
强化学习教父重出江湖, 生成式AI的时代要结束了?
强化学习教父重出江湖, 生成式AI的时代要结束了?过去两年,AI靠模仿人类席卷世界。但强化学习之父Richard Sutton却说:「GenAI的时代正在结束。」他带着图灵奖的荣光,加入一家几乎没人听过的公司——ExperienceFlow.AI,他要让AI不靠人类数据喂养,而靠「经验」觉醒。
来自主题: AI资讯
9916 点击 2025-11-07 15:04
 搜索
搜索
过去两年,AI靠模仿人类席卷世界。但强化学习之父Richard Sutton却说:「GenAI的时代正在结束。」他带着图灵奖的荣光,加入一家几乎没人听过的公司——ExperienceFlow.AI,他要让AI不靠人类数据喂养,而靠「经验」觉醒。
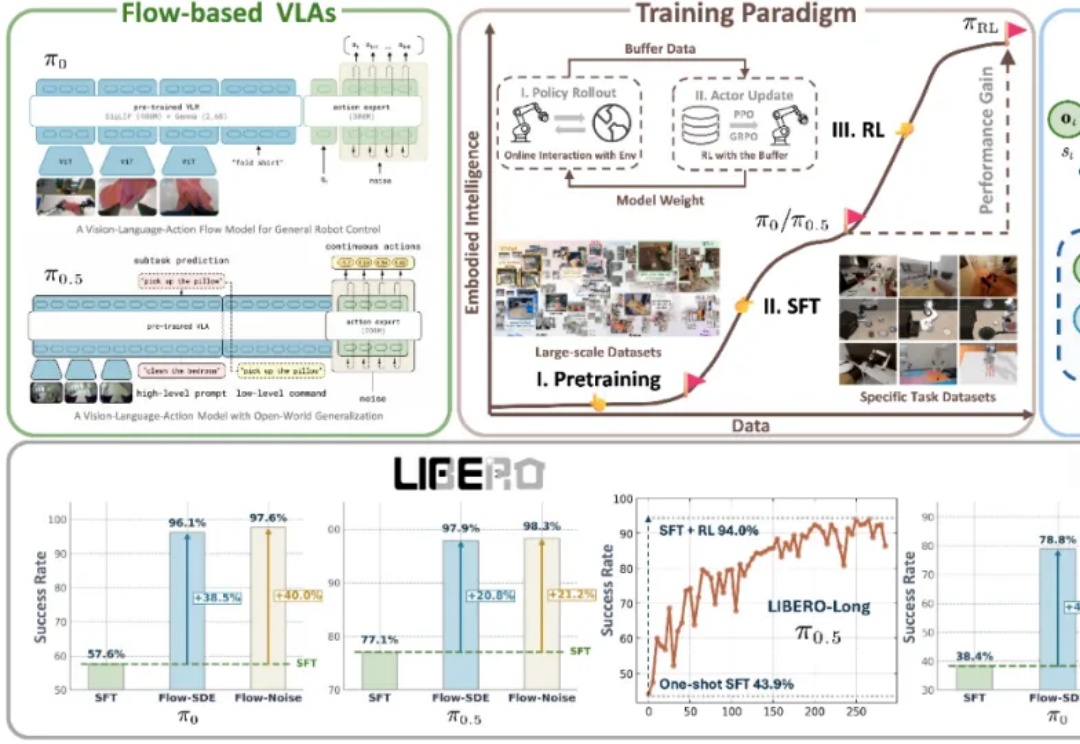
近年来,基于流匹配的 VLA 模型,特别是 Physical Intelligence 发布的 π0 和 π0.5,已经成为机器人领域备受关注的前沿技术路线。流匹配以极简方式建模多峰分布,能够生成高维且平滑的连续动作序列,在应对复杂操控任务时展现出显著优势。
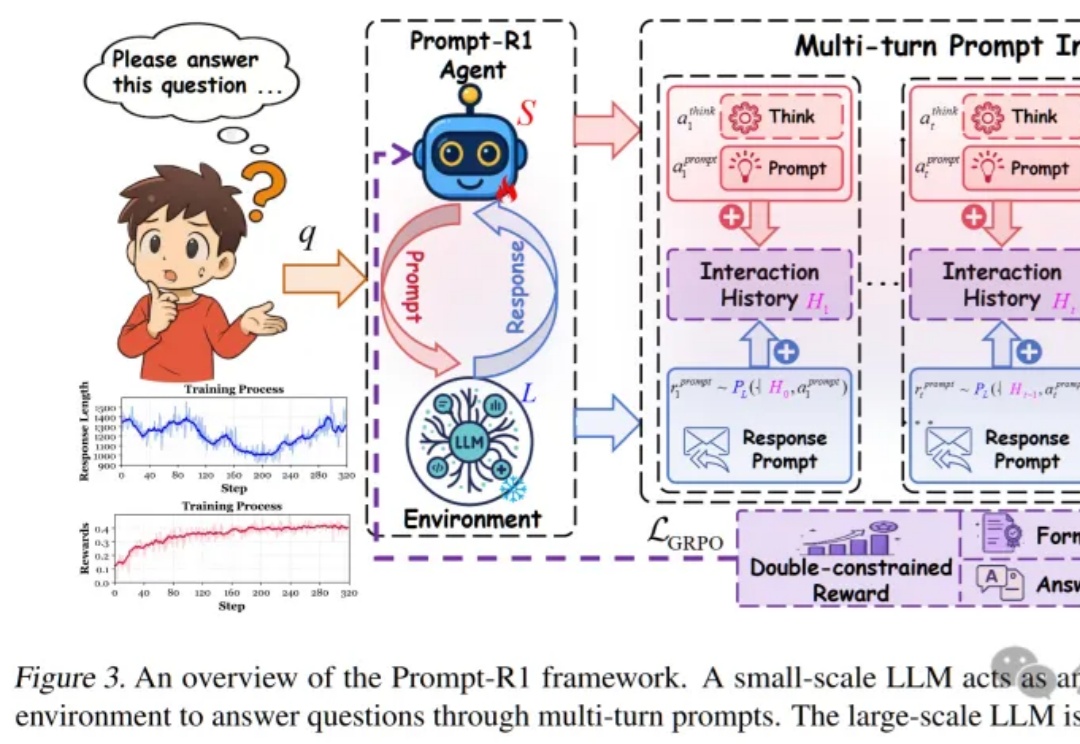
这篇论文提出了一种颠覆性的协作模式,即通过强化学习训练一个“小模型”作为智能代理(Agent),让它自动学会如何写出完美的Prompt,一步步引导任何一个“大模型”完成复杂推理,实现了真正的“AI指挥AI”。

