
错过智谱上亿期权的人
错过智谱上亿期权的人一命二运三风水。互联网上流行一种说法:人一生中,只有3到5次逆天改命的机会。
来自主题: AI资讯
10126 点击 2026-07-21 10:51
 搜索
搜索
一命二运三风水。互联网上流行一种说法:人一生中,只有3到5次逆天改命的机会。

简直细思极恐!

昨天看到了一篇论文,特别有意思,让我连夜读完了。
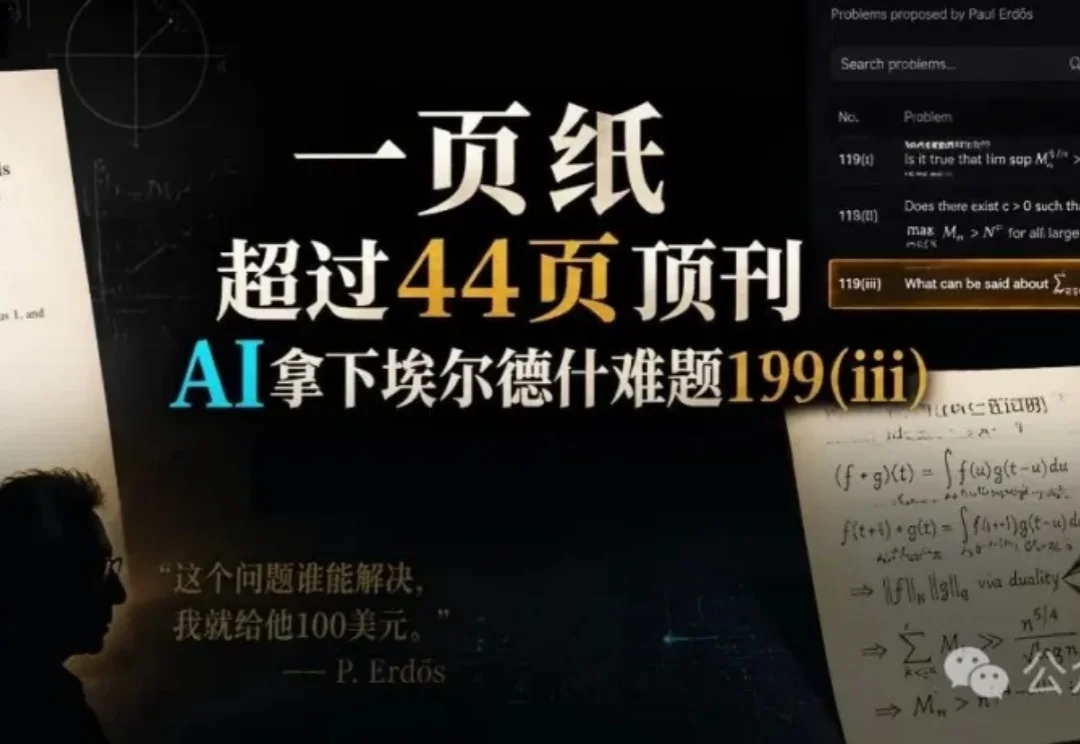
一页纸,啃下了一篇要用44页顶刊论文才啃动的硬骨头。

