
大厂抢郭达雅进行时!DeepSeek核心成员还是个“综艺巨佬”
大厂抢郭达雅进行时!DeepSeek核心成员还是个“综艺巨佬”DeepSeek,又有核心工程师流入江湖—— 郭达雅,V2、V3、R1等一系列模型的核心作者,被曝离职。
来自主题: AI资讯
6720 点击 2026-03-23 10:21
 搜索
搜索
DeepSeek,又有核心工程师流入江湖—— 郭达雅,V2、V3、R1等一系列模型的核心作者,被曝离职。

在 AIGC 领域,基于参考图像的图像修复(Reference-based Inpainting)一直是一项备受关注的核心任务,它旨在利用参考图像引导修复过程,生成视觉一致的内容。这一技术在广告营销和电商领域有着巨大的应用潜力,例如让 AI 自动生成 “真人手持或穿戴商品” 的展示图。

一张蓝锥嘴雀的图片,你能认出它是“鸟”,但能认出它是“鸟纲-雀形目-唐纳雀科-锥嘴雀属-蓝锥嘴雀”吗?

这两年,扩散语言模型(Diffusion LLM)一直是个很有讨论度的方向。

多模态大模型,到底有多“嘴硬”? 浙江大学联合阿里巴巴、香港城市大

目前,该论文已录用至 CVPR 2026,相关数据集和模型训练训练和推理代码将逐步开源:究其原因,一个好故事并非一堆漂亮镜头的简单拼接,而是一个有结构、有逻辑的叙事整体。
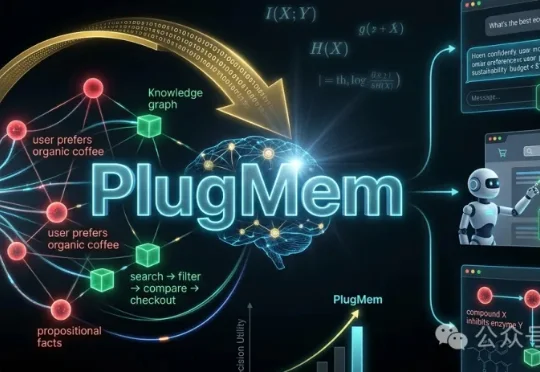
现在的AI agent往往把长交互历史直接存起来,但很难高效复用。最朴素的方法直接从「原始记忆」里检索,但常常把模型淹没在冗长、低价值的上下文里。PlugMem把经验转化为结构化、可复用的知识,并提出一个任务无关(task-agnostic)的统一记忆模块,在多种Agent基准上提升性能,同时消耗更少。

在此背景下,浙江大学研究团队提出了 EasySteer——一个基于 vLLM 构建的高性能、可扩展 LLM Steering 统一框架。该框架通过与 vLLM 推理引擎的深度集成,相比现有 Steering 框架实现了 10.8-22.3 倍的推理加速,同时提供更细粒度的干预控制,并为八大应用场景提供了预计算 Steering 向量与完整复现示例,方便研究者快速上手和对照复现。

3 月 20 日,知名 AI 代码编辑器 Cursor 高调发布了所谓的编程模型 Composer 2,结果被网友质疑「套壳」 Kimi K2.5。而从官方口径来看, Composer 2 的性能简直是降维打击:全基准大幅领先前代,首次引入持续预训练,叠加大规模强化学习,能解决需要数百个操作的高难度编程任务。

Soul AI 团队(Soul AI Lab) 发布了新的开源模型 SoulX-LiveAct,技术报告中具体提到,该工作能够在 2 张 H100/H200 条件下,达到 20 FPS 的实时流式推理能力,且支持输入图像、音频和指令驱动,即可生成表情生动、情绪可控、拥有丰富全身动作的实时数字人视频。