
「被动感知」到「理解接触」!它石智航重磅发布OmniVTA视触觉世界模型
「被动感知」到「理解接触」!它石智航重磅发布OmniVTA视触觉世界模型从「被动感知」到「主动预测」,首个视触觉世界模型让机器人真正学会「理解接触」。
来自主题: AI技术研报
6253 点击 2026-03-26 14:47
 搜索
搜索
从「被动感知」到「主动预测」,首个视触觉世界模型让机器人真正学会「理解接触」。
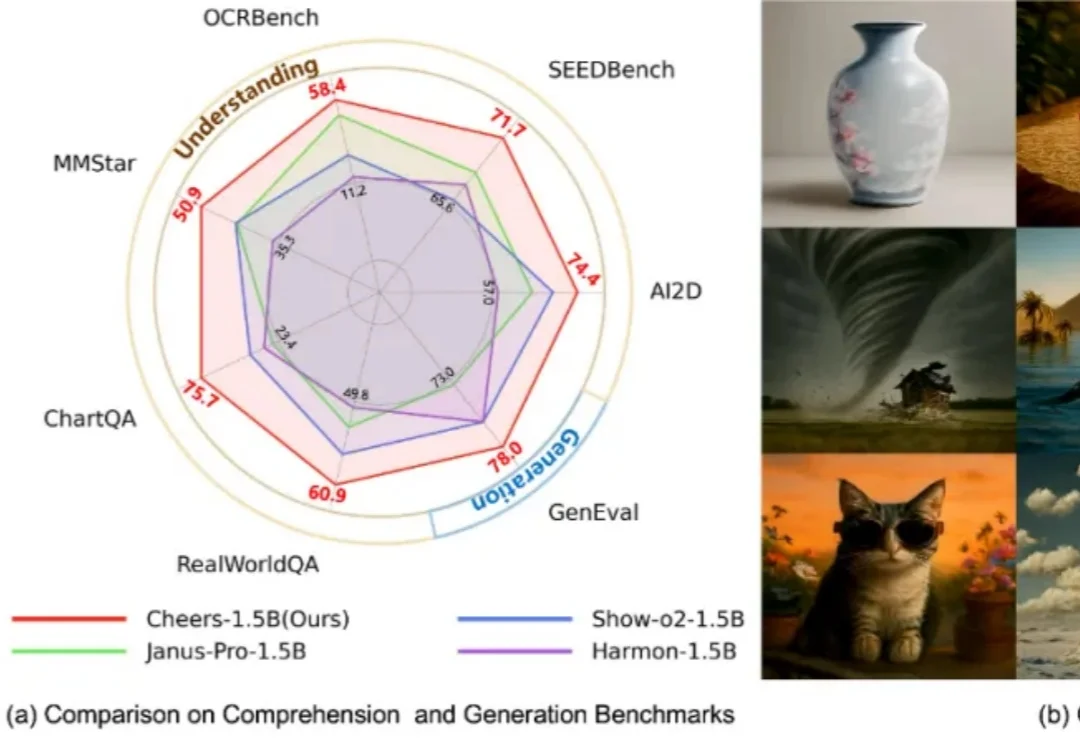
过去几年,多模态模型在理解任务上快速演进,图像问答、OCR、视觉推理、跨模态对话等能力不断提升;与此同时,图像生成模型也在视觉质量、指令遵循和细节表达上持续突破。下一步一个自然的问题是:能否用同一个模型,同时做好理解与生成?这正是统一多模态模型(Unified Multimodal Models, UMMs)正在回答的问题。

谷歌一篇论文,直接让存储巨头们「集体失眠」,一夜市值蒸发几百亿!最新博客官宣TurboQuant算法,直接将缓存压到3-bit,内存占用只有1/6。

ICLR'26新研究CPiRi打破时序预测僵局:用冻结底座提取时序特征,轻量模块专注学习通道间真实关系,不靠位置编码「背答案」。测试中通道乱序性能零波动,仅用25%数据即可泛化至全网络,真正实现鲁棒与精准双赢。

