
被困在考场里的大模型
被困在考场里的大模型昨天,大名鼎鼎的 Claude 4.8 发布了。 科技圈照例是一片欢呼。 看官方放出来的一堆评测数据,依然是碾压级别的,尤其是说代码(Coding)能力有了史诗级的提升,简直像交了一份满分答卷。
来自主题: AI资讯
8840 点击 2026-05-30 10:50
 搜索
搜索
昨天,大名鼎鼎的 Claude 4.8 发布了。 科技圈照例是一片欢呼。 看官方放出来的一堆评测数据,依然是碾压级别的,尤其是说代码(Coding)能力有了史诗级的提升,简直像交了一份满分答卷。
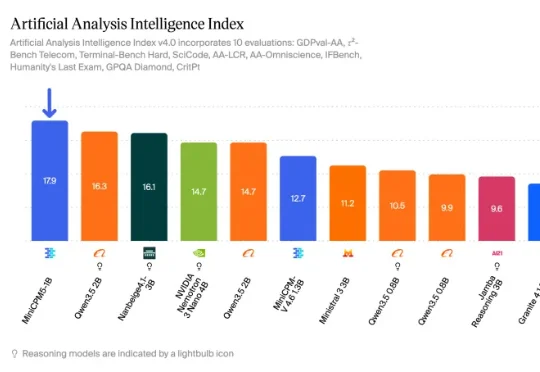
我去搜了下 MiniCPM5-1B 的数据,发现面壁智能刚刚把背后的核心数据集给开源了。一共是两份 L3 级数据集:Ultra-FineWeb-L3 :600B tokens,中英文都有,是目前最大的中文开源合成预训练数据集。

Omdia这份名为《2026全球AI工厂市场格局》的报告,点明了新时代的核心逻辑——决定胜负的,不再是谁拥有更多GPU,而是谁能够更高效地把“电力+算力+数据”转化为真正有价值的Token。

Google DeepMind研究院姚顺宇最近接受媒体人采访时说:做一个好的产品经理,是一个我现在想不明白该怎么训练AI去做的事。言外之意,AI时代产品经理很难被替代。招聘市场已经给出了答案。根据脉脉2026年1—4月的数据,热招岗位里大模型算法排第一,产品经理排第二,AI产品经理也排到了前五的位置。

