
让AI读懂「言外之意」:AI4SG团队发布首个心理健康污名语料库,破解隐性偏见识别难题
让AI读懂「言外之意」:AI4SG团队发布首个心理健康污名语料库,破解隐性偏见识别难题心理健康问题影响着全球数亿人的生活,然而患者往往面临着双重负担:不仅要承受疾病本身的痛苦,还要忍受来自社会的偏见和歧视。世界卫生组织数据显示,全球有相当比例的心理健康患者因为恐惧社会歧视而延迟或拒绝治疗。
来自主题: AI技术研报
8774 点击 2025-08-08 11:41
 搜索
搜索
心理健康问题影响着全球数亿人的生活,然而患者往往面临着双重负担:不仅要承受疾病本身的痛苦,还要忍受来自社会的偏见和歧视。世界卫生组织数据显示,全球有相当比例的心理健康患者因为恐惧社会歧视而延迟或拒绝治疗。
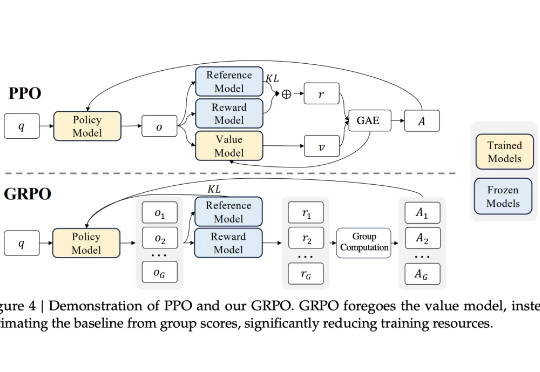
众所周知,大型语言模型的训练通常分为两个阶段。第一阶段是「预训练」,开发者利用大规模文本数据集训练模型,让它学会预测句子中的下一个词。第二阶段是「后训练」,旨在教会模型如何更好地理解和执行人类指令。

强化学习(RL)范式虽然显著提升了大语言模型(LLM)在复杂任务中的表现,但其在实际应用中仍面临传统RL框架下固有的探索难题。
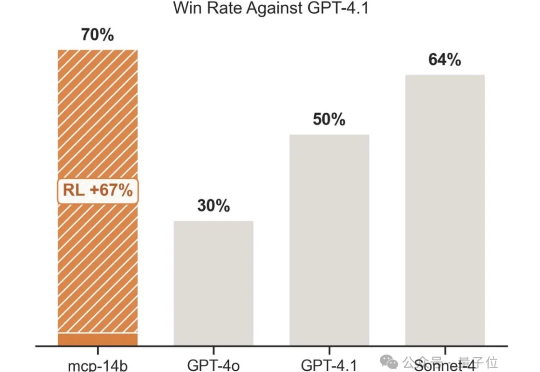
强化学习+任意一张牌,往往就是王炸。专注于LLM+RL的科技公司OpenPipe提出全新开源强化学习框架——MCP·RL。
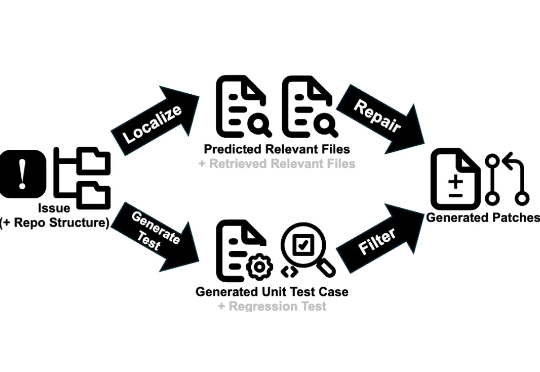