你以为AI答错就一定是幻觉?不,它也可能是在故意骗你。
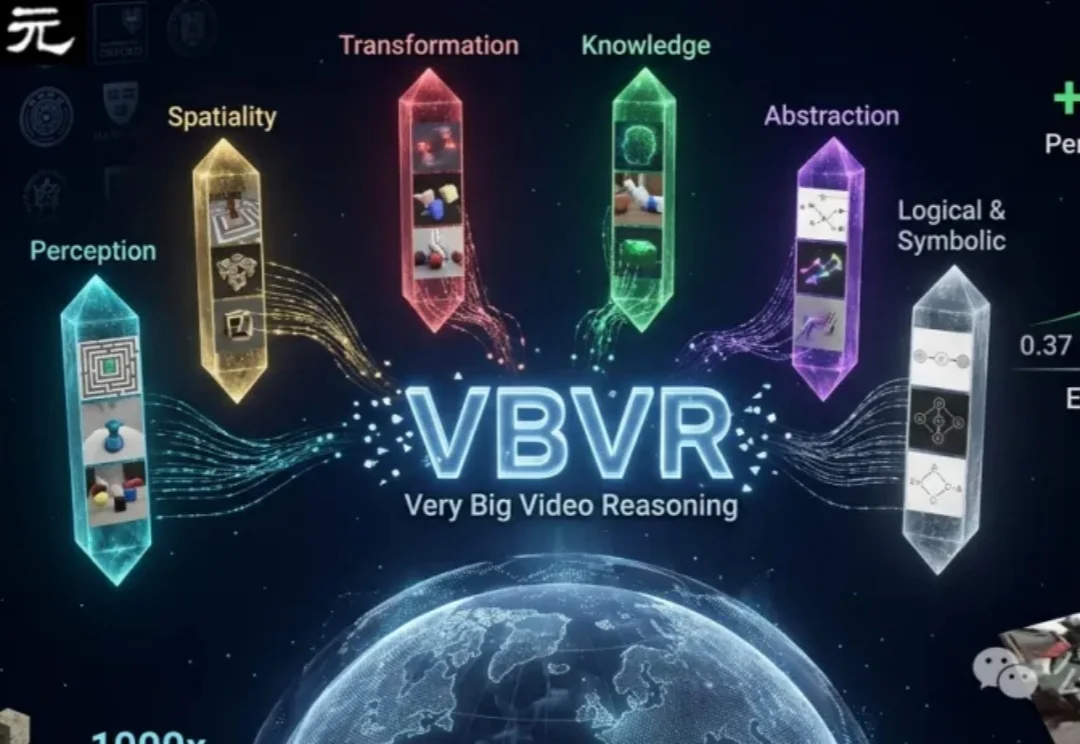
AI视频生成已能「画得像」,但不会「想得对」。VBVR推出百万级视频推理数据集,首次系统评测模型对空间、物理、逻辑和抽象的推理能力,发现顶尖模型通过率仅68%,暴露其缺乏真实认知,推动视频AI从「视觉模仿」迈向「智能推理」。
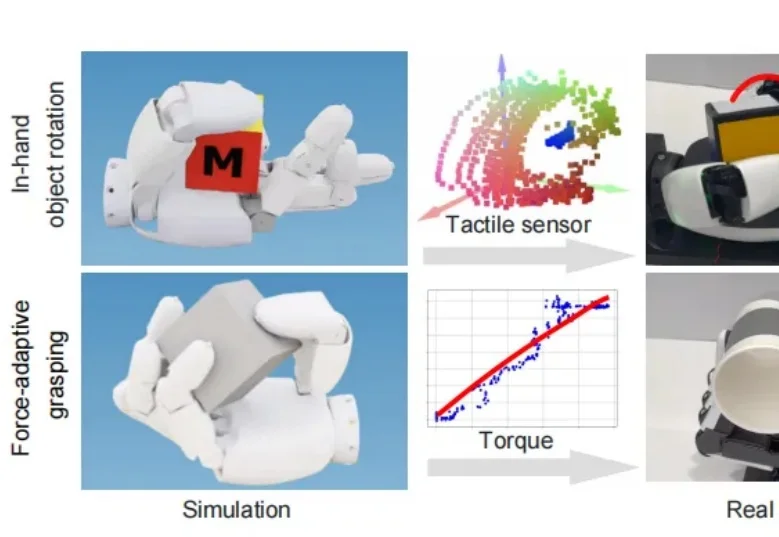
实现具备人类水平的灵巧操作能力,是机器人学领域长期以来的核心挑战之一。尽管多指灵巧手在硬件上具备了类似人类的潜力,但由于接触丰富的物理特性和非理想的驱动机制,训练能够直接部署在真实硬件上的控制策略仍然非常困难。
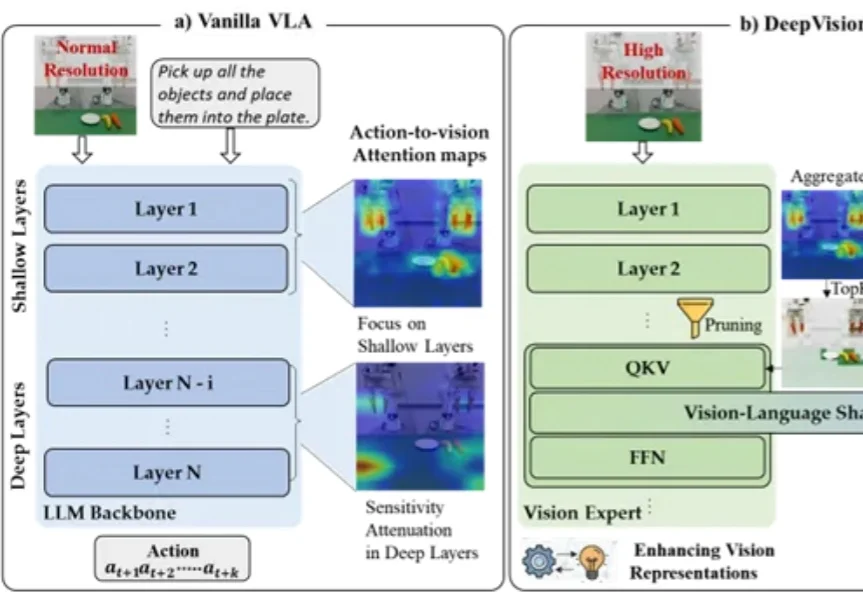
“把水果放进盘子里”——机器人看懂了指令,开始执行,却在最后关头抓偏了。

在大模型后训练阶段,监督微调(SFT)和强化学习(RL)是两根不可或缺的支柱。SFT 利用高质量的离线(Off-policy)数据快速注入知识,但受限于静态数据分布,泛化能力往往容易触及天花板并带来灾难性遗忘;RL 则允许模型在探索中不断自我迭代,产生与当前策略同分布(On-policy)的数据,上限极高,但往往伴随着训练极度不稳定、计算资源消耗巨大的痛点。
大模型开发者常面临一个两难选择:要速度,还是省显存?