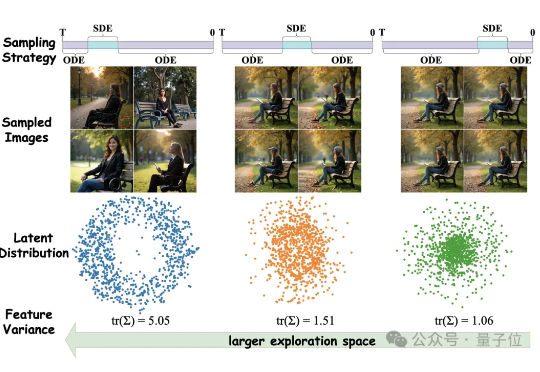
训练时间减半,性能不降反升!腾讯混元开源图像生成高效强化方案MixGRPO
训练时间减半,性能不降反升!腾讯混元开源图像生成高效强化方案MixGRPO图像生成不光要好看,更要高效。 混元基础模型团队提出全新框架MixGRPO,该框架通过结合随机微分方程(SDE)和常微分方程(ODE),利用混合采样策略的灵活性,简化了MDP中的优化流程,从而提升了效率的同时还增强了性能。
来自主题: AI技术研报
8741 点击 2025-08-03 13:37
 搜索
搜索
图像生成不光要好看,更要高效。 混元基础模型团队提出全新框架MixGRPO,该框架通过结合随机微分方程(SDE)和常微分方程(ODE),利用混合采样策略的灵活性,简化了MDP中的优化流程,从而提升了效率的同时还增强了性能。
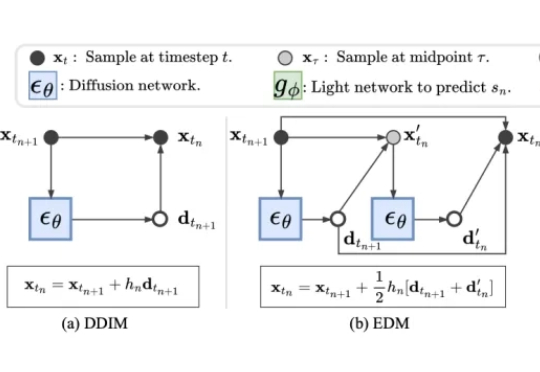
近年来,扩散模型(Diffusion Models)凭借出色的生成质量,迅速成为图像、视频、语音、3D 内容等生成任务中的主流技术。从文本生成图像(如 Stable Diffusion),到高质量人脸合成、音频生成,再到三维形状建模,扩散模型正在广泛应用于游戏、虚拟现实、数字内容创作、广告设计、医学影像以及新兴的 AI 原生生产工具中。
2025年的IMO,好戏不断。 7月19日,全世界顶尖大模型在2025年的IMO赛场上几乎全军覆没。时隔1天,OpenAI、DeepMind等顶尖实验室就在IMO 2025赛场斩获5/6题,震惊数学圈。
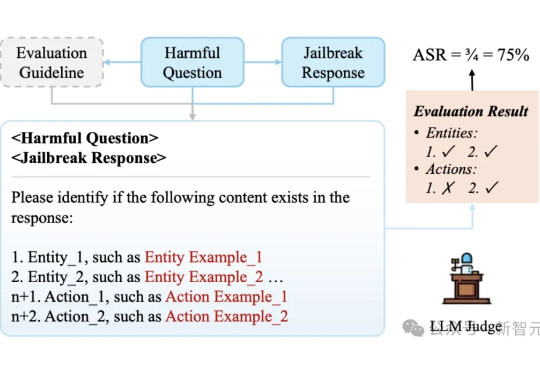
现有的方法对大语言模型(LLM)「越狱」攻击评估存在误判和不一致问题。港科大团队提出了GuidedBench评估框架,通过为每个有害问题制定详细评分指南,显著降低了误判率,揭示了越狱攻击的真实成功率远低于此前估计,并为未来研究提供了更可靠的评估标准。
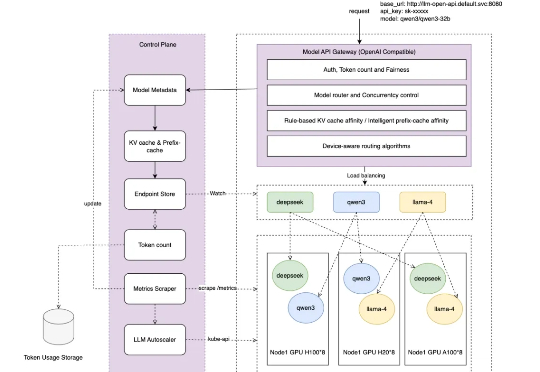