光正在进入AI算力系统,但这次不只是拿来传数据,而是直接参与计算。
OpenAI 公开介绍 Computer-Using Agent 时,讲的也是这个方向:模型针对图形界面交互做过训练,能把屏幕理解、任务目标和鼠标键盘动作接起来。鼠标会动只是表面。遇到按钮位置变化、弹窗多一层、页面慢一点时,它还能重新看屏幕,继续判断下一步。
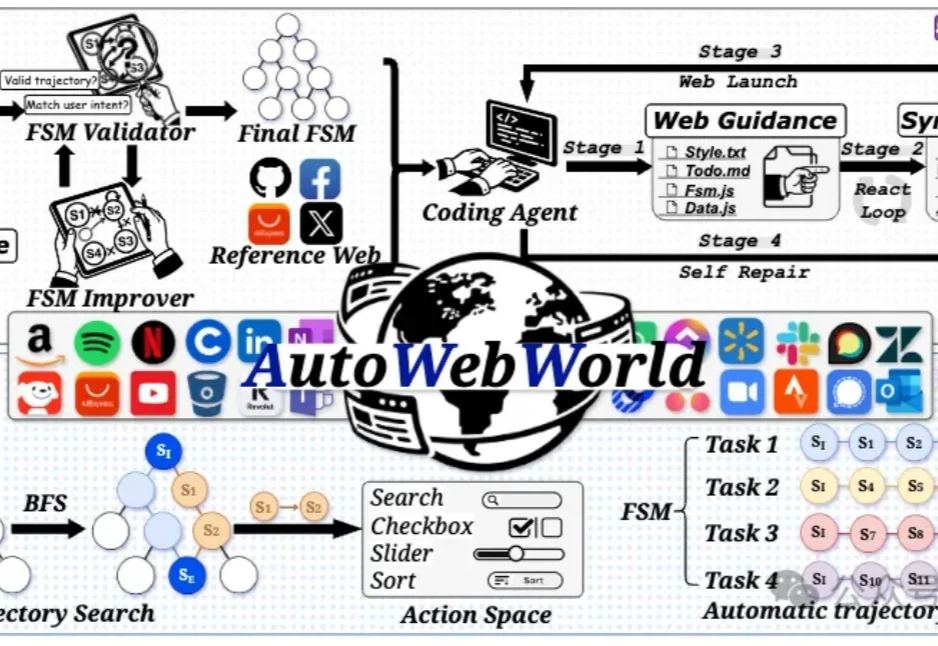
训练一个真正会用网页的GUI Agent,最自然的思路通常是: 去真实网站上操作,收集轨迹,再拿来训练。
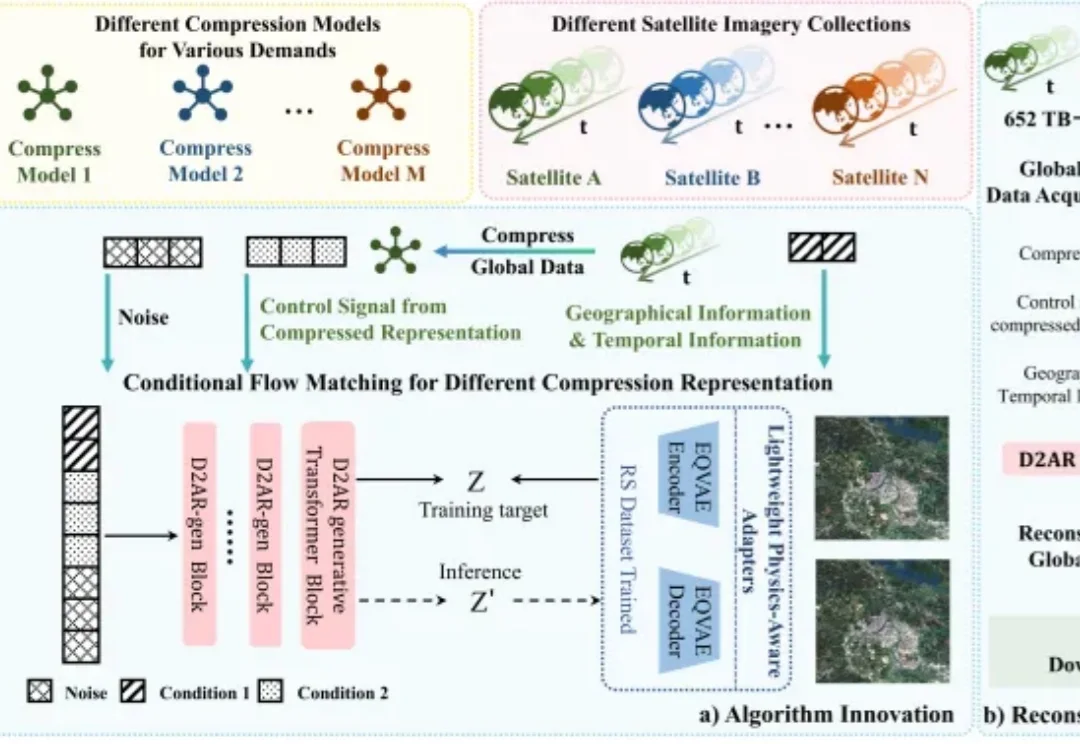
随着全球遥感卫星持续运行,地球观测数据正在快速增长。多源、多时相、多光谱遥感影像为国土监测、生态评估、灾害预警、气候变化研究等任务提供了重要数据基础,但也带来了显著的存储、传输和计算压力。

2026 年初,国内具身智能赛道掀起了一波开源潮,越来越多团队开始公开自己的视觉-语言-动作(VLA)模型、数据集与训练框架。与此同时,行业竞争也逐渐集中到 benchmark 成绩、任务成功率以及跨任务泛化能力上,尤其是在标准化或已训练任务中的表现。

过去的大模型 scaling law 通常回答的是:当模型参数量、数据量和训练计算量增加后,loss 会如何下降。