
Stability AI开源3B代码生成模型:可补全,还能Debug
Stability AI开源3B代码生成模型:可补全,还能DebugStable Diffusion 3 还没全面开放,这家公司的代码生成模型先来了。本周一,Stability AI 开源了小体量预训练模型 Stable Code Instruct 3B。
来自主题: AI技术研报
7839 点击 2024-03-27 11:15
 搜索
搜索
Stable Diffusion 3 还没全面开放,这家公司的代码生成模型先来了。本周一,Stability AI 开源了小体量预训练模型 Stable Code Instruct 3B。

受人类视觉系统的启发,MVDiffusion++结合计算方法高保真和人类视觉系统灵活性,可以根据任意数量的无位姿图片, 生成密集、高分辨率的有位姿图像,实现了高质量的3D模型重建。

近日,Stability AI又发布了新作SV3D,基于视频扩散模型的SV3D将3D模型生成的效果提升了一大截,模型权重已在huggingface开放。

3D 生成领域迎来新的「SOTA 级选手」,支持商用和非商用。Stability AI 的大模型家族来了一位新成员。昨日,Stability AI 继推出文生图 Stable Diffusion、文生视频 Stable Video Diffusion 之后,又为社区带来了 3D 视频生成大模型「Stable Video 3D」(简称 SV3D)。

Stable Diffusion背后公司Stability AI又上新了。 这次带来的是图生3D方面的新进展: 基于Stable Video Diffusion的Stable Video 3D(SV3D),只用一张图片就能生成高质量3D网格。

【新智元导读】利用文本生成图片(Text-to-Image, T2I)已经满足不了人们的需要了,近期研究在T2I模型的基础上引入了更多类型的条件来生成图像,本文对这些方法进行了总结综述。
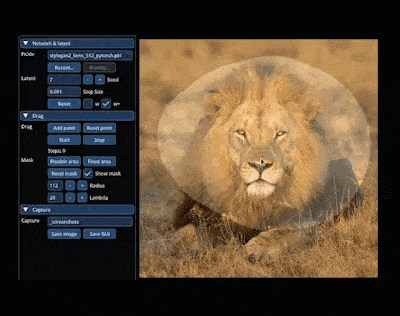
年 5 月,动动鼠标就能让图片变「活」得研究 DragGAN 吸引了 AI 圈的关注。通过拖拽,我们可以改变并合成自己想要的图像,比如下图中让一头狮子转头并张嘴!

本文编译自播客节目a16z。Stability AI的科学家Andreas Blattmann和Robin Rombach与a16z的合伙人Anjney Midha共同探讨从文本到视频人工智能的前沿世界。

近期的研究表明,采用扩散模型的规划模块能够同时生成长序列的轨迹规划,这更加符合人类的决策模式。此外,扩散模型在策略表征和数据合成方面也能为现有的决策智能算法提供更优的选择。

针对图像编辑中的扩散模型,中科院联合Adobe和苹果公司的研究人员发布了一篇重磅综述。