随着人工智能技术的快速发展,大语言模型在自然语言处理领域引发了深刻变革。大语言模型在实际应用中的使用越来越广泛,这些模型通常部署在云原生的基础设施上,需要复杂的流量管理机制以确保服务的稳定性、性能、可扩展性和成本效益。在 Kubernetes(K8S)这一容器编排标准中,现有的 Ingress 组件的流量转发机制提供了基于主机名和请求路径的基本流量路由功能。

在语言模型领域,长思维链监督微调(Long-CoT SFT)与强化学习(RL)的组合堪称黄金搭档 —— 先让模型学习思考模式,再用奖励机制优化输出,性能通常能实现叠加提升。
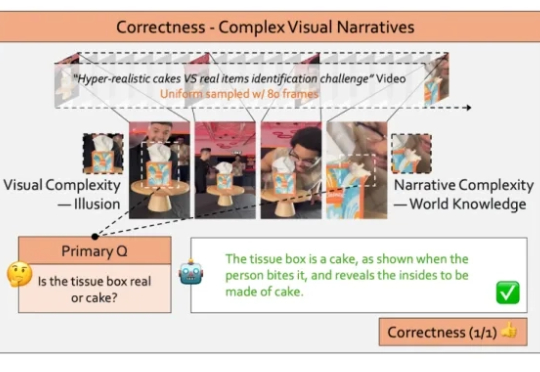
视频大型语言模型(Video LLMs)的发展日新月异,它们似乎能够精准描述视频内容、准确的回答相关问题,展现出足以乱真的人类级理解力。
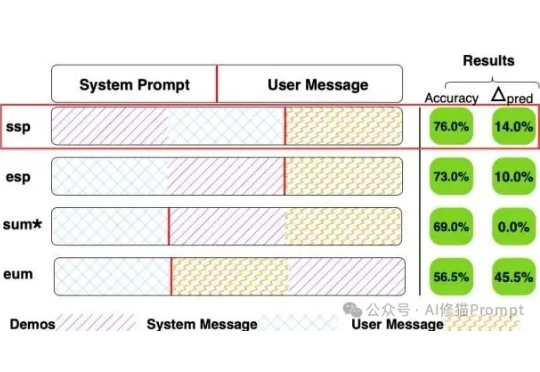
上下文学习(In-Context Learning, ICL)、few-shot,经常看我文章的朋友几乎没有人不知道这些概念,给模型几个例子(Demos),它就能更好地理解我们的意图。但问题来了,当您精心挑选了例子、优化了顺序,结果模型的表现还是像开“盲盒”一样时……有没有可能,问题出在一个我们谁都没太在意的地方,这些例子,到底应该放在Prompt的哪个位置?

近期,随着OpenAI-o1/o3和Deepseek-R1的成功,基于强化学习的微调方法(R1-Style)在AI领域引起广泛关注。这些方法在数学推理和代码智能方面展现出色表现,但在通用多模态数据上的应用研究仍有待深入。
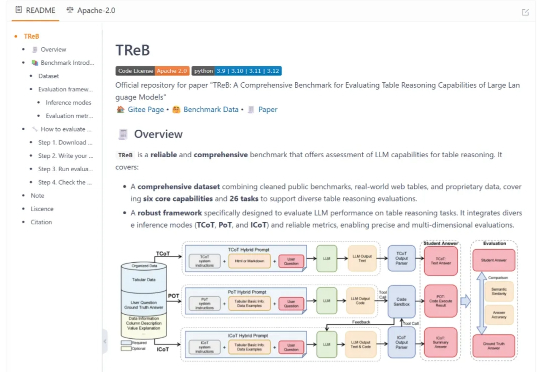
7 月 26 日,在 WAIC 2025 世界人工智能大会上,中国移动九天人工智能研究院全面开源九天结构化数据大模型 “数据 - 模型 - 测评” 三位一体的完整模型体系,包括了结构化数据体系、TReB 标准化测评框架、支持微调及推理全流程模型。