近日,一项由北京大学、字节跳动 Seed 团队及香港大学联合进行的研究,提出了一种名为「SWE-Swiss」的完整「配方」,旨在高效训练用于解决软件工程问题的 AI 模型。研究团队推出的 32B 参数模型 SWE-Swiss-32B,在权威基准 SWE-bench Verified 上取得了 60.2% 的准确率,在同尺寸级别中达到了新的 SOTA。
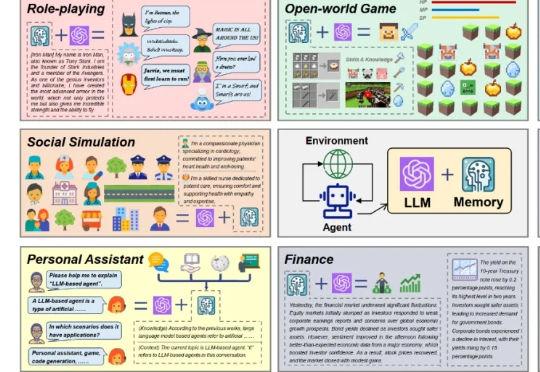
近期,基于大语言模型的智能体(LLM-based agent)在学术界和工业界中引起了广泛关注。对于智能体而言,记忆(Memory)是其中的重要能力,承担了记录过往信息和外部知识的功能,对于提高智能体的个性化等能力至关重要。

大部分现有的文档检索基准(如MTEB)只考虑了纯文本。而一旦文档的关键信息蕴含在图表、截图、扫描件和手写标记中,这些基准就无能为力。为了更好的开发下一代向量模型和重排器,我们首先需要一个能评测模型在视觉复杂文档能力的基准集。
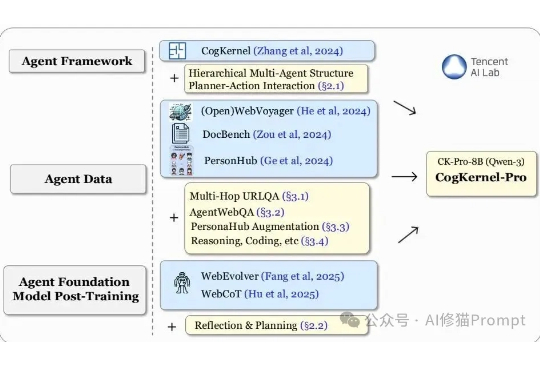
当AI智能体(Agent)开发的浪潮涌来,很多一线工程师却发现自己站在一个尴尬的十字路口:左边是谷歌、OpenAI等巨头深不可测的“技术黑盒”,右边是看似开放却暗藏“付费墙”的开源社区。大家空有场景和想法,却缺少一把能打开未来的钥匙。
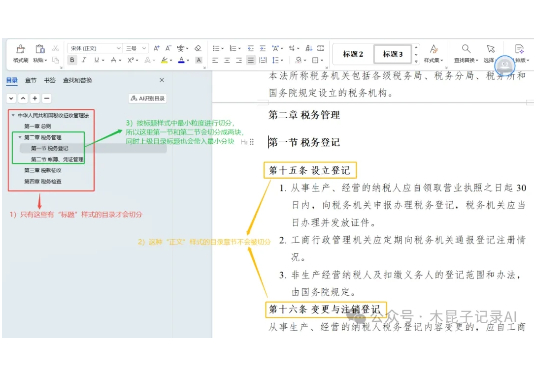
团队在自研知识库底座的过程中,想对比参考下RAGFlow,发现其切片方法缺乏详细说明和清晰案例,如果你也遇到以下问题,本文能帮你节省大量试错时间
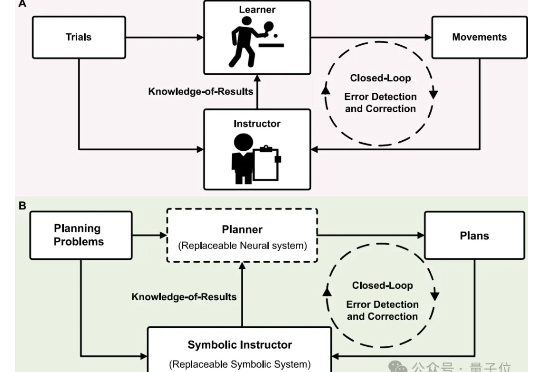
科研er看过来!还在反复尝试材料组合方案,耗时又耗力? 新型“神经-符号”融合规划器直接帮你一键锁定高效又精准的科研智能规划。