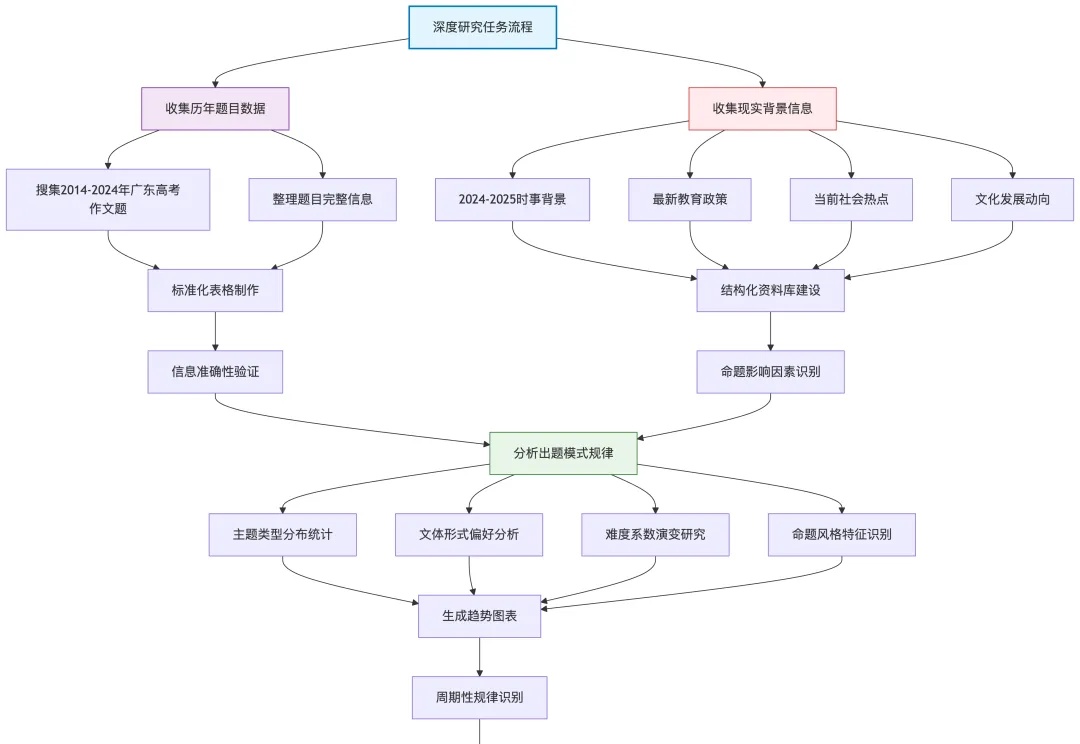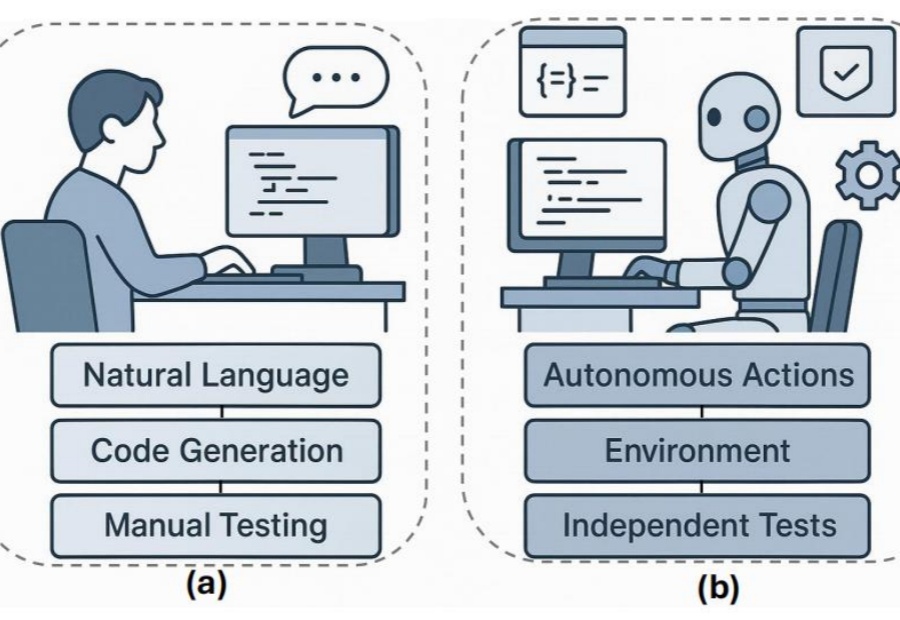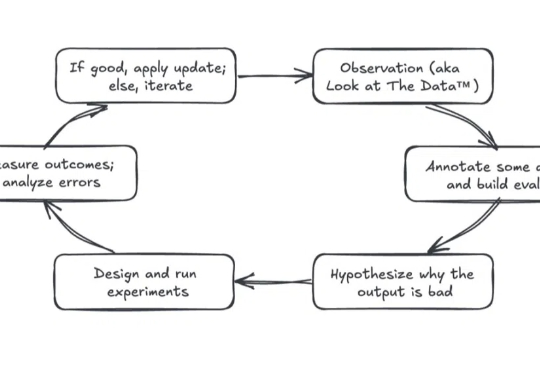
姚顺雨提到的「AI下半场」,产品评估仍被误解
姚顺雨提到的「AI下半场」,产品评估仍被误解前段时间,OpenAI 研究员姚顺雨发表了一篇主题为「AI 下半场」的博客。其中提到,「接下来,AI 的重点将从解决问题转向定义问题。在这个新时代,评估的重要性将超过训练。我们需要重新思考如何训练 AI 以及如何衡量进展,这可能需要更接近产品经理的思维方式。」(参见《清华学霸、OpenAI 姚顺雨:AI 下半场开战,评估将比训练重要》)
来自主题: AI资讯
8162 点击 2025-06-03 13:40