
打破碎片化瓶颈!浙大&哈佛开源UniGeo,高保真相机可控编辑
打破碎片化瓶颈!浙大&哈佛开源UniGeo,高保真相机可控编辑UniGeo通过视频模型的连续视角先验与统一几何引导,实现稳定、高质量的相机可控图像生成,全面超越现有方法,在不同幅度的相机运动中提升跨视角一致性与结构稳定性。
来自主题: AI技术研报
6599 点击 2026-05-07 15:04
 搜索
搜索
UniGeo通过视频模型的连续视角先验与统一几何引导,实现稳定、高质量的相机可控图像生成,全面超越现有方法,在不同幅度的相机运动中提升跨视角一致性与结构稳定性。
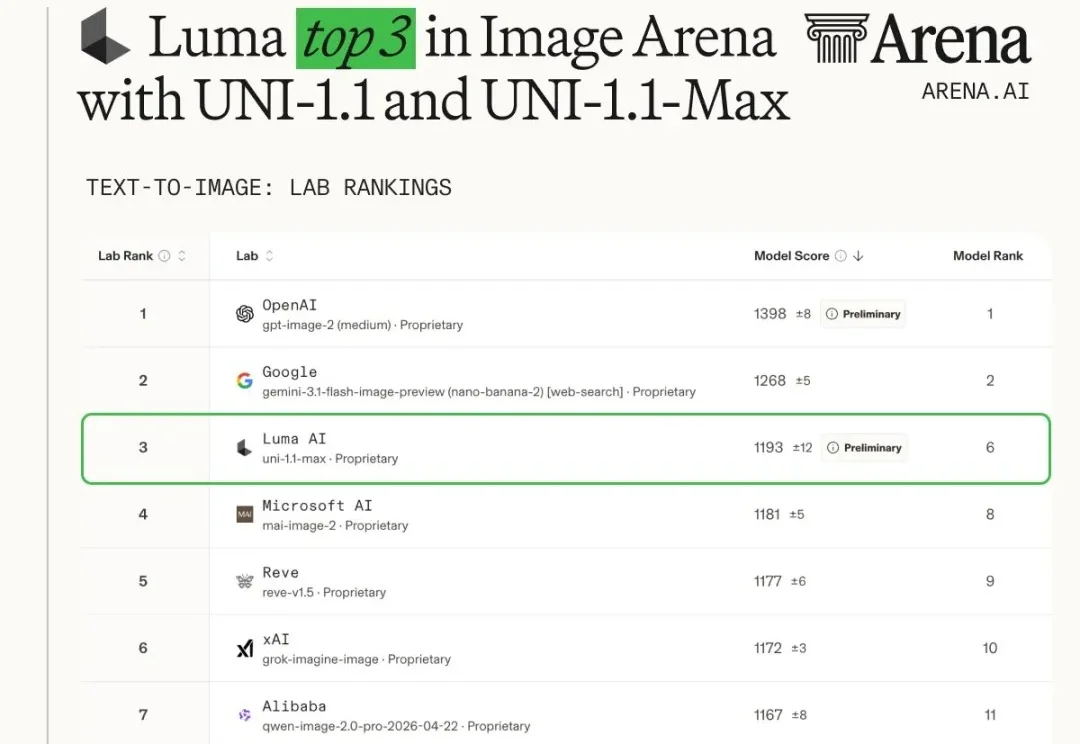
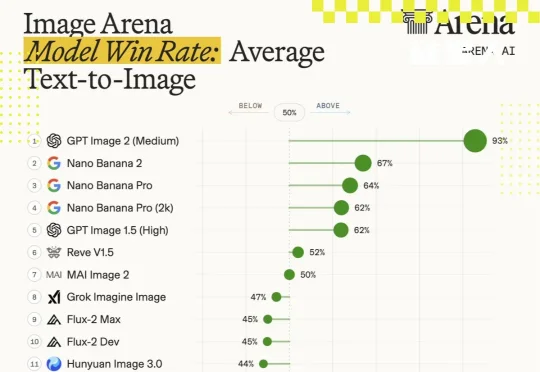
今年以来,图像生成模型的迭代节奏明显加快。
GPT Image 2 凭什么这么强?是扩散模型又迭代了一版?是把 DiT 的参数量从 7B 扩到 20B?是训了更多高质量数据?先给结论:OpenAI 很可能已经不在“纯扩散模型”这条主赛道上了。他们已经把图像生成从“美术课”调到了“语文课”——用一个能读懂指令、能记住上下文、能理解物体关系的 LLM 主导语义规划,至于最后一步的像素生成,可能由扩散组件或其他解码器完成。

“这是我过去四个月一直在研究的东西!”

当强化学习后训练的大规模 rollout 已经被证明能够提升图像生成模型的偏好对齐能力,推理负担就成了制约训练速度的核心瓶颈。来自 NVIDIA、港大和 MIT 的团队提出的 Sol-RL,通过「FP4 先探索、BF16 再训练」的后训练框架,将达到等效 reward 水平的收敛速度最高提升到 4.64x,在训练速度与对齐效果之间给出了一条更具工程可行性的解法。

近日,京东开源图像模型JoyAI-Image-Edit,将空间智能纳入图像理解与编辑,让AI开始处理真实世界中的空间关系,让模型真正“理解空间,编辑空间”。简单解释,这是一个以空间智能为核心的图像生成与编辑模型,让 AI 真正“看懂”三维空间,从而让生成更合理、编辑更精准。

过去两年,图像生成模型在质感和审美上一路狂飙,但大多仍是 “直接出图” 的范式。

AI不再只是把两个物体「放一起」,而是真正造出一个新实体。VMDiff模型通过分阶段策略:先拼接保留信息,再插值融合成整体,并自动调节平衡,让生成结果既像两者,又自然统一。 过去,很多图像生成模型都能同时画出两个物体;但要让它们真正「长成一个新物体」,其实远没有那么简单。

3月30日,阿里巴巴内部发布了 Wan2.7-Image 图像生成与编辑统一模型。根据官方公布的数据,在人类偏好盲测评分中,Wan2.7-Image 目前位列国内第一。从放出的评测雷达图来看,无论是文本生图(Text-to-Image)还是综合图像编辑(Image Editing),它的各项指标基本都盖过了市面上主流的几家头部模型。

Cheng Lou:React 核心团队成员,参与 ReactJS 的早期开发;主导了 ReasonML(后来演变为 ReScript)的开发;目前在 Midjourney 工作,参与 AI 图像生成平台的开发。