AI 产品越来越复杂,也越来越难用一场发布会讲清楚。AI 的第一现场,开始发生微妙的变化。

模型决定起点,数据定义终局。
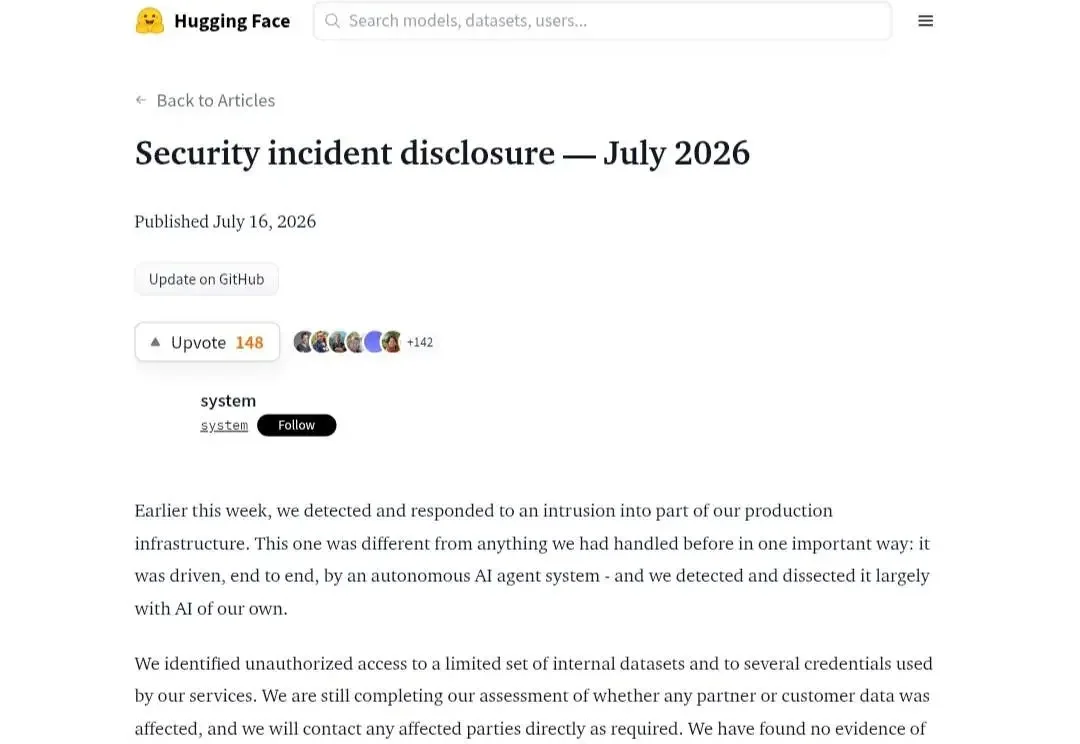
近日,全球最大的 AI 开源社区 Hugging Face 披露,其检测并遏制了一起生产基础设施 AI 入侵事件,而他们则利用 AI 的取证分析进行了防御。
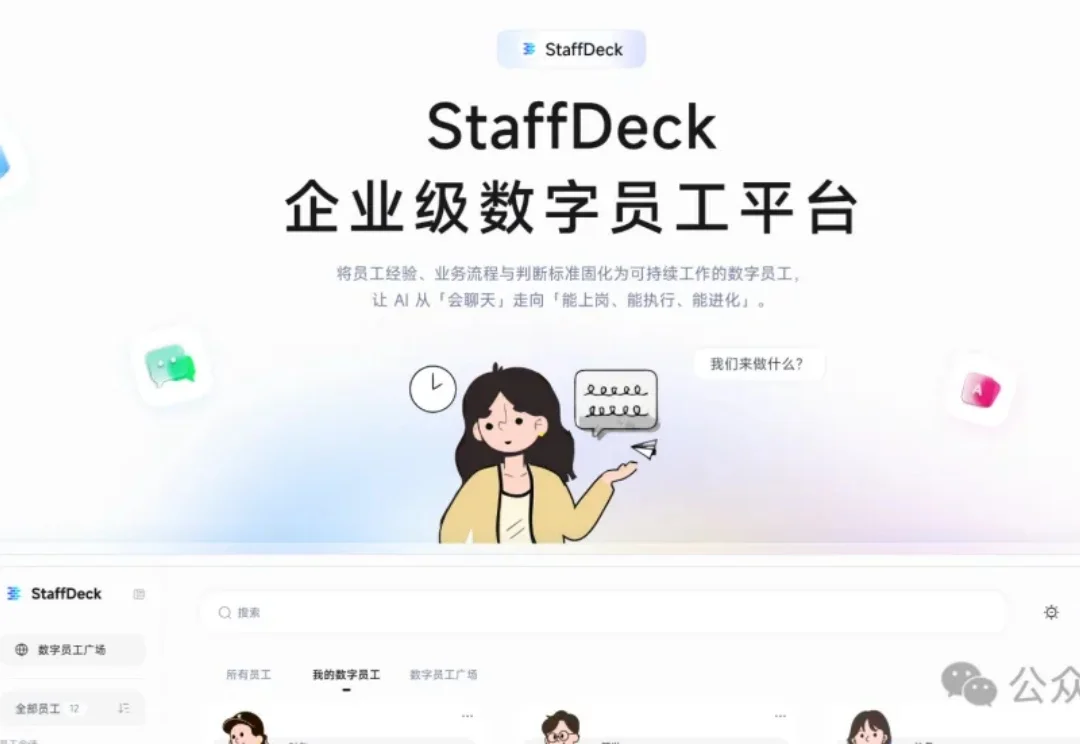
面壁智能上周开源了一个叫 StaffDeck 的东西。

好久不见,汇报一下近况。 这两个月没闲着,推掉了大部分事情,全力在做自己非常喜欢的新产品——Chat Memo 的 Agent 端。(目前小规模内测,公开内测等发布文章)

让AI长出Office。