传统智能体系统难以兼顾稳定性和学习能力,斯坦福等学者提出AgentFlow框架,通过模块化和实时强化学习,在推理中持续优化策略,并使小规模模型在多项任务中超越GPT-4o,为AI发展开辟新思路。
论文第一作者何浩然是香港科技大学博士生,研究方向包括强化学习和基础模型等,研究目标是通过经验和奖励激发超级智能。共同第一作者叶语霄是香港科技大学一年级博士。通讯作者为香港科技大学电子及计算机工程系、计

月之暗面在这一方向有所突破。在一篇新的技术报告中,他们提出了一种新的混合线性注意力架构 ——Kimi Linear。该架构在各种场景中都优于传统的全注意力方法,包括短文本、长文本以及强化学习的 scaling 机制。
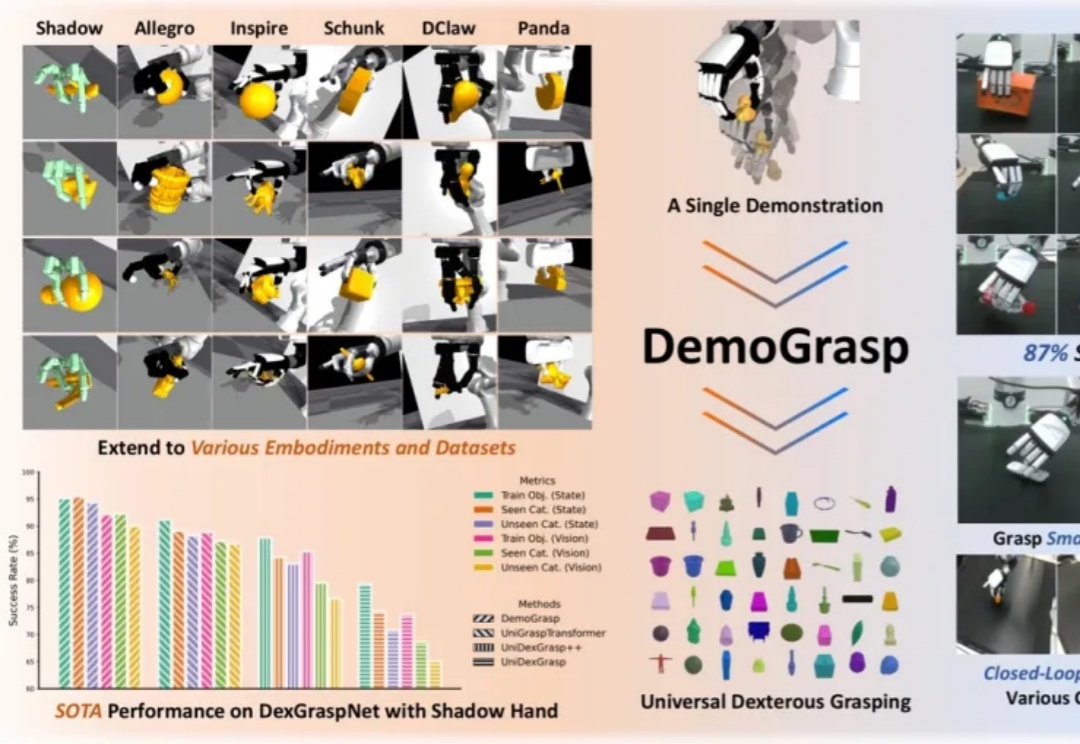
在灵巧手通用抓取的研究中,由于动作空间维度高、任务具有长程探索特征且涉及多样化物体,传统强化学习(RL)面临探索效率低、奖励函数及训练过程设计复杂等挑战。

最新进展,Cursor 2.0正式发布,并且首次搭载了「内部」大模型。 没错,不是GPT、不是Claude,如今模型栏多了个新名字——Composer。实力相当炸裂:据官方说法,Composer仅需30秒就能完成复杂任务,比同行快400%
强化学习是近来 AI 领域最热门的话题之一,新算法也在不断涌现。

今天要讲的On-Policy Distillation(同策略/在线策略蒸馏)。这是一个Thinking Machines整的新活,这个新策略既有强化学习等在线策略方法的相关性和可靠性;又具备离线策略(Off-policy)方法的数据效率。