动态平衡。

当谈及数学时,我们近乎本能地认为,数学是一个严谨、精确、不容置疑的完美逻辑体系,但在菲尔兹奖得主迈克尔・弗里德曼(Michael Freedman)眼中,人类真正创造和关心的数学,本质上是「柔软且可塑」的。

近日,哈尔滨工业大学(深圳)联合深圳河套学院、Independent Researcher提出了隐式思考模型 LRT(Latent Reasoning Tuning),通过一个轻量级的推理网络,将大模型冗长的「思维链」压缩为紧凑的隐式向量表征,一次前向计算即可完成推理,无需逐 token 生成数千字的中间推理过程。
Anthropic推出平台级产品:Claude Managed Agents,开发周期从数月压缩到几天,To B业务更进一步,这是直接给了一个Harness Agent的盒子,用户只管干活就行了,随着产品发布,A厂还发布了一篇Harness(Managed Agents)工程细节文章,感觉A厂就差说在座的都是xx了,再一次遥遥领先!我们一文来说清楚
长上下文推理已经成了VLM/LLM的默